Going Down Memory Lane: Scaling Tokens for Video Stream Understanding with Dynamic KV-Cache Memory
Authors: Vatsal Agarwal, Saksham Suri, Matthew Gwilliam, Pulkit Kumar, Abhinav Shrivastava Affiliations: University of Maryland, College Park, TikTok arXiv: 2602.18434 Project Page: vatsalag99.github.io/memstream GitHub: vatsalag99/MemStream
1. Motivation (研究动机)
这篇论文关注的是 streaming video understanding / streaming VideoQA。现有方法(尤其是 ReKV 一类 KV-cache memory 方法)已经能在线编码视频并在用户提问时做检索式问答,但仍有两个根本瓶颈:
- 每帧 token 太少:为了控制显存和上下文长度,现有方法通常强行压低 tokens per frame,这会丢掉细粒度空间细节;
- token 变多时反而更差:作者发现,当把 token budget 提高到更密集的设定后,现有 KV-cache 方法并不会自然变强,反而因为编码与检索机制失衡,出现 retrieval bias 和 redundancy 爆炸。
论文的核心问题是:如何在不重新训练 Video-LLM 的前提下,把更密集的 frame token 真正转化成更好的流式视频理解能力?
作者通过分析发现,ReKV 一类方法在高 token budget 下会出现:
- query-frame similarity 随时间变大,导致系统更偏向检索视频后段;
- sliding-window attention 变得更高熵、更分散,难以聚焦到关键帧;
- key representation 更冗余,大量局部相似 patch 反而污染了检索信号。
因此,这篇工作的价值不只是提出一个更好的方法,而是指出:长视频流式理解的问题不是“token 不够”,而是“高 token 的编码和检索没有被正确组织”。
2. Idea (核心思想)
MemStream 的核心思想可以概括成两句话:
- 编码阶段:不要用 dense sliding-window attention 直接吞下所有高密度 token,而是用 Adaptive Key Selection (AKS) 把局部冗余 patch 稀疏掉,保留真正新颖的信息;
- 检索阶段:不要只信任内部 KV 检索,而是把 internal retrieval 与 external retrieval(CLIP / PECore 等视觉模型)做 training-free mixture-of-experts 融合,用 RRF 提升稳定性和细粒度定位能力。
它与先前方法最根本的区别是:MemStream 不是继续压缩 token 数量本身,而是重新设计“哪些 token 该进入 attention、哪些检索信号该被融合”。
3. Method (方法)
3.1 Overall framework
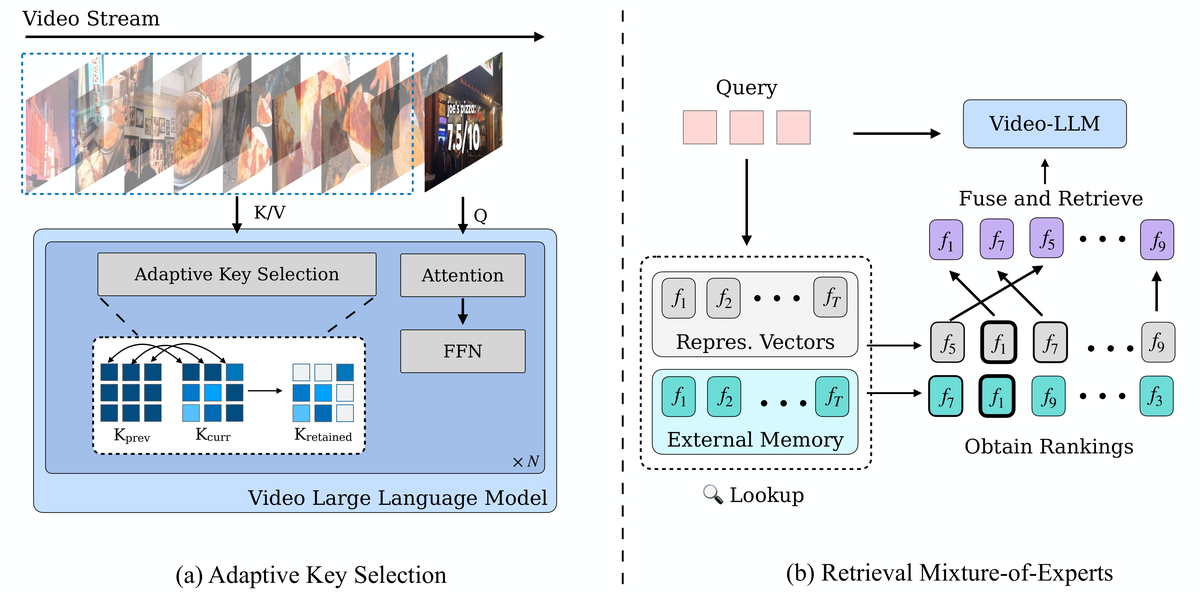
Figure 1 解读: Figure 1 左侧是编码阶段:视频流逐帧进入 Video-LLM,在每层 sliding window 中执行 Adaptive Key Selection,只保留当前帧里对历史最不冗余、最“新”的 patch token 参与注意力计算,同时完整 key 仍被存进 KV-cache memory。右侧是问答阶段:模型先得到内部 representative vectors,再引入 external memory(如 CLIP / PECore 特征)一起做排序,然后使用 training-free 的 re-rank / fusion 得到最终检索帧,再送入 Video-LLM 回答问题。整套系统由此被拆成“更稳的编码 + 更强的检索”两部分。
3.2 为什么高 token budget 会伤害现有方法

