E-VRAG: Enhancing Long Video Understanding with Resource-Efficient Retrieval Augmented Generation
Authors: Zeyu Xu*, Junkang Zhang*, Qiang Wang*, Yi Liu† (Honor Device Co., Ltd) Affiliations: 荣耀终端有限公司 Code: 未公开
1. Motivation (研究动机)
| 属性 | 值 |
|---|---|
| 标题 | E-VRAG: Enhancing Long Video Understanding with Resource-Efficient Retrieval Augmented Generation |
| 作者 | Zeyu Xu*, Junkang Zhang*, Qiang Wang*, Yi Liu† (Honor Device Co., Ltd) |
| 机构 | 荣耀终端有限公司 |
| 发表 | arXiv:2508.01546, 2025年8月 |
| 代码 | 未公开 |
| 关键词 | Video RAG, Long Video Understanding, VLM, Frame Retrieval, Query Decomposition |
1.1 问题背景
视觉语言模型 (VLM) 在长视频理解中面临两大瓶颈:
- 上下文窗口受限: 长视频包含数千帧,远超 VLM 的处理能力
- 计算成本高昂: 使用 7B 模型对 256 帧做 RAG 检索,检索阶段占总计算量的 约 80%
1.2 现有方法的效率-精度权衡
现有 Video RAG 方法的效率-精度权衡:
- Offline 方法 (如 Video-RAG): 预提取静态帧特征,复用性好但无法捕捉细粒度 query-frame 关系
- Online 方法 (如 FRAG, BOLT): 联合建模 query-frame 关系,精度高但计算开销大 (708-877 TFLOPs)
1.3 核心贡献
- 帧预过滤: 基于层次化查询分解 (Hierarchical Query Decomposition) + CLIP 相似度 + 帧间分组采样,在数据层面降低计算量
- 帧检索: 使用轻量 VLM (2B) 打分 + 基于帧间概率分布的全局分组检索策略,在模型层面降低计算量
- 多视角 QA: 多轮迭代问答 + 投票机制 + 提前终止,提升答案鲁棒性
- 整体效果: 计算量降低约 70%,四个 benchmark 上精度持平或超越 SOTA,无需额外训练
2. Idea (核心思想)

Figure 2 解读: E-VRAG 的整体工作流程包含三个阶段。(1) 帧预过滤阶段: 对查询进行层次化分解生成多层级 caption,通过 CLIP 计算帧相似度,再利用帧间相似性分组和逆变换采样 (ITS) 筛选出候选帧。(2) 帧检索阶段: 使用轻量 VLM 对候选帧打分,基于词表概率分布进行帧间分组,再用 ITS 采样获得最终检索帧。(3) 多视角 QA 阶段: 多轮迭代从不同视角回答问题,通过投票机制和提前终止策略确定最终答案。
E-VRAG 的核心思路可以概括为:先粗筛、再精检、最后多视角融合。它不是直接让大模型对所有帧做重检索,而是先通过便宜的语义匹配压缩候选集合,再用轻量 VLM 做二次筛选,最后通过多轮问答提升答案稳定性。
3. Method (方法)
3.1 帧预过滤 (Frame Pre-filtering)
3.1.1 层次化查询分解
将 query 分解为三个语义层级的 caption,使其更适合图像匹配:
- : 实体级 — 可直接描述的具体实体 (如猫、狗),直接转化为图像 caption
- : 知识级 — 抽象概念 (如”纽约”需转化为”摩天大楼和自由女神像的城市”),需 LLM 作为知识库转换
- : 因果级 — query 中的因果和逻辑关系,补充未直接提及的事件 caption
使用轻量 LLM (Qwen3-1.7B) 进行分解。
3.1.2 CLIP 相似度计算
其中 为总 caption 数量。此阶段计算效率高: query 分解可合并到单次 LLM 推理中,同一视频的图像特征可复用。
3.1.3 帧间相似性分组 + 逆变换采样 (ITS)
问题: Top-K 选择仅在帧特征高度可区分时有效,否则会导致时间邻近的冗余帧被过度采样。
解决方案: 基于帧间相似度的全局分布进行分组,确保组内相似度高、组间差异大。通过时间约束聚类: 仅时间相邻且相似的帧被分组。
对每个组 ,使用 ITS 基于累积分布函数的逆函数均匀采样:
其中 为组 的帧数, 为总待选帧数, 为组数。
3.2 帧检索 (Frame Retrieval)
3.2.1 轻量 VLM 打分
对预过滤后的帧,使用轻量 VLM (2B 参数) 逐帧评估与 query 的相关性:
- 输入: 帧 + query + 二元判断 prompt (yes/no)
- 输出: 使用 VLM 完整词表概率分布 作为相关性分数
两种打分策略:
- 仅使用
- 使用 (归一化)
3.2.2 帧间概率分组检索
与预过滤阶段类似,基于词表概率分布 的相似性进行分组 (概率分布相似的帧更可能相关且冗余),然后在每组内使用 ITS 采样检索帧。
3.3 多视角 QA (Multi-view QA)
单次 VLM 推理难以从大量检索帧中全面提取信息。多视角 QA 通过多轮迭代增强理解:
- 第 轮: VLM 生成推理 和答案 ,同时接收之前所有轮次的推理和答案作为补充上下文
- VLM 被要求从不同视角回答,明确说明使用的视角
投票 + 提前终止:
连续两轮答案一致时提前终止。票数相同时选择最后生成的答案。
3.4 伪代码
def e_vrag_pipeline(frames: list, query: str, M_pre: int = 128,
M_ret: int = 64, max_views: int = 2) -> str:
"""E-VRAG: Resource-Efficient Video RAG Pipeline."""
