Attend Before Attention: Efficient and Scalable Video Understanding via Autoregressive Gazing
1. Motivation (研究动机)
- 现有 MLLM 处理视频效率低下:当前多模态大语言模型(如 InternVL3.5, Qwen2.5-VL 等)在处理视频时,对每一帧的每一个像素都等同处理,完全忽视了视频中大量存在的时空冗余(spatiotemporal redundancy)。例如静态背景只需看一次,但模型每帧都重新编码。
- 现有 Token 压缩方法只作用于 LLM 端:近期工作(如 STORM, FastVID, LongVU, VideoChat-Flash)虽然在 LLM 端做了 token 剪枝或压缩,但 ViT 仍然需要处理所有像素。这意味着 ViT 仍然是长视频、高分辨率视频处理的计算瓶颈。
- 无法 scale 到长时、高分辨率视频:受限于 ViT 的二次复杂度,现有模型无法处理 1K 帧、4K 分辨率的视频,而这正是自动驾驶、监控、长视频理解等现实场景的需求。
- 缺乏高分辨率长视频 benchmark:现有 benchmark(如 LongVideoBench, EgoSchema)只关注长视频但不要求高分辨率,无法评估模型在真实高分辨率长视频上的理解能力。
2. Idea (核心思想)
AutoGaze 的核心洞见是:在 ViT 处理之前就移除冗余 patch,而非之后。这类似于人类视觉中的注意力机制——眼睛会先跳到运动物体和细节丰富的区域,跳过静态背景。
具体而言,AutoGaze 是一个仅 3M 参数的轻量级模块,通过自回归方式逐帧选择一组多尺度 patch,使得已选 patch 能在用户指定的误差阈值内重建整个视频。这从根本上区别于现有方法:
- 现有方法:所有 patch → ViT → LLM(可选 token 压缩)
- AutoGaze:AutoGaze 筛选 patch → 少量 patch → ViT → LLM(双重加速)
3. Method (方法)
3.1 整体框架
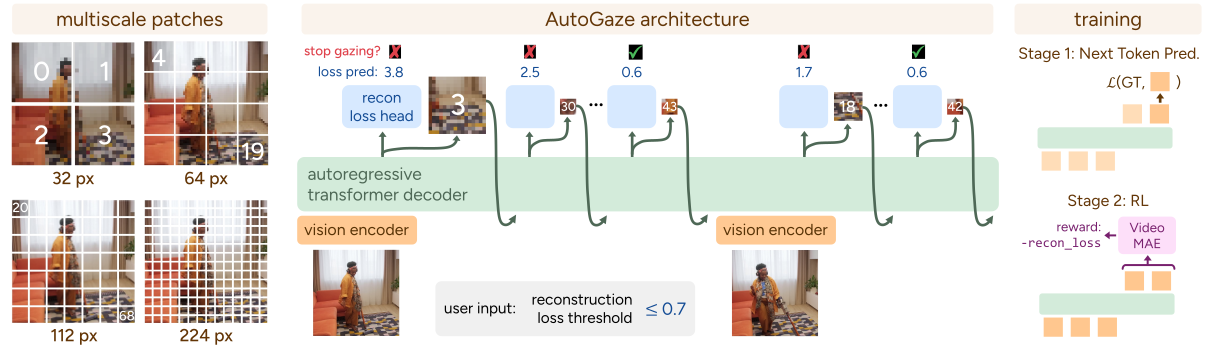
Figure 3 解读:该图展示了 AutoGaze 的完整架构和训练流程。左侧展示了多尺度 patch 的概念——同一帧图像被划分为 4 个尺度(32×32, 64×64, 112×112, 224×224 像素),共计 个 patch 构成 decoder 的词汇表。中间是 AutoGaze 的推理流程:对每一帧,卷积视觉编码器提取特征后送入自回归 Transformer decoder,decoder 逐步输出 patch 索引,同时一个 reconstruction loss 预测头估计当前重建损失,当预测损失低于用户设定阈值(如 )时自动停止当前帧的 gazing。右侧展示两阶段训练:Stage 1 用 Next Token Prediction 在 ground-truth gazing 序列上预训练,Stage 2 用 RL(以重建损失为 reward,通过 VideoMAE 计算)进行后训练。
AutoGaze 的整体流程如下:
- 输入:一段 帧的视频 ,每帧包含 个 patch
- 逐帧处理:对每帧 ,卷积编码器提取时空特征(利用当前帧和前两帧),decoder 基于历史帧和已选 patch 的上下文,自回归地输出 patch 索引
- 自动停止:reconstruction loss 预测头在每个 decoding step 预测重建损失,当低于阈值 时停止
- 输出:每帧只保留被选中的多尺度 patch,送入下游 ViT 和 MLLM
形式化定义:
其中 是第 帧第 个被选中的 patch 索引, 是第 帧选择的 patch 数量。
优化目标是找到满足重建损失阈值的最小 patch 集合:
3.2 模型架构
