1. Motivation(研究动机)
- 现有方法的问题:当前视觉表示学习与密集感知的主流路线多为判别式预训练(监督、对比、自举、自编码等)或任务专用架构;SOTA 的 segmentation / metric depth / surface normal 往往依赖专门模块、专用 loss 与大量标注,且许多 depth 方法在训练或推理阶段依赖相机内参以缓解尺度歧义。与此同时,图像/视频生成模型虽展现出“能画就能懂”的迹象,但既有工作要么难以稳定输出可解码、可打分的标准格式,要么通过大改架构与全量微调在单一任务上追 SOTA、却牺牲跨任务与生成通用性。
- 本文要回答的问题:以大规模图像生成预训练得到的模型(Nano Banana Pro, NBP)是否已经在内部形成了足够强的通用视觉表征?能否像 LLM 那样,用轻量 instruction tuning 把“会生成”对齐为“会按指令输出可评测的感知结果”,并在不牺牲图像生成能力的前提下,在多个 2D/3D 基准上达到或超越零样本专家模型?
- 为何值得研究:若成立,意味着 generative vision pretraining 可扮演类似 NLP 中 generative pretraining 的角色,图像生成可成为统一多种视觉任务 I/O 的“通用接口”,推动 Foundation Vision Model 在生成与理解上的范式收敛。
2. Idea(核心思想)
- 核心洞见(1–3 句):把各类视觉任务的输出空间参数化为 RGB 图像(分割彩图、深度的伪彩色编码、法线与 RGB 的直连映射等),从而把 dense perception 重构为条件图像生成;再用极低比例的视觉任务数据混入 NBP 原有训练混合,对模型做 instruction tuning,使其严格遵循 prompt 中给定的“颜色—语义/几何”约定,输出可被确定性解码为 masks、metric depth、normals 等,以便在标准 benchmark 上定量评估。
- 与常见路线的本质区别:对比“为每类任务设计 head + 专用 loss + 往往依赖内参”的专家式判别模型,本文不引入任务专用解码头;对比“为单任务大改生成架构并全量微调”的方法,本文强调共享权重、以 prompt 切换任务,并通过混合原始生成数据保持生成先验。
3. Method(方法)
3.1 总体框架
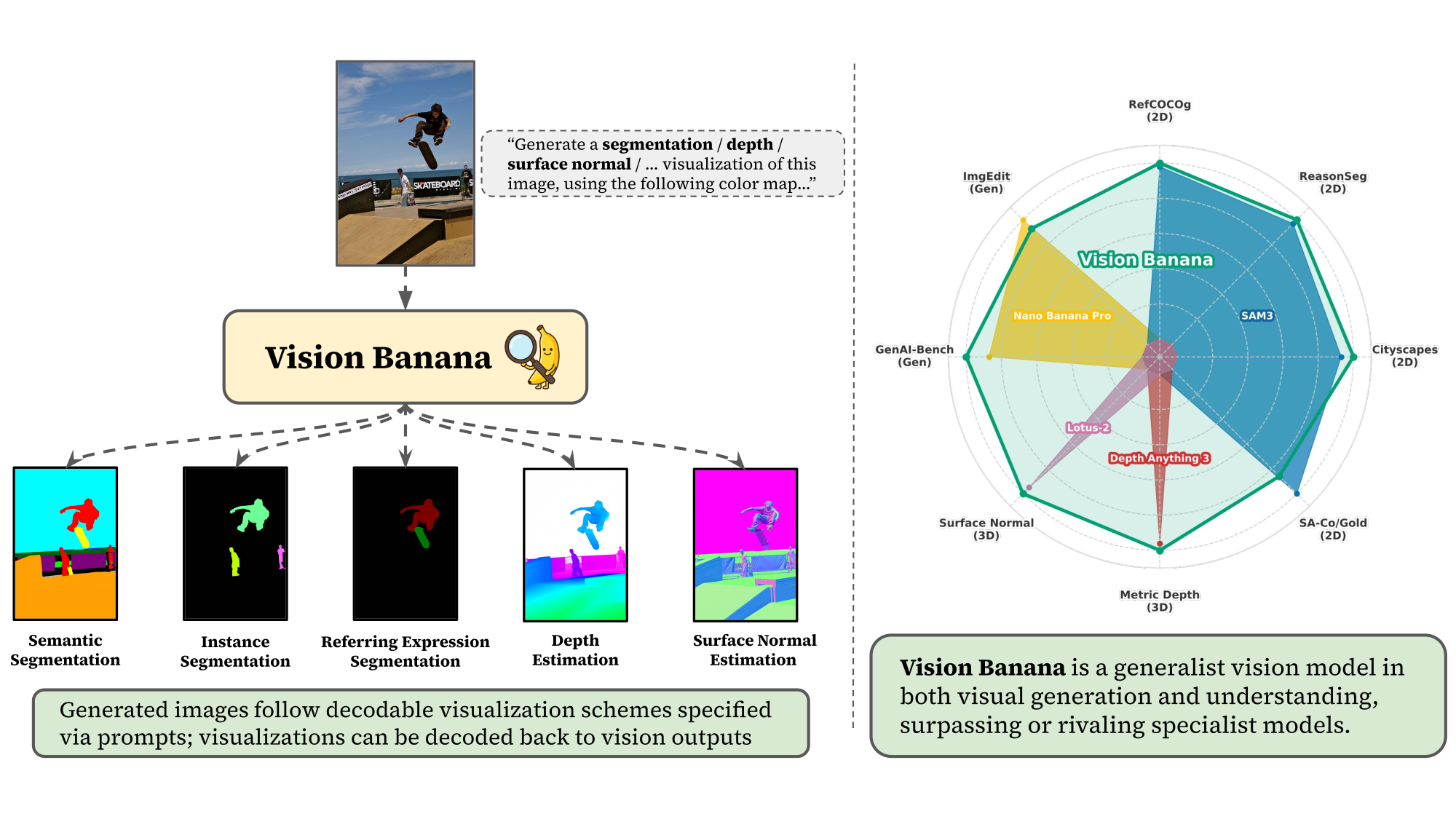
Figure 1 解读:示意图概括了本文范式:用户以自然语言指令要求模型输出特定可视化格式(分割/深度/法线等),Vision Banana 生成遵循该格式的 RGB 图;这些 RGB 可视化再按规则反解为可用于标准指标的 perception 输出。图面同时强调模型在多种 2D/3D 任务上与专家模型可比或更优,且仍保留通用图像生成能力。