Figure 2 解读: Figure 2 上半部分展示 query-frame score:当 tokens per frame 从 64 增加到 256 后,相似度曲线明显向视频后段抬升,说明检索偏向越靠后的帧;下半部分展示 key self-similarity matrix:高 token 设定下矩阵更亮、更大块,说明不同帧/patch 之间冗余更强。作者据此认为,直接把更多 token 塞进 sliding-window,并不会带来更好的辨别性,反而会造成“局部相似信息的放大”。
3.3 Adaptive Key Selection (AKS)
MemStream 在编码阶段的核心模块是 AKS。设 layer 的滑动窗口为:
作者不再让当前帧的所有 patch token 都参加 attention,而是对相邻帧 key 特征 和 做 patch-wise cosine similarity,然后保留当前帧中 top-k 最不相似 的 patch。直觉上,这相当于只留下相对历史真正新增的局部信息。
需要注意的是:
- AKS 的稀疏化主要发生在 attention 计算 里;
- 论文明确说 完整 key features 仍然会存到 KV-cache,因此并不是简单暴力丢弃。
这一点很重要,因为它让模型既能减少局部冗余,又不至于完全丢失可检索的细节信息。
3.4 Internal retrieval 与 frame representative vectors
MemStream 延续了 ReKV 一类方法的检索思路:先在线编码视频,然后在问答阶段用问题去检索缓存中的代表帧特征。
对于每一帧,作者定义 frame representative vector:
对于问题 token,也做平均池化得到查询向量:
然后用它们做 cosine similarity,得到 layer-wise query-frame score,再从每层取 top-k frame features。这个 internal retrieval 能利用 KV feature 中已经累积的上下文信息,但缺点是不同 layer 的检索质量差异很大,有些层能找到 clue frame,有些层则几乎完全失败。
3.5 Retrieval Mixture-of-Experts
为了补 internal retrieval 的不稳定,作者引入外部视觉模型做 retrieval expert。具体做法是:
- 用 external vision-language encoder 提取每帧视觉特征 ;
- 用文本编码器得到问题向量 ;
- 计算 external query-frame score;
- 再与 internal ranking 做 late fusion。
作者没有采用直接拼接 embedding 或直接拼接分数,而是用了 Reciprocal Rank Fusion (RRF):
其中 。这个公式的好处是:
- 它不要求不同 embedding space 的距离可以直接比较;
- 只要两个专家对某些帧都给出高排名,这些帧就会被强化;
- ranking 差但偶然高分的噪声点不会过度主导结果。
论文结果表明,这种 training-free MoE retrieval 比单独 internal 或 external 都更稳。
3.6 Pseudocode(官方仓库已建,但实现尚未公开完整代码)
截至 2026-03-09,官方 GitHub 只有 README,显示“Code Coming Soon”。以下伪代码基于论文算法描述整理,而不是作者源码逐行还原。
组件 A:Adaptive Key Selection
# Algorithm: Adaptive Key Selection (AKS)
# Input: current-frame keys K_curr, previous-frame keys K_prev, keep budget k
# Output: selected patch tokens from current frame
def adaptive_key_selection(K_prev, K_curr, k):
# patch-wise cosine similarity between aligned spatial patches
sim = cosine_similarity_per_patch(K_prev, K_curr)
# keep the least similar patches, i.e. the most distinctive ones
idx = topk_lowest(sim, k)
K_keep = K_curr[idx]
return K_keep, idx组件 B:Streaming encoding with sparse sliding-window attention