AutoGaze 包含三个组件,总计仅 3M 参数:
卷积视觉编码器 (ShallowVideoConvNet)
- 一层 2D 卷积(kernel size = 16)嵌入每个 patch
- 一层 3D 卷积(时空 kernel size = 3)提取时空特征,基于当前帧和前两帧
- 编码器是因果的(causal),不使用未来帧信息
- 支持流式推理:缓存前帧的卷积值
视觉连接器 (Connector)
- 在视觉编码器输出上添加学习到的位置嵌入
- 使得每个 token 知道其在帧内的空间位置
自回归 Transformer Decoder
- 基于 LLaMA 3 架构,但仅 4 层
- Hidden dimension = 192, attention heads = 6
- 最大位置编码 = 131,072(支持超长序列)
- 使用 RoPE 位置编码(scaling factor = 8.0)
- 词汇表大小 = 265:对应 4 个尺度的所有 patch 索引
- 32×32 px: 个 patch(每个覆盖 个基础 patch)
- 64×64 px: 个 patch
- 112×112 px: 个 patch
- 224×224 px: 个 patch(全分辨率,与 ViT 16×16 patch 一致)
3.3 多尺度 Gazing

Figure 2 解读:展示了 AutoGaze 在不同类型视频上的多尺度 gazing 行为。每个示例展示原始视频、multi-scale gazed patches 和重建视频。(a-b) 室内场景中 AutoGaze 聚焦于移动物体(人),移除静态区域冗余;(c) 棋盘格场景需要更多细节 patch;(d) 人物行走场景跟踪运动主体;(e) 足球场景适应场景变化选择更多 patch;(f) 纯色壁炉场景因细节少只需 3.51% 的 patch(28x reduction)。关键观察:AutoGaze 能 (1) 聚焦运动物体,(2) 适应场景变化,(3) 根据细节程度分配不同粒度的 patch。
不同区域需要不同分辨率的 patch:
- 纯色背景:一个 32×32 的大 patch 即可无损表示
- 细节丰富区域(如文字、纹理):需要 224×224 的小 patch 捕捉细节
- 中等复杂度区域:使用 64×64 或 112×112 的中间尺度
Decoder 的词汇表包含所有 4 个尺度的 patch,让模型自由选择最优尺度。这一设计使得 patch 数量大幅减少同时保持重建质量。
3.4 自动决定 Gazing 长度
在 decoder 上添加一个线性 reconstruction loss 预测头:
- 在解码每个 时,该头预测从已选 patch 重建第 帧的损失
- 当预测损失低于用户指定阈值 时,停止当前帧的 gazing
- 这使得不同复杂度的帧自适应地选择不同数量的 patch
3.5 Multi-Token Prediction
采用 multi-token prediction 技术,通过多个输出头同时预测多个 patch 索引及对应的重建损失:
- 实验发现同时预测 10 个 token 能很好地平衡 gazing ratio 和延迟
- 仅单 token 预测时延迟为 0.949s,10-token 预测时降低到 0.193s(约 5× 加速)
- 对 gazing ratio 几乎无影响(0.074 vs 0.094)
3.6 训练流程
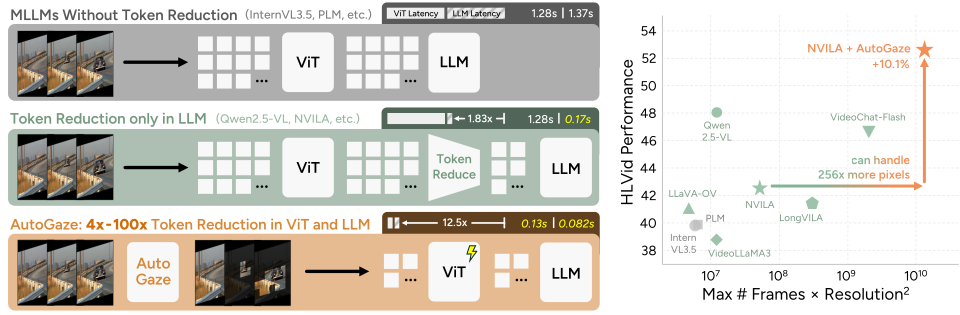
Figure 1 解读:对比三种方案的效率。上方:无 token reduction 的 MLLM(如 InternVL3.5)ViT 和 LLM 延迟均高。中间:仅在 LLM 端做 token reduction(如 Qwen2.5-VL, NVILA)ViT 延迟不变。下方:AutoGaze 在 ViT 前做 4x-100x token reduction,ViT 加速 12.5×,整体延迟大幅降低。右侧图展示 AutoGaze + NVILA 在 HLVid benchmark 上的突出表现,比 baseline 提升 10.1%,且能处理 256× 更多像素。