Instruction tuning 与数据混合:在 NBP 的原始图像生成训练混合中加入少量按“可逆可视化协议”准备好的视觉任务数据;混合比例刻意保持很低,使对齐主要发生在“输出格式与指令跟随”,而不破坏生成先验。正文强调评估用的 benchmark 不参与 instruction tuning 数据构造,以体现真正的 zero-shot transfer。
评测解码:例如语义分割中,prompt 指定类别与 RGB(或十六进制)对应关系,评测时按颜色聚类/匹配将像素指派到类别;实例分割因实例数未知,采用每类一次推理,由模型为同类实例分配不同颜色,再对相似颜色像素做聚类得到实例 mask。
3.2 输出参数化(按任务)
语义分割(Semantic segmentation):prompt 描述“每个类别对应的颜色”,可用自然语言、JSON 映射、RGB 元组或 hex;类别可以是开放词汇字符串。模型输出彩色分割可视化图。

Figure 2 解读(摘录):展示模型在不同 prompt 风格下输出语义分割彩图的能力(如 JSON 颜色表或自然语言逐类指定 RGB)。细粒度结构(如胡须等)可被着色保留,说明生成式路由仍能刻画高频空间细节。

Figure 2 解读(续):另一组示例强调“开放类别描述 + 明确颜色契约”的可行性;评测侧只需依据 prompt 中声明的编码恢复 per-pixel 语义。
实例分割(Instance segmentation):每次仅针对一个类别请求实例 mask,模型为不同实例分配不同颜色;后处理对颜色做阈值化聚类。下图给出实例级着色的代表性可视化。

Figure 3 解读(摘录):可见模型能在语言指令下区分同类的多个实例,并用显著不同的纯色区域表示各实例;该类任务对“实例数未知”更友好地采用逐类推理策略。

Figure 3 解读(续):展示对细粒度名词(如价签、蒜瓣等)进行实例着色的效果,体现语言—像素对齐与颜色分配稳定性。
指代表达分割(Referring expression segmentation):输入图像 + 指代表述,输出二值/多区域彩图。模型依赖生成式预训练带来的多模态语义与推理能力,在 RefCOCOg、ReasonSeg 等基准上取得强结果。定性示例如下。


Figure 4 解读(摘录):示例覆盖外观描述、动作描述、非常规指代与多语言文本等;模型需要同时理解语言细微差别与图像内容关系,再把理解结果落实为可解码的颜色区域。
Metric depth(单目度量深度):将度量深度 先经幂变换弯曲到 ,再沿 RGB 立方体棱边的分段线性路径映射为伪彩色 RGB,训练时对 GT depth 应用该映射作为 RGB 监督目标,推理时反演回 metric depth。为增强对颜色方案的鲁棒性,训练中加入 Plasma、Inferno、Viridis、灰度等替代 colormap 增广。
关键公式(Barron power transform + 归一化;正文式 (1)):
实验中固定 ,。弯曲后的 再用于沿 RGB cube 路径插值生成 false-color depth image;映射设计为双射(严格可逆),从而支持定量评测。