# Algorithm: Sparse streaming encoding
# Input: video stream frames, window size w
# Output: KV-cache memory and frame representatives
def encode_stream(video_stream, model, w, k):
kv_cache = []
repr_vectors = []
for frame_t in video_stream:
K_t, V_t = model.encode_frame(frame_t, kv_cache[-w:])
if has_previous_frame():
K_sel, idx = adaptive_key_selection(K_prev, K_t, k)
O_t = sparse_sliding_window_attention(K_sel, V_t, kv_cache[-w:])
else:
O_t = full_attention(K_t, V_t, kv_cache[-w:])
kv_cache.append((K_t, V_t)) # full keys are still stored
repr_vectors.append(mean_pool(K_t))
K_prev = K_t
return kv_cache, repr_vectors组件 C:External retrieval expert
# Algorithm: External frame retrieval
# Input: question Q, stored frames f_1 ... f_T, external encoder E
# Output: ranking over frames
def external_retrieval(question, frames, encoder):
q = encoder.text(question)
x = [encoder.visual(f) for f in frames]
scores = [cosine_similarity(q, x_t) for x_t in x]
return rank_frames(scores)组件 D:Mixture-of-Experts retrieval with RRF
# Algorithm: Retrieval MoE with reciprocal rank fusion
# Input: internal ranking R_int, external ranking R_ext
# Output: fused ranking
def rrf_fusion(R_int, R_ext, k=60):
fused = {}
for t in all_frames(R_int, R_ext):
fused[t] = 1.0 / (k + rank_of(R_int, t)) + 1.0 / (k + rank_of(R_ext, t))
return sort_by_value_desc(fused)3.7 Code-to-paper mapping table
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Project entry | README.md | Paper / project links only |
| Adaptive Key Selection | 未公开 | 代码尚未发布 |
| Internal retrieval | 未公开 | 代码尚未发布 |
| External retrieval + PECore / CLIP | 未公开 | 代码尚未发布 |
| RRF fusion | 未公开 | 代码尚未发布 |
4. Experimental Setup (实验设置)
4.1 Datasets
作者同时评测 offline 与 online 两类 benchmark:
- Offline Benchmarks
- CG-Bench(multiple-choice subset)
- LVBench
- VideoMME(只用 Long subset)
- Online Benchmarks
- RVS-Ego
- RVS-Movie
附录中还给出 dataset statistics,但正文主结果集中在上述五个 benchmark 上。