Stage 1: Next-Token Prediction (NTP) 预训练
给定视频 和通过 greedy search 收集的 gazing 序列 ,使用标准交叉熵损失预训练:
同时训练 reconstruction loss 预测,使用 损失监督子优 gazing 在不同长度下的重建损失。
- 训练数据:~250K 视频的 gazing 序列对
- 训练配置:150 epochs, batch size 256, learning rate 5e-4
Stage 2: Reinforcement Learning (GRPO) 后训练
由于预训练数据中的 gazing 序列是 greedy search 的次优解,进一步使用简化版 GRPO 算法进行 RL 后训练:
其中 advantage 是 return 在 group 内的归一化值:
即未来帧负重建损失的折扣和,折扣因子 。
- Group size = 12
- 温度从 1 退火到 0.01
- 每步随机采样 2 帧计算 VideoMAE 重建 reward(而非所有帧,提高效率)
- 训练配置:3 epochs, batch size 256, learning rate 5e-4
Algorithm: AutoGaze NTP Pre-training
Input: Videos X^{1:T}, greedy gazing sequences {p̂}
Output: Pre-trained AutoGaze model θ
1: for each video X^{1:T} in dataset:
2: for each frame t = 1, ..., T:
3: features = ConvEncoder(X^{t-2:t}) # causal 3D conv
4: vision_embeds = Connector(features) # add positional embeddings
5: for k = 1, ..., N^t:
6: # Autoregressive decoding with teacher forcing
7: logits = Decoder(vision_embeds, prev_gaze_embeds, kv_cache)
8: L_ntp += -log π_θ(p̂_k^t | context)
9: # Predict reconstruction loss at this step
10: l_pred = ReconLossHead(hidden_state)
11: L_recon_pred += (l_pred - l_gt_k^t)²
12: L_total = L_ntp + L_recon_pred
13: Update θ via gradient descent on L_total
Algorithm: AutoGaze GRPO Post-training
Input: Pre-trained AutoGaze θ, VideoMAE reconstruction model
Output: RL-refined AutoGaze model θ
1: for each video X^{1:T} in dataset:
2: ε = sample task_loss_threshold (fixed at 0.7)
3: # Roll out gazing with temperature annealing
4: for g = 1, ..., group_size (=12):
5: gazing_seq_g = AutoGaze.generate(X^{1:T}, ε, temperature)