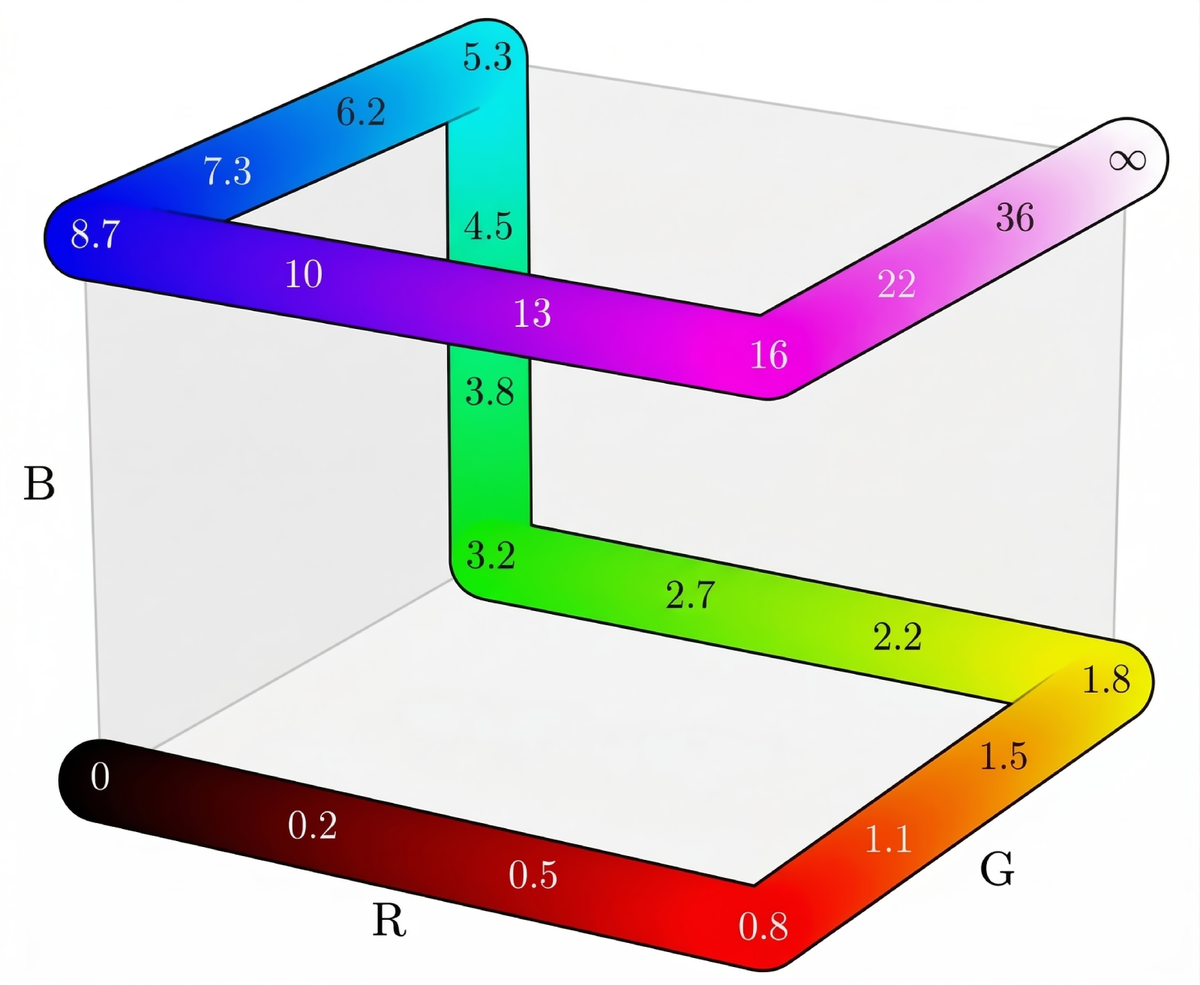
Figure 5 解读:可视化“幂变换弯曲距离 → 沿 RGB 立方体棱边遍历”的编码方式,并在若干颜色上叠加对应的米制深度读数,帮助理解近距/远距在颜色上的分配;可逆性是 metric depth 能通过生成 RGB 再解码回物理尺度的关键。
Surface normal(表面法线):采用相机坐标系右手系 ,将单位法线分量直接映射到 RGB(如向左、向上、朝向相机分别对应特定色调);与 RGB 空间天然对齐,编码相对直接。
3.3 NBP backbone 简介
Nano Banana Pro(NBP)是 Google 的大规模图像生成基础模型,作为“已具备强生成先验”的底座;正文侧重方法学与评测,未展开其网络结构、参数量或预训练数据细节。Vision Banana 即在其上按前述混合策略做 instruction tuning。
3.4 训练目标与实现层面说明
正文强调方法不引入任务专用损失项的新形式化表述,而是延续基础生成模型的学习目标,通过数据混合 + 指令格式化完成对齐;因此不存在单独写出的、与任务一一对应的闭式 surrogate loss。除深度的 RGB 双射映射公式外,论文未给出新的统一 training objective 方程。具体优化器、学习率、batch size、训练步数、硬件类型等超参,正文未披露。
3.5 直觉段落:为何 “image generation = generalist vision learner”
生成模型在拟合高维视觉分布时,需要同时编码物体、场景几何、尺度与语义关系;当输出被约束为“可解码的 RGB 可视化协议”时,这些内部因素会在像素级合成中被强制落实为可检验的结构。与判别式模型常用单峰回归、需额外机制处理多模态歧义不同,生成式建模更自然地学习完整条件分布,对某些本质多解的任务(深度尺度、模式选择)可能更契合;再辅以大规模预训练带来的“世界知识”与物体尺度先验,使得仅用合成深度与网络图像衍生标注也能在真实基准上泛化。最后,输出仍是 RGB 图像这一点使视觉对齐与原始图像生成目标同域,利于在极少任务数据下保留生成能力。
4. Experimental Setup(实验设置)
4.1 数据与任务覆盖
- Instruction tuning 数据来源:2D 侧使用内部模型标注的网络图像;3D 侧使用渲染引擎得到的合成数据(正文声明 metric depth 仅来自仿真合成,零真实世界深度训练);并明确不包含任何评估基准的训练划分。
- 2D 评测:Cityscapes val(mIoU)、SA-Co/Gold(,论文对 Vision Banana 在 500 条随机子集上评测以节省算力)、RefCOCOg UMD val(cIoU)、ReasonSeg val(gIoU;与 MLLM 组合,文中为 Gemini 2.5 Pro)。
