RubricEM: Meta-RL with Rubric-guided Policy Decomposition beyond Verifiable Rewards
Paper: arXiv:2605.10899v1
1. Motivation (研究动机)
现有 Deep Research Agent 的核心瓶颈不是“不会搜索”,而是很难用 RL 训练开放式长报告任务:最终答案没有唯一 ground truth,轨迹包含多轮规划、检索、证据判断和写作,只有终局分数时很难知道错误来自 Plan、Research、Review 还是 Answer。
本文要解决的问题是:如何在 beyond verifiable rewards 的长程研究任务中,把 rubric 从“最终打分表”升级为贯穿 policy execution、judge feedback、agent memory 的共享接口。也就是让 agent 先用 rubric 组织思考,再让 judge 按 stage rubric 给密集 credit,最后把被 judge 过的经验沉淀成可检索的 reflection memory。
这个问题值得研究,因为一旦能训练这类无标准答案的长程 agent,RL 就不再局限于 math/code/exact answer 这类可验证任务,而能覆盖研究报告、科学综述、数据分析、tutoring、复杂工具链等质量多维、评价语义化的任务。
2. Idea (核心思想)
核心洞察:Rubric 不应只作为输出后的 evaluator,而应成为 agent、judge、memory 三者共享的中间语言。RubricEM 先把长轨迹显式拆成 Plan → Research → Review → Answer 四个 stage,让 agent 自生成 task-specific rubric;再用 stagewise rubric judge 把 long-horizon credit assignment 从单一终局 reward 改成 stage-level semantic reward;最后用 shared-backbone reflection meta-policy 把 judged trajectory 转成 reusable guidance。
关键创新可以概括为 “structure → assign → evolve”:先用 rubric-guided scaffold 暴露任务结构,再用 Stage-Structured GRPO 给结构化 credit,最后用 reflection meta-policy 和 rubric bank 让经验既更新参数,也更新文本记忆。
与 DR Tulu 这类端到端 deep research RL 相比,RubricEM 不是只延长训练或增加最终 judge reward,而是显式建模中间阶段:DR Tulu 主要依赖终局或较粗粒度反馈;RubricEM 让 Plan/Research/Review/Answer 分别被 judge、归因和复用,因此更适合开放式长报告的语义 credit assignment。
3. Method (方法)
3.1 Overall framework
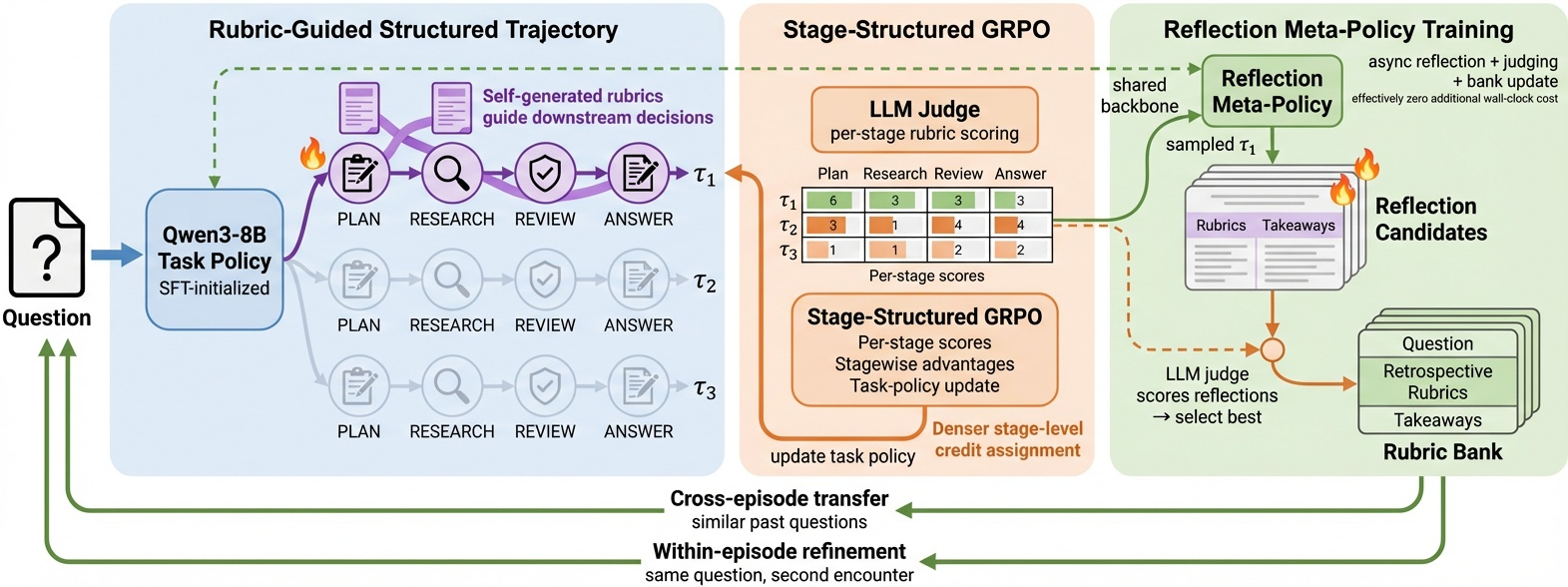
Figure 1 解读:RubricEM 的主线是左到右三段。左侧用 Qwen3-8B task policy 生成多条 stage-structured trajectory,每条 trajectory 都按 Plan/Research/Review/Answer 展开,并由 self-generated rubrics 指导后续决策;中间 LLM Judge 对每个 stage 单独评分,Stage-Structured GRPO 用 per-stage scores 计算 stagewise advantages;右侧 shared-backbone Reflection Meta-Policy 从 judged trajectory 中采样 reflection candidates,经 judge 选择后写入 Rubric Bank,后续通过 cross-episode transfer 或 within-episode refinement 反哺新问题。
整体训练对象是一类 tool-augmented deep research agent。给定 query ,agent 与工具环境 交互并产生轨迹
其中 可以是文本段或结构化 tool call, 是工具返回。policy 以 autoregressive 方式采样
RubricEM 在这个基础上增加三层结构:rubric-guided scaffold、SS-GRPO、reflection meta-policy training。
3.2 Rubric-guided structured reasoning scaffold
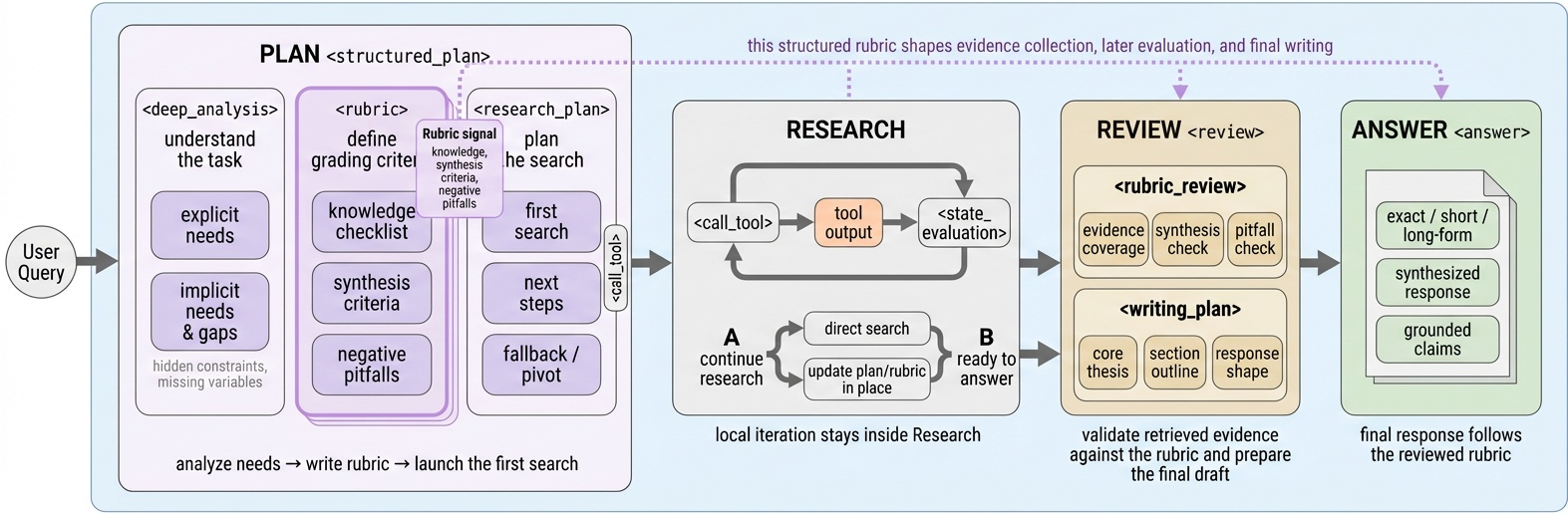