6: # Compute rewards via VideoMAE
7: for each gazing_seq_g:
8: sample 2 random frames for reconstruction
9: reward_g = -VideoMAE_recon_loss(X, gazed_patches)
10: # Compute group-relative advantages
11: for each token p_k^t in each sequence:
12: G_k^t = Σ_τ γ^(distance) · (-l_{N^τ}^τ) # discounted return
13: A_k^t = normalize(G_k^t) within group
14: # Policy gradient update
15: L_GRPO = -Σ (π_θ / π_θ_detached) · A_k^t
16: L_recon_pred = MSE(predicted_loss, actual_loss) at last token
17: Update θ on L_GRPO + L_recon_pred
Algorithm: AutoGaze Inference (Generate)
Input: Video X^{1:T}, reconstruction loss threshold ε
Output: Selected multi-scale patch indices per frame
1: Initialize kv_cache, conv_cache = empty
2: for each frame t = 1, ..., T:
3: features, conv_cache = ConvEncoder(X^t, conv_cache) # streaming
4: vision_embeds = Connector(features)
5: Append vision_embeds to sequence
6: while True:
7: logits, kv_cache = Decoder(sequence, kv_cache)
8: # Apply constraints: no repeat, no EOS during gazing
9: logits = NoRepeatProcessor(logits)
10: p_k^t = argmax(logits) # greedy decoding
11: # Predict reconstruction loss
12: l_pred = ReconLossHead(hidden_state)
13: if l_pred ≤ ε:
14: break # stop gazing for this frame
15: Append gaze_embed(p_k^t) to sequence
16: return {p_{1:N^t}^t for t = 1..T}
Algorithm: Multi-Scale Patch Integration into ViT
Input: Selected patch indices per frame, original video
Output: ViT-encoded tokens for MLLM
1: for each frame t:
2: for each selected patch p_k^t:
3: Determine scale s (32/64/112/224 px) from patch index
4: Extract image region at scale s
5: Resize to ViT patch size (16×16)
6: Interpolate positional embeddings to match scale