4.2 Model / Token budget / Retrieval setting
- 主要 backbone:Qwen2.5-VL-7B
- 也在以下模型上做实验:
- LLaVA-OneVision
- Qwen2-VL-7B
- 视频流处理默认 0.5 FPS(follow ReKV)
- token budget 约为 256 tokens / frame
- 对于 Qwen2.5-VL,实际 token budget 会因 dynamic resolution 略有浮动,最小约 200 tokens / frame
- sliding-window token 上限:17K tokens
- retrieval size:64 frame features(相当于代表 128 帧)
4.3 External retrieval experts
- CLIP ViT-L
- PECore ViT-L
论文把这两个外部模型作为 retrieval experts,与内部检索结果融合。
4.4 Train / Inference
MemStream 是 training-free 方法:
- 不需要额外微调 Video-LLM;
- 不需要训练 reward model 或 retrieval model;
- 主要是 inference-time 的编码与检索重设计。
5. Experimental Results (实验结果)
5.1 Offline VQA 主结果
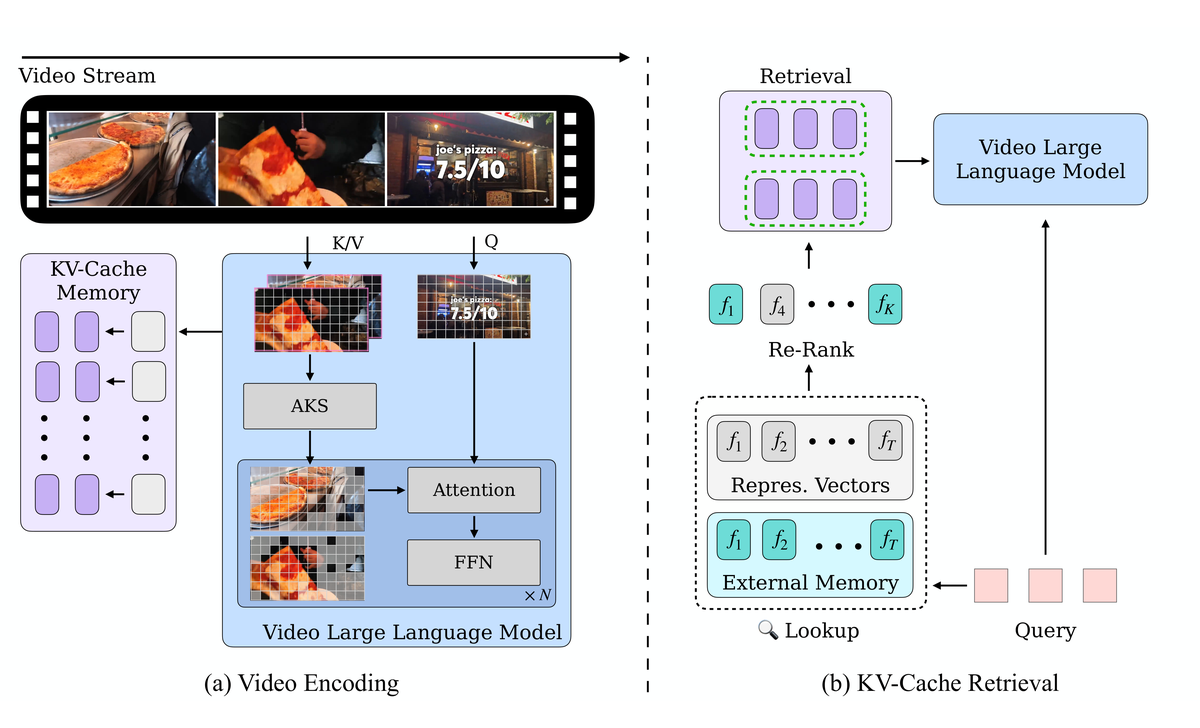
Figure 3 解读: Figure 3 用概念图总结了 MemStream 的核心卖点:左边显示在线编码时,模型并不是把视频重新跑很多遍,而是一次性把信息写进 KV-cache;右边显示问答时,不仅用内部 representative vector 做检索,还结合外部 memory 重新排序。它对应了论文主结果中的两个提升来源:编码质量提升来自 AKS,检索质量提升来自 retrieval MoE。
论文最核心的主表如下:
| Method | CG-Bench | LVBench | VideoMME (Long) |
|---|---|---|---|
| ReKV | 36.17 | 39.64 | 51.78 |
| MemStream (AKS, Internal) | 41.63 | 43.77 | 54.56 |
| MemStream (Full, External) | 41.77 | 45.84 | 50.89 |
| MemStream (AKS, MoE) | 44.19 | 48.10 | 54.22 |
对比 ReKV,最佳 MemStream(AKS + MoE)提升为:
- CG-Bench +8.02
- LVBench +8.46
- VideoMME(Long) +2.44
这与摘要里的 “+8.0 / +8.5 / +2.4” 完全一致,只是摘要做了四舍五入。
值得注意的是:
- 在 CG-Bench / LVBench 上,MoE 检索明显优于纯 internal retrieval;
- 在 VideoMME 上,纯 external retrieval 会退化,这说明 holistic long-video understanding 不能仅靠关键帧语义相似度,还需要 internal KV 的上下文信息;
- 因此,MoE 的价值不只是“加一个外部模型”,而是让 internal 与 external 在不同 benchmark 上互补。
5.2 StreamingVQA 结果
| Method | RVS-Ego Acc / Score | RVS-Movie Acc / Score | Video Enc. | Latency | GPU | KV-cache |
|---|---|---|---|---|---|---|
| ReKV | 64.2 / 4.00 | 61.6 / 3.65 | 8.47 FPS | 2.8s | 29 GB | 11.1 GB/h |
| MemStream (AKS, Internal) | 67.8 / 4.01 | 59.1 / 3.60 | 8.50 FPS | 2.6s | 29 GB | 11.1 GB/h |
| MemStream (AKS, MoE) | 67.4 / 4.01 | 59.7 / 3.60 | 8.68 FPS | 2.6s | 32 GB | 11.1 GB/h |