Figure 3 解读:scaffold 把 agent 输出组织成四个 XML-like stage:Plan 中先做 deep analysis、生成 rubrics 和 research plan;Research 中循环 call_tool → tool_output → state_evaluation,并允许根据证据修订 plan;Review 中把证据映射回 rubric,形成 writing plan;Answer 中生成最终长答案。关键点是 rubric 在 Plan 阶段产生,但贯穿 Research、Review 和 Answer,而不是只在结尾评分。
论文用一个 stage-information theorem 解释为什么显式 stage 有价值。令 为 trajectory 中的随机决策点, 为压缩状态表示, 为当前 stage label, 为在 history 采取 action 后继续 rollout 的期望下游价值。定义:
如果同一个压缩状态 在不同 stage 下的最优动作集合不相交,则
直觉是:长程研究中,同样的局部上下文可能要求完全不同的动作;Plan 阶段应先拆解问题,Research 阶段应检索证据,Review 阶段应查缺补漏,Answer 阶段应整合写作。若没有 stage label,policy 必须从局部 token 猜当前模式,容易在长轨迹中混淆;显式 stage 则把“当前决策模式”作为条件变量暴露出来。
3.3 Stage-Structured GRPO (SS-GRPO)
RubricEM 的第二步是把 scaffold 变成 reward/advantage 的归因单位。给定同一 query 的 条 rollout ,每条轨迹分成 个 semantic stages。令 为第 条 rollout 在 stage 的 token block, 为 LLM judge 在该 stage rubric 下的得分。
SS-GRPO 不把终局分数广播到所有 token,而是定义一个 causal stage-dependence matrix ,其中 for 且 ,并计算 stage return:
每个 stage 保留自己的局部分数,同时接收它对 downstream stage 的贡献。然后在同一 stage 内跨 rollout group 做 normalization:
所有属于同一 stage block 的 token 共享 ,目标函数为:
其中
论文还给出实验中使用的 :
3.4 Evolving-rubric judge and reflection meta-policy

Figure 4 解读:上半部分展示两个耦合的 judge-agent loop。task-policy loop 中,LLM judge 对同一 query 的多条 stage-structured rollout 做对比,生成或更新每个 stage 的 discriminative rubric buffer,再对每条 rollout 的每个 stage 打分,形成 SS-GRPO reward。reflection loop 中,shared backbone 对一个 query-trajectory pair 生成多个 reflection candidates,judge 根据 task rollout 的 rubric scores 和 justifications 打分,最高分 reflection 写入 Rubric Bank,同时 reflection tokens 也用 GRPO 更新 shared policy。下半部分展示异步实现:reflection generation、judging、update 使用上一轮轨迹延迟执行,避免阻塞当前 task rollout。
Judge 本身不更新参数,而是维护 Plan/Research/Review/Answer 四个 stage 的 rubric buffer:它从 on-policy rollouts 中发现新的 failure modes,保留能区分好坏轨迹的 rubric,删除不再有判别力的 rubric。这样中间 reward 不是固定模板,而是随 policy distribution 演化。
Reflection Meta-Policy 与 task policy 共享 backbone。task rollout 被 judge 后,系统采样一个 query—trajectory pair,固定原始轨迹作为 context,只对 reflection tokens 反向传播。privileged judge 从两个角度评分:一是 reflection 是否有助于同一 query 的 within-episode refinement;二是是否可迁移到相似 query 的 cross-episode transfer。被接受的 reflection 进入 agent rubric bank,作为自然语言 memory。