7: Run patch embedding on each scale separately
8: Concatenate all embedded tokens from all scales
9: Feed all frames' tokens as one sequence into ViT (video mode)
10: Output encoded tokens to MLLM
3.7 训练数据构建
- 视频来源:~800K 视频,来自 Ego4D, 100DoH, InternVid,涵盖以自我为中心、以旁观者为中心、自然和文本密集型视频
- 人工运动视频:从高分辨率图像(SA-1B, IDL)裁剪窗口并滑动生成模拟相机运动的视频
- Gazing 序列收集:对 ~250K 视频子集,使用 greedy search 搜索最优 gazing 序列
- 对每帧随机采样 gazing ratio(指数分布,范围 0.02-0.2)
- 从第一帧第一个 patch 开始,贪心搜索使重建损失最小的 patch
- 同时记录每步的重建损失用于监督 loss prediction
3.8 下游集成
任意分辨率和时长的推理
尽管只在 16 帧 224×224 视频上训练,AutoGaze 可泛化到任意分辨率和时长:
- 受 any-resolution MLLM 启发,将视频分割为 的时空 tile
- 在每个 tile 上独立运行 AutoGaze
- 合并所有 tile 的 gazed patch 位置
集成到 ViT 和 MLLM
两处修改:
- 多尺度 patch 输入:ViT 通过插值位置嵌入到不同尺度,分别对每个尺度的 patch 运行 patch embedding,然后合并所有尺度的 token
- 图像 ViT → 视频 ViT:让图像 ViT 同时处理所有 16 帧的 token 作为一个序列
3.9 HLVid Benchmark
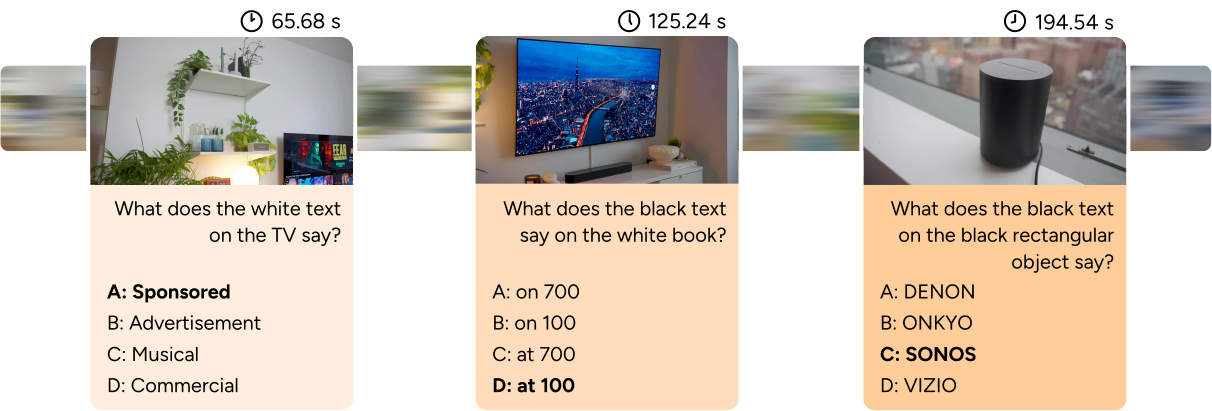
Figure 13 解读:HLVid benchmark 示例。每个样本包含一个 5 分钟、4K 分辨率的长视频和多项选择问题。上排展示房屋巡览视频的问题(如”电视上的白色文字写了什么?”),下排展示城市驾驶视频的问题(如”绿色路牌上两行白色文字写了什么?”)。这些问题都需要高分辨率感知(至少 1K-2K 分辨率)才能回答,强调了长上下文高分辨率视频理解能力。
- 首个长时高分辨率视频 QA benchmark
- 268 个 QA 对,基于最长 5 分钟的 4K 分辨率 YouTube 视频
- 每个问题经人工审核确保需要高分辨率感知(≥1K-2K 分辨率)
- 问题不含歧义,每个问题只有一个正确答案
3.10 代码-论文映射表
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| AutoGaze 整体模型 | autogaze/models/autogaze/autogaze.py | AutoGaze(PreTrainedModel) |
| 模型架构 (encoder + decoder) | autogaze/models/autogaze/modeling_autogaze.py | AutoGazeModel, ShallowVideoConvNet, Connector |
| 自回归生成 | autogaze/models/autogaze/modeling_autogaze.py | AutoGazeModel.generate() |
| Multi-token prediction decoder | autogaze/models/autogaze/modeling_llama_multi_token_pred.py | LlamaForCausalLM_MultiTokenPred |