# Stage 1: Frame Pre-filtering
captions = light_llm(query, prompt_hierarchical) # hierarchical query decomposition
F_c = clip_text_encode(captions) # text features for captions
F_v = clip_vision_encode(frames) # visual features for frames
scores = avg_cosine_similarity(F_c, F_v) # CLIP similarity scores
groups = temporal_cluster(frames, scores) # group by inter-frame similarity
F_filtered = its_sample(groups, M=M_pre) # sample 128 frames via ITS
# Stage 2: Frame Retrieval (lightweight 2B VLM scoring)
prob_scores = []
for frame in F_filtered:
P_all = light_vlm(frame, query, "yes/no") # 2B VLM binary scoring
score = P_all["yes"] / (P_all["yes"] + P_all["no"])
prob_scores.append(score)
groups_r = cluster_by_prob(F_filtered, prob_scores) # group by prob distribution
F_retrieved = its_sample(groups_r, M=M_ret) # sample 64 frames via ITS
# Stage 3: Multi-view QA with voting and early stopping
answers = []
reasoning_history = []
for t in range(1, max_views + 1):
R_t, A_t = video_vlm(F_retrieved, query, reasoning_history, answers)
reasoning_history.append(R_t)
answers.append(A_t)
if t >= 2 and A_t == answers[-2]:
break # early stopping on consecutive agreement
# Majority voting (ties broken by latest answer)
best_answer = majority_vote(answers)
return best_answer4. Experimental Setup (实验设置)
4.1 实验设置
| 配置 | 值 |
|---|---|
| 硬件 | 8x NVIDIA A800 80G GPU |
| 候选帧数 | 256 (均匀采样) |
| 预过滤帧数 | 128 (50%) |
| 检索帧数 | 64 |
| 分辨率 | 动态分辨率 1 |
| 组数 | 26 |
| 打分策略 | 两词 (yes/no 归一化) |
| 多视角轮数 | 2 |
| 轻量 LLM | Qwen3-1.7B (查询分解) |
| 轻量 VLM | 2B (帧检索打分) |
| 答案 VLM | LLaVA-Video 7B |
| 训练 | 无需训练 (plug-and-play) |
5. Experimental Results (实验结果)
5.1 主实验: 与 SOTA 对比 (Table 1)
| 方法 | 检索模型 | 答案模型 | TFLOPs | 帧 | Video-MME | MLVU | LVB | NextQA |
|---|---|---|---|---|---|---|---|---|
| 基础方法 | ||||||||
| VideoChat2 | - | 7B | - | - | 39.5 | 44.5 | 39.3 | - |