Figure 2 解读:该例子用 “sleep patterns 如何影响 aging cognitive decline” 展示单个 RL step 内的完整闭环。右上是 Plan stage 产生的 deep analysis、rubrics 和 research plan;左侧 Research stage 通过搜索工具检索证据并做 state evaluation;左下 Review stage 检查证据是否满足 causal framing 和 search precision 等 rubric;右中 Answer stage 生成最终回答;底部 Stagewise Rubrics 显示 judge 可以按 Plan、Research、Answer 等 stage 给出正负判断。右下 reflection 把本次轨迹的经验提炼成 retrospective rubric 和 takeaway,用于后续 memory。
3.5 Windowed curriculum and asynchronous memory update
为了实现 cross-episode 与 within-episode 两种 memory 使用方式,RubricEM 使用 windowed curriculum。实验中 ,每个 step window 前 3 步采样 fresh batches 并做 cross-episode retrieval;后 3 步按同样顺序 replay ,使用第一遍生成的 reflection 做 within-episode exact retrieval。3-step gap 保证 reflection generation、judge scoring、bank insertion 和至少一次 deferred training step 已完成。
| Step in window | Phase | Data | Retrieval mode |
|---|---|---|---|
| 1 | New | fresh | Cross-episode similar |
| 2 | New | fresh | Cross-episode similar |
| 3 | New | fresh | Cross-episode similar |
| 4 | Repeat | replay | Within-episode exact |
| 5 | Repeat | replay | Within-episode exact |
| 6 | Repeat | replay | Within-episode exact |
3.6 Algorithm-level pseudocode
代码搜索未找到开源实现;以下伪代码根据 arXiv source 中 Algorithm 1、method sections 和 appendix training pipeline 重构,用于理解论文流程,不是 released code。
3.6.1 Rubric-guided rollout scaffold
def rubric_guided_rollout(policy, query, tools, retrieved_experience=None):
history = [query]
if retrieved_experience is not None:
history.append(format_rubric_bank_items(retrieved_experience))
plan = policy.generate(
history,
required_tags=["<structured_plan>", "<analysis>", "<rubrics>", "<research_plan>"]
)
history.append(plan)
evidence = []
while not has_sufficient_evidence(history) and len(evidence) < MAX_TOOL_CALLS:
tool_call = policy.generate(history, required_tags=["<call_tool>"])
tool_output = tools.run(tool_call)
state_eval = policy.generate(
history + [tool_output],
required_tags=["<state_evaluation>"]
)
history.extend([tool_call, tool_output, state_eval])
evidence.append(tool_output)
review = policy.generate(
history,
required_tags=["<review>", "<rubrics_review>", "<writing_plan>"]
)
answer = policy.generate(history + [review], required_tags=["<answer>"])
return parse_stage_blocks(history + [review, answer])3.6.2 Stage-Structured GRPO update
import torch
import torch.nn.functional as F
def compute_stage_advantages(stage_scores, lambda_matrix, eps=1e-6):