| NTP 预训练 | autogaze/algorithms/ntp.py | NTP.__call__() |
| GRPO RL 后训练 | autogaze/algorithms/grpo.py | GRPO.__call__(), get_discounted_advantages() |
| VideoMAE 重建任务 | autogaze/tasks/video_mae_reconstruction/task_video_mae_reconstruction.py | VideoMAEReconstruction |
| VideoMAE 模型 | autogaze/tasks/video_mae_reconstruction/modeling_video_mae.py | ViTMAE |
| Gazing ratio 采样 | autogaze/models/autogaze/autogaze.py | AutoGaze.get_gazing_ratio() |
| 多尺度分辨率适配 | autogaze/models/autogaze/autogaze.py | AutoGaze.input_res_adapt() |
| SigLIP 视觉编码器 | autogaze/vision_encoders/siglip/modeling_siglip.py | SigLIP implementation |
| 视频数据加载 | autogaze/datasets/video_folder.py | Video folder dataset |
| 图像预处理 | autogaze/models/autogaze/processing_autogaze.py | AutoGazeImageProcessor |
| 模型配置 | autogaze/configs/model/autogaze.yaml | YAML config |
| 训练入口 | autogaze/train.py + autogaze/trainer.py | Training loop |
4. Experimental Setup (实验设置)
数据集
- 训练数据:~800K 视频(Ego4D, 100DoH, InternVid + 人工生成运动视频)
- Gazing 序列:~250K 视频子集的 greedy search 序列
- 视频采样:16 帧, 224×224 分辨率
Baseline 方法
MLLM SOTA 对比:
- 闭源:Gemini 1.5-Pro, Gemini 2.5 Flash-Lite, GPT-4o
- 开源:LLaVA-OV-8B, LongVILA-7B, LongVILA-R1-7B, Apollo-7B, VideoLLaMA3-7B, VideoChat-Flash, InternVL3.5-8B, Qwen2.5-VL-7B
Token Reduction 对比:
- Spatial: S-Pool, ToMe, VisionZip
- Temporal: T-Pool, AKS
- Spatiotemporal: ST-Pool, STORM, FastVID, F-16, LongVU, PruneVid, VChat-Flash
Gazing Baseline 对比:
- Random Gaze, RGB-Diff Gaze, Optical-Flow Gaze
评估 Benchmark
- 通用视频:VideoMME (w/o sub), VideoMME (w/ sub), MVBench (test)
- 长视频:NExT-QA (mc), L-VidBench (val), EgoSchema (test), MLVU (m-avg)
- 高分辨率长视频:HLVid (test)
训练配置
- 默认 ViT:SigLIP2-SO400M
- 默认 MLLM:NVILA-8B-Video