| InternVL2 | - | 8B | 243 | 64 | 56.6 | 60.7 | 52.2 | 80.6 |
| LLaVA-Video | - | 7B | 177 | 64 | 64.3 | 69.5 | 61.2 | 83.8 |
| Offline RAG | ||||||||
| Video-RAG | 0.3B | 7B | - | 64 | - | 72.4 | 58.7 | - |
| AKS | 0.3B | 7B | 50+177 | 64 | 64.3 | 69.3 | 60.7 | 83.3 |
| Online RAG | ||||||||
| Frame-voyager | 7B | 7B | - | 8 | 57.5 | 65.6 | - | 73.9 |
| FRAG | 7B | 7B | 708+177 | 64 | 63.7 | 69.2 | 60.6 | 82.5 |
| BOLT | 7B | 7B | 708+177 | 64 | 64.6 | 70.3 | 62.2 | 83.2 |
| E-VRAG (ours) | 2B | 7B | 103+372 | 64 | 65.4 | 70.2 | 63.1 | 84.0 |
关键发现:
- E-VRAG 在 Video-MME (+0.8%), LVB (+0.9%), NextQA (+0.2%) 三个 benchmark 取得最高精度
- 计算量 (475 TFLOPs) 相比 Online 方法 (885 TFLOPs) 降低约 46%
- 使用单视角 QA 时 (280 TFLOPs),降低约 70% 仍保持良好性能

Figure 1 解读: 左图展示 Video RAG 各阶段计算量分布。Online baseline (BOLT) 总计算量约 800 TFLOPs,其中检索占约 80%。E-VRAG 通过帧预过滤节省约 80% 的检索计算量 (Save 80%),检索阶段本身节省约 85% (Save 85%),总体节省约 70%。右图展示 FLOPs vs. LVB 精度的 Pareto 前沿: E-VRAG 位于右上角,以最低计算成本实现了最高精度,相比 Online RAG 方法精度提升约 17% (Improve 17%) 同时计算量节省约 70% (Save 70%)。
5.2 消融实验
5.2.1 三阶段全局消融 (Table 2)
| 预过滤 | 检索 | 多视角QA | TFLOPs | Video-MME | MLVU | LVB | NextQA |
|---|---|---|---|---|---|---|---|
| - | - | - | 177 | 64.3 | 69.5 | 61.2 | 83.8 |
| ✓ | - | - | 178 | 64.5 | 69.2 | 60.4 | 83.5 |
| - | ✓ | - | 381 | 65.0 | 70.4 | 63.0 | 83.7 |
| ✓ | ✓ | - | 280 | 65.0 | 70.0 | 63.4 | 83.6 |
| ✓ | ✓ | ✓ | 475 | 65.4 | 70.2 | 63.1 | 84.0 |
分析:
- 仅预过滤 (对应 Offline RAG) 增益有限,适合粗筛
- 仅检索 (对应 Online RAG) 精度最好但计算量高 (381 TFLOPs)
- 预过滤 + 检索结合: 计算量降低约 30%,性能可比
- 三阶段完整: 最佳综合表现
5.2.2 查询分解消融 (Table 3)
| 查询分解 | Video-MME | MLVU | LVB | NextQA |
|---|---|---|---|---|
| - | 64.9 | 70.3 | 61.6 | 83.5 |
| ✓ | 65.0 | 70.0 | 63.4 | 83.6 |
查询分解对 LVB 提升最大 (+1.8%),因为 LVB 的查询较长且信息丰富,单一短 caption 难以匹配。
5.2.3 帧间分组检索消融 (Table 4)
| 预过滤分组 | 检索分组 | Video-MME | MLVU | LVB | NextQA |
|---|---|---|---|---|---|
| - | - | 62.5 | 69.4 | 60.1 | 82.6 |