- 3D 评测:单目 metric depth 覆盖 NYU Depth v2、iBims1、ETH3D、DIODE-Indoor、KITTI、nuScenes;surface normal 覆盖 NYUv2、DIODE-indoor、ScanNet、Virtual KITTI 2。
- 生成能力评测:GenAI-Bench(text-to-image 人类偏好胜率)、ImgEdit(image editing 人类偏好胜率)。
4.2 Baselines(代表性)
- 分割:SAM 3、DINO-X、APE-D、OpenSeeD、X-Decoder、OWLv2、Gemini 2.5、以及若干 MLLM 配对方法(HyperSeg、X-SAM、LISA、SegZero、RSVP 等,按各子表区分 zero-shot / non-zero-shot)。
- 深度:DepthLM-7B、Depth Anything v3、Depth Pro、UniK3D、MoGe-2 等(各方法对相机内参依赖情况在表中勾选)。
- 法线:Marigold、DSINE、StableNormal、Lotus-2-Normal 等。
4.3 指标
- 分割:mIoU、cIoU、gIoU、(按数据集定义)。
- 深度:(越高越好)、AbsRel(越低越好)。
- 法线:平均/中位角误差(度,越低越好)。
- 生成:相对 NBP 的人类评测 win rate。
4.4 训练配置
论文未给出具体硬件(如 TPU/GPU 型号与数量)、全局 batch size、学习率、训练步数、优化器细节或可复现随机种子;仅定性描述为低比例混合的 instruction tuning。
5. Experimental Results(实验结果)
5.1 总览(Table 1)
| 能力 | 基准(指标) | Vision Banana | 最强对比方法(文中) |
|---|---|---|---|
| 2D | RefCOCOg UMD val(cIoU ) | 0.738 | 0.734(SAM3 Agent) |
| 2D | ReasonSeg val(gIoU ) | 0.793 | 0.770(SAM3 Agent) |
| 2D | Cityscapes val(mIoU ) | 0.699 | 0.652(SAM3) |
| 2D | SA-Co/Gold( ) | 0.540* | 0.552(DINO-X) |
| 3D | Metric depth:4 数据集均值( ) | 0.929 | 0.918(Depth Anything 3) |
| 3D | Surface normal:4 数据集均值(mean angle ) | 18.928° | 19.642°(Lotus-2) |
| 生成 | GenAI-Bench(win rate ) | 53.5% | 46.5%(NBP) |