- NTP 预训练:150 epochs, batch 256, lr 5e-4
- RL 后训练:3 epochs, batch 256, lr 5e-4, group size 12, γ=0.995
- MLLM 微调:256 帧, 896 分辨率,推理时 scale 到 1K 帧, 4K 分辨率
5. Experimental Results (实验结果)
AutoGaze 的 Gazing 行为分析
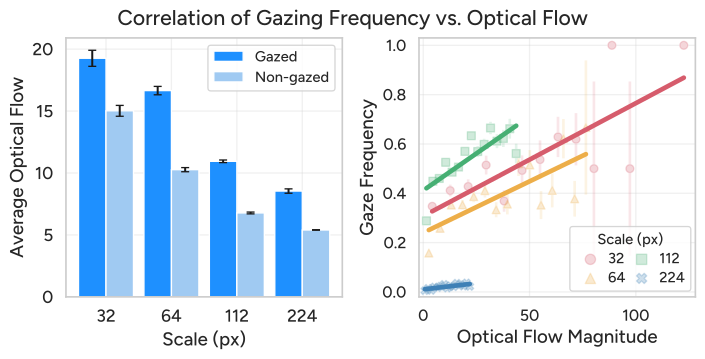
Figure 4 解读:左图显示在所有尺度上,被 gazed 的 patch 比未被 gazed 的 patch 有更高的平均光流值,证实 AutoGaze 优先选择运动区域。右图更直接地展示了 gazing 频率与光流大小的正相关关系。
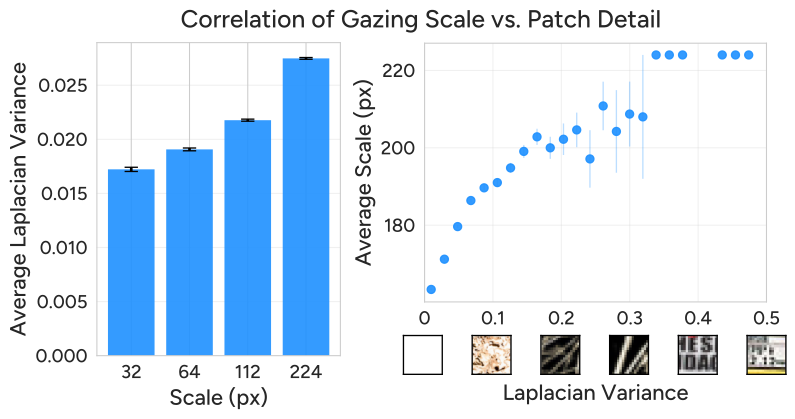
Figure 5 解读:左图展示在更细的尺度上,AutoGaze 倾向于选择 Laplacian 方差更大(即更详细)的 patch。右图证实细节更丰富的 patch(高 Laplacian 方差)使用更细的尺度(更高的平均分辨率),。
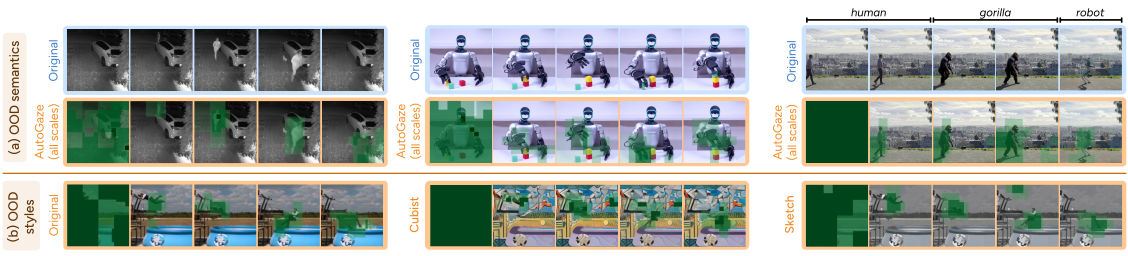
Figure 6 解读:(a) AutoGaze 在 OOD 语义(CCTV 监控、机器人抓取、物体交换)上仍能正确追踪变化区域。(b) 对同一视频进行不同风格迁移后,AutoGaze 始终追踪摔倒的人,证明对视觉风格的鲁棒泛化。
Patch 数量与重建质量
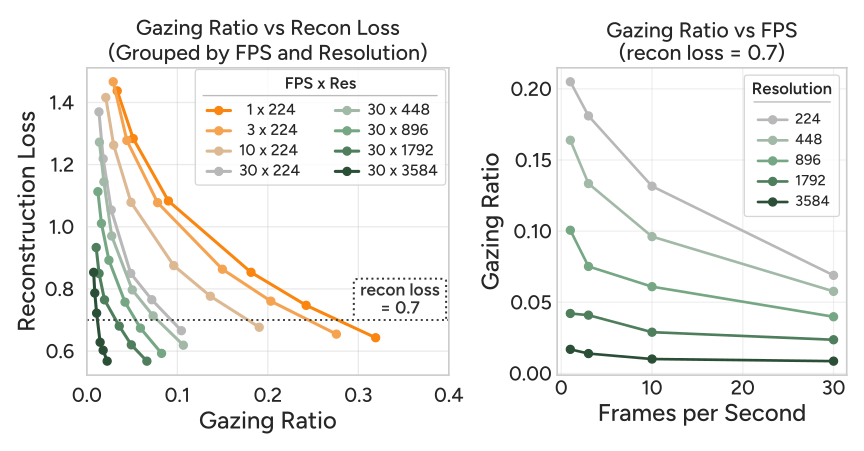
Figure 7 解读:左图展示 gazing ratio 与重建损失的 trade-off 曲线,不同 FPS 和分辨率有不同曲线,高 FPS/高分辨率的视频需要更低的 gazing ratio 达到相同损失。右图显示在目标重建损失 0.7 下,30-FPS 4K 视频只需约 1% 的 patch(即 100× reduction)。
效率提升
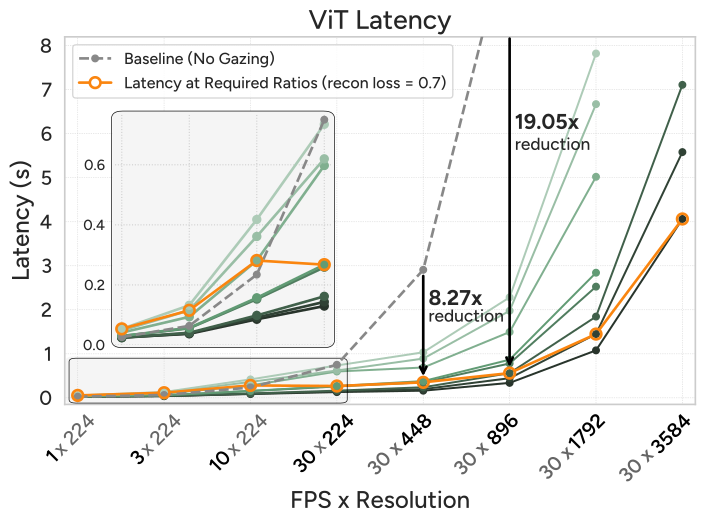
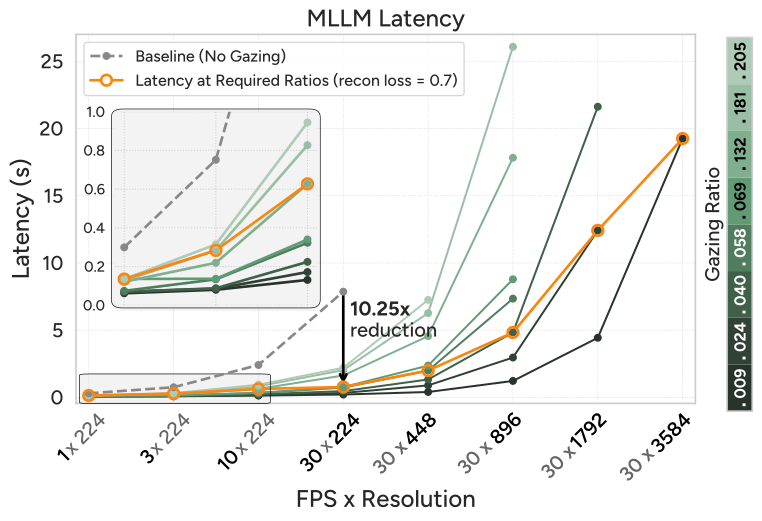
Figure 8 解读:ViT 延迟(左)和 MLLM 延迟(右)的对比。Baseline(无 gazing)在高 FPS/高分辨率时迅速 OOM。AutoGaze 在所有条件下保持低延迟,最高实现 19.05× ViT 加速和 10.25× MLLM 加速。
MLLM Scaling 性能

Figure 9 解读:在 5 个 benchmark 上比较有/无 AutoGaze 时 MLLM 随 token 数增加的性能变化。Baseline 在 256 帧后 OOM,而 AutoGaze 能持续 scale。在 HLVid 上效果最为显著——需要高分辨率处理,AutoGaze 从约 38% 提升到约 46%。
SOTA 对比 (Table 1)
| Models | Max F | Max Res. | VideoMME (w/o) | VideoMME (w/) | MVBench | MLVU | HLVid |
|---|---|---|---|---|---|---|---|
| GPT-4o | - | - | 71.9 | 77.2 | 64.6 | 64.6 | 49.3 |
| Qwen2.5-VL-7B | 48 | 896 | 65.1 | 71.6 | 69.6 | 70.2 | 48.1 |
| NVILA-8B-Video | 256 | 448 | 64.2 | 70.0 | 68.1 | 70.1 | 42.5 |
| + AutoGaze | 1024 | 3584 | 67.0 (+2.8) | 71.8 (+1.8) | 69.7 (+1.6) | 71.6 (+1.5) | 52.6 (+10.1) |