| ✓ | - | 64.3 | 70.3 | 60.5 | 83.0 |
| ✓ | ✓ | 65.0 | 70.0 | 63.4 | 83.6 |
无分组 (Top-K) 精度最低 (甚至低于基础 LLaVA-Video),说明 Top-K 选择是冗余且不完整的。
5.2.4 多视角 QA 轮数消融 (Table 5)
| 视角数 | TFLOPs | Video-MME | MLVU | LVB | NextQA |
|---|---|---|---|---|---|
| 1 | 280 | 65.0 | 70.0 | 63.4 | 83.6 |
| 2 | 475 | 65.4 | 70.2 | 63.1 | 84.0 |
| 3 | 688 | 65.4 | 70.3 | 63.0 | 84.1 |
| 4 | 919 | 65.5 | 70.3 | 63.0 | 84.1 |
| 5 | 1168 | 65.5 | 70.3 | 63.2 | 84.1 |
视角数为 2 时性价比最优; 超过 3 后收益递减明显。LVB 上视角数增加反而先降后升,可能因为早期多视角产生分歧答案。
5.3 可视化对比
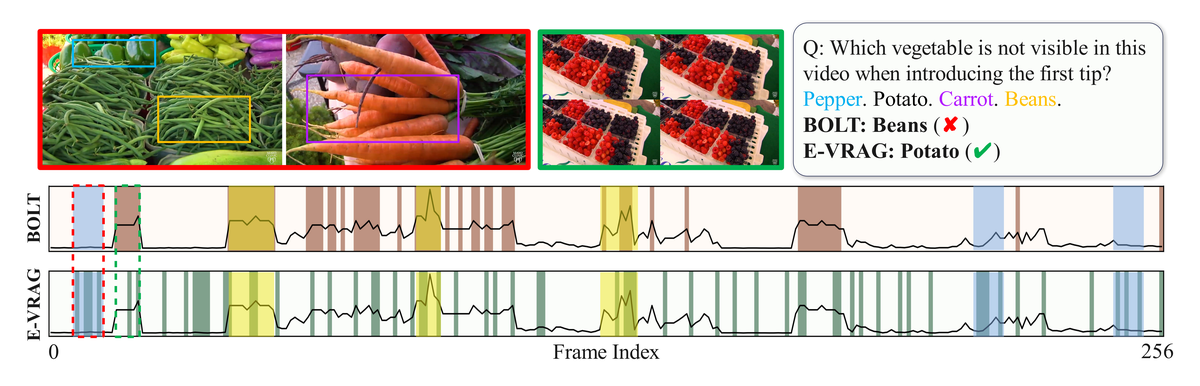
Figure 3 解读: 对比 BOLT (Online baseline) 和 E-VRAG 的帧检索分布。BOLT 使用 Top-K 策略,主要检索高分区域附近的帧 (黄色半透明框),而忽略低分区域的帧 (蓝色半透明框),导致高分区域冗余、低分区域信息缺失。E-VRAG 通过帧间分组确保高分帧被包含的同时,将部分高分区域的冗余配额重新分配给低分帧,实现更全面的视频表示。案例中 BOLT 回答错误 (Beans),而 E-VRAG 回答正确 (Potato)。
5.4 代码实现映射
注意: 论文代码截至目前 (2025年8月) 未公开。以下为基于论文描述的代码组件映射。
| 论文模块 | 预期实现组件 | 关键依赖 |
|---|---|---|
| 层次化查询分解 | LLM prompt engineering + Qwen3-1.7B | transformers, vllm |
| CLIP 相似度计算 | CLIP text/vision encoder | openai/clip |
| 帧间相似性分组 | 时间约束聚类算法 | scipy/sklearn |
| 逆变换采样 (ITS) | CDF 逆函数均匀采样 | numpy |
| 轻量 VLM 打分 | 2B VLM + yes/no prompt + vocab prob | transformers |
| 帧间概率分组 | 基于 分布相似性聚类 | scipy/sklearn |
| 多视角 QA | 迭代 VLM 推理 + 历史上下文拼接 | transformers |
| 投票 + 提前终止 | Counter + 连续一致性检查 | python stdlib |
| 答案 VLM | LLaVA-Video 7B | lmms-lab/LLaVA-Video |
5.5 总结与思考
5.5.1 关键创新点
- 数据层面效率优化: 层次化查询分解 + CLIP 预过滤,以极低成本 (单次 LLM + CLIP 推理) 将候选帧从 256 减至 128
- 模型层面效率优化: 使用 2B 轻量 VLM 替代 7B 模型进行检索打分,计算量大幅降低
- 帧间分组采样 (核心创新): 用全局分布替代 Top-K,解决了冗余高分区域和信息缺失低分区域的问题
- 多视角 QA: 简单有效的多轮推理增强策略,配合提前终止控制开销
5.5.2 局限性
- 仍未达到实时视频理解的要求
- 帧间分组的组数 (26) 为统一超参数,未针对不同数据集调优
- 多视角 QA 在 LVB 上效果不稳定 (先降后升)
- 预过滤阶段使用 CLIP,对需要细粒度理解的查询可能不够
5.5.3 启发与展望
- 即插即用设计: 无需训练,可与任意 VLM 组合,工程友好
- 帧间分组 + ITS 采样: 通用的帧采样策略,可推广到其他视频理解任务
- 轻量模型级联: 先粗后精的级联策略 (CLIP → 2B VLM → 7B VLM) 是高效推理的通用模式
- 未来方向: 自适应组数、更高效的帧间相似度计算、与流式视频处理结合