# stage_scores: [num_rollouts, num_stages], values in [0, 1]
# lambda_matrix[k, j] = downstream credit from stage j to stage k
returns = stage_scores @ lambda_matrix.T
mean = returns.mean(dim=0, keepdim=True)
std = returns.std(dim=0, keepdim=True)
return (returns - mean) / (std + eps)
def ss_grpo_loss(logp_new, logp_old, ref_logp, stage_ids, advantages, clip_eta=0.2, beta=0.001):
# logp_*: [num_rollouts, seq_len]
ratio = torch.exp(logp_new - logp_old)
token_adv = torch.gather(advantages, dim=1, index=stage_ids)
unclipped = ratio * token_adv
clipped = torch.clamp(ratio, 1 - clip_eta, 1 + clip_eta) * token_adv
policy_loss = -torch.minimum(unclipped, clipped).mean()
kl = (torch.exp(logp_new) * (logp_new - ref_logp)).mean()
return policy_loss + beta * kl3.6.3 Evolving judge and rubric buffers
def update_stagewise_rubric_buffers(judge, query, rollouts, old_buffers, caps):
proposed = judge.generate_discriminative_rubrics(
query=query,
rollouts=rollouts,
active_buffers=old_buffers,
stages=["Plan", "Research", "Review", "Answer"],
)
merged = {stage: old_buffers[stage] + proposed[stage] for stage in old_buffers}
stage_scores = {}
for stage, rubrics in merged.items():
stage_scores[stage] = judge.score_stage(
query=query,
rollouts=rollouts,
stage=stage,
rubrics=rubrics,
)
merged[stage] = prune_by_discrimination(
rubrics=merged[stage],
scores=stage_scores[stage],
max_items=caps[stage],
)
return merged, stage_scores3.6.4 Reflection meta-policy and rubric bank
def prepare_reflection_batch(policy, judge, query, rollouts, stage_scores, rubric_buffers, bank, m=8):
trajectory = sample_uniform(rollouts)
candidates = policy.generate_n(
prompt=build_reflection_prompt(query, trajectory),
n=m,
temperature=0.7,
)
rewards = []
for cand in candidates:
score = judge.score_reflection(
query=query,
trajectory=trajectory,
reflection=cand,
stage_scores=stage_scores,
rubric_buffers=rubric_buffers,
criteria=["within_episode_refinement", "cross_episode_transfer"],
)
rewards.append(score)
best = candidates[int(torch.tensor(rewards).argmax())]
if is_valid_reflection(best):
bank.upsert(query_hash=sha256(query), query=query, reflection=best)
return build_grpo_samples(candidates, rewards)3.6.5 Full training loop
def train_rubricem(policy, ref_policy, data, tools