关键发现:
- AutoGaze + NVILA 在所有 benchmark 上持续提升,帧数从 256→1024 (×4),分辨率从 448→3584 (×8)
- HLVid 上提升最大 (+10.1%),因为该 benchmark 需要高分辨率感知
- 超越所有开源 MLLM(包括 Qwen2.5-VL-7B)和 GPT-4o
Token Reduction 方法对比 (Table 2)
在 128 帧、6.25% 选择率的条件下:
| Method | ViT lat. | LLM lat. | V-MME (w/o) | L-Vid (val) |
|---|---|---|---|---|
| No Reduction | 2.20s | 1.42s | 53.4 | 51.1 |
| AutoGaze | 0.55s | 0.10s | 52.3 | 50.3 |
AutoGaze 是唯一同时加速 ViT(4×)和 LLM 的方法,其他方法 ViT 延迟不变。
Gazing Baseline 对比
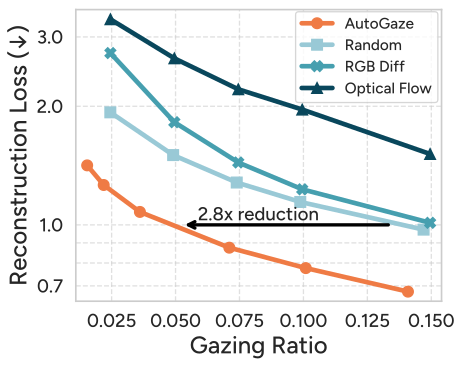
Figure 10 解读:AutoGaze 相比启发式方法(Random, RGB-Diff, Optical-Flow Gaze)能用更小的 gazing ratio 达到相同重建损失。例如达到 1.0 的重建损失,AutoGaze 只需 5% patch 而 Random 需要 15%。RGB-Diff 和 Optical-Flow 因依赖第一帧差异(padding 导致突变)反而不如 Random。
Ablation 实验
训练流程 (Table 3):
| Pre-Train | Post-Train | Recon Loss | Gazing Ratio |
|---|---|---|---|
| ✗ | ✗ | 0.7 | 0.263 |
| ✓ | ✗ | 0.7 | 0.102 |
| ✗ | ✓ | 0.7 | 0.209 |
| ✓ | ✓ | 0.7 | 0.094 |
两阶段训练都有贡献,NTP 预训练更重要(ratio 0.102 vs 0.209),RL 后训练在此基础上进一步提升约 10%。
模型设计 (Table 4):
| Multi-Token Pred. | Multi-Scale | Recon Loss | Gazing Ratio | Latency |
|---|---|---|---|---|
| 1 | ✓ | 0.7 | 0.074 | 0.949s |
| 10 | ✓ | 0.7 | 0.094 | 0.193s |
| 10 | ✗ | 0.7 | 0.220 | 0.467s |
- Multi-token prediction (10 tokens) 将延迟从 0.949s 降到 0.193s(5× 加速),gazing ratio 仅略增
- 多尺度 gazing 将 gazing ratio 从 0.220 降到 0.094(2.3× 更高效),同时延迟也更低
重建损失阈值 (Table 5):
| Recon. Loss | 64 Frames | 128 Frames | 256 Frames |
|---|---|---|---|
| No Gaze | 59.1 | 60.1 | 60.5 |
| 0.7 | 58.6 | 59.7 | 60.3 |
| 1.0 | 56.3 | 56.7 | 57.2 |
阈值 0.7 时性能下降 < 0.5%,是效率和质量的最佳平衡点。
局限性
- 不处理相机运动:当场景平移时,AutoGaze 仍会选择 patch 而非利用运动补偿,存在冗余
- 缺乏物理直觉:VideoMAE 是因果的但不具备”直觉物理”知识(如无法预测自由落体球会继续下落),因此对涉及物理运动预测的帧可能过度采样