在在线问答场景里,MemStream 的结论更 nuanced:
- 在 RVS-Ego 上,MemStream 优于 ReKV;
- 在 RVS-Movie 上,ReKV 仍略强,论文认为可能是压缩过于激进;
- 但 MemStream 维持了几乎相同的延迟和可控显存,说明它的收益来自“更聪明的压缩”,而不是额外算力。
5.3 Encoding / Retrieval / Fusion 消融
(1) Encoding strategy
论文对 patch-wise 与 frame-wise compression 做了系统比较:
- AKS 在 LVBench = 43.77、VideoMME = 54.56 上最好;
- patch-wise token merging(B.1)在 CG-Bench 上略强(42.18),但整体不如 AKS 稳;
- 说明“选择最不相似 patch”比“静态采样”或“普通 token merging”更适合 streaming dense video。
(2) Retrieval strategy
| Retrieval Strategy | External Model | CG-Bench | LVBench | VideoMME |
|---|---|---|---|---|
| Internal Only | — | 41.63 | 43.77 | 54.56 |
| External Only | CLIP | 42.39 | 47.45 | 53.67 |
| External Only | PECore | 43.21 | 47.19 | 52.33 |
| MoE (Ours) | CLIP | 43.84 | 47.39 | 55.22 |
| MoE (Ours) | PECore | 44.19 | 48.10 | 54.22 |
结论很明确:
- 内部检索最擅长 VideoMME 这类 holistic 任务;
- 外部检索最擅长 CG-Bench / LVBench 这类更依赖关键局部语义定位的任务;
- MoE 是最稳的折中。
(3) Fusion strategy
| Fusion Method | CG-Bench | LVBench | VideoMME |
|---|---|---|---|
| L2-Concat | 43.57 | 48.03 | 52.89 |
| RRF (Ours) | 44.19 | 48.10 | 54.22 |
RRF 在三个 benchmark 上都优于简单 L2-Concat,说明 rank-level fusion 比 embedding-level fusion 更鲁棒。
5.4 Qualitative results
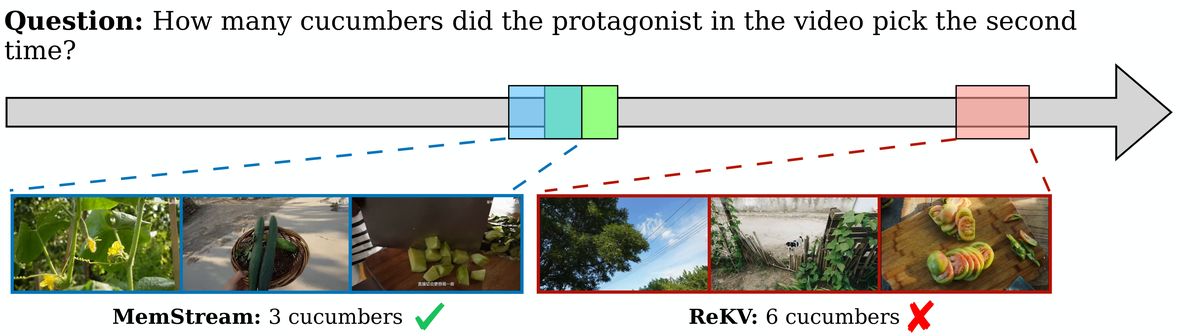
Figure 4 解读: Figure 4 对比了 ReKV 与 MemStream 的检索结果和回答结果。绿色是真正的 clue segment,红色是 ReKV 检索到的帧,蓝色是 MemStream 检索到的帧。可以看到 MemStream 检索到的帧更接近 ground-truth segment,因此回答也更贴题;而 ReKV 容易受后段帧或无关高相似背景影响,导致答错或答偏。这个定性图与作者关于“higher token budget induces temporal bias”的分析是呼应的。
5.5 Limitations / 结论
论文没有单独列 formal limitations section,但从实验可以推断出几个边界:
- 在某些 streaming QA benchmark(如 RVS-Movie)上,过强压缩仍可能伤害结果;
- 外部检索不是总能提升,尤其在 holistic video understanding 上可能反而带偏;
- 官方仓库虽已建立,但截至 2026-03-09 代码还未公开完整实现,因此可复现性暂时受限。
整体而言,MemStream 的贡献非常清楚:
- 它指出高 token budget 本身并不会自动带来更好的流式视频理解;
- 它通过 AKS + MoE retrieval,把“更多 token”真正转化成“更好的 memory 与 retrieval”;
- 它在 offline long-video benchmark 上明显优于 ReKV,是 streaming VideoQA 方向里很有代表性的 training-free memory retrieval 工作。