| 生成 | ImgEdit(win rate ) | 47.8% | 52.2%(NBP) |
*SA-Co/Gold:在 500 条随机查询子集上评测。
5.2 分割细节(Table 2)
- Cityscapes val mIoU:Vision Banana 0.699,相对 SAM 3(0.652)提升 4.7 个点。
- SA-Co/Gold (zero-shot):Vision Banana 0.540*,低于 DINO-X(0.552),但高于 Gemini 2.5(0.461)等与开放词汇检测相关的方法;非零样本上 SAM 3 可达 0.661。
- RefCOCOg UMD val cIoU:Vision Banana 0.738,高于 SAM 3 + Gemini 2.5 Pro(0.734)。
- ReasonSeg val gIoU(搭配 Gemini 2.5 Pro):Vision Banana 0.793,高于 SAM 3 Agent(0.770)。
5.3 Metric depth(Table 3 精确数字)
跨六数据集平均:Vision Banana ,AbsRel (对比行内给出的 UniK3D / MoGe-2 等)。
分数据集(Vision Banana 列):
| 数据集 | AbsRel | |
|---|---|---|
| NYU | 0.948 | 0.081 |
| iBims1 | 0.934 | 0.078 |
| ETH3D | 0.935 | 0.103 |
| DIODE-Indoor | 0.917 | 0.108 |
| KITTI | 0.915 | 0.107 |
| nuScenes | 0.643 | 0.219 |
与 Depth Anything 3 的可比均值:在 NYU + ETH3D + DIODE + KITTI 四个数据集上,Vision Banana 平均 ,高于 DA3 的 0.918(脚注在文中给出)。
定性:下图截取论文 Fig. 6 网格中的一行(NYU/ETH3D 样本),可见输入 RGB、模型生成的深度伪彩图、以及用解码深度重建的场景视角。




Figure 6 解读:左两列对应原图与 Vision Banana 生成的深度可视化;解码后与内参结合可渲染新视角(右两列)。注意:预测深度本身不依赖内参,内参仅用于点云可视化/重建。
野外“vibe test”:Fig. 7 报告金阁寺附近手机照片一点深度为 13.71 m,Google Maps 测距 12.87 m,该点 AbsRel 约 0.065。



Figure 7 解读:展示真实手机拍摄场景下的度量深度估计与外部测距对照,说明模型不仅限于实验室基准分布。
5.4 Surface normal(Table 4)
室内三数据集平均:Vision Banana mean 15.549° / median 9.300°,为表中最低(对比 Marigold、DSINE、StableNormal、Lotus-2)。分数据集上,Vision Banana 在 NYUv2 mean 17.778°、DIODE-indoor mean 13.818°、ScanNet mean 15.052°;户外 Virtual KITTI 2 mean 29.063°(Lotus-2 在 VKitti 上数值更优,但论文指出室内平均更强且定性细节更丰富)。
与 Lotus-2 的对比(节选一行):



Figure 8 解读:在同一场景上,Vision Banana 的法线图在细粒度结构与边缘清晰度上更占优;论文注明 Lotus-2 结果来自其 Hugging Face demo。
5.5 是否牺牲图像生成能力(证据)
- 定量:GenAI-Bench 上 Vision Banana 对 NBP 的胜率为 53.5%;ImgEdit 上为 47.8%(NBP 52.2%,略占优)。整体表述为基本保持、互有胜负而非单向退化。
- 定性:Fig. 9/10 给出 text-to-image 与 image editing 的并排样本;下面摘录一组。



Figure 9 解读:在 GenAI-Bench 风格 prompt 下,Vision Banana 与 NBP 的生成结果高度接近,用于支撑“指令微调未明显损毁文生图行为”。


Figure 10 解读:ImgEdit 提示下的编辑结果并排对比,二者视觉质量与遵从度相近,体现编辑能力大体保留。
5.6 消融与混合策略(正文层面)
- 混合比例:强调 vision 数据在整体训练混合中占比非常低以保护生成先验,但未给出具体数值。
- 任务覆盖扩展、多视角/视频输入等留作未来工作。
5.7 Limitations(作者讨论)
- 算力与成本:相比轻量专家模型,运行大型图像生成器计算开销显著更高,需要加速与降本策略才利于广泛部署。
- 评估范围:当前聚焦单目图像输入;向多视角、视频生成器扩展仍待探索。
- 与 LLM 的协同:跨模态推理可进一步与更强语言模型深度集成。
5.8 结论主张
作者认为结果支持:图像生成预训练已使模型成为通用视觉学习者;图像生成可像文本生成在 NLP 中那样,成为计算机视觉的统一接口,并暗示领域可能进入以 generative vision pretraining 为核心的范式转移。
代码与可复现性:经检索 GitHub 与项目页 vision-banana.github.io,未找到 Vision Banana / 本文方法的官方开源训练或推理代码仓库;相关检索多为社区围绕 Nano Banana API 的示例工程,不能视为本文实现。代码搜索未找到开源实现(Google 内部/未发布代码概率高)。
Project page 交互 demo:页面提供 semantic/instance/referring segmentation、metric depth、surface normal 等 hover/tap 揭示预测结果的交互示例,展示指令文本与彩色输出格式(可作为定性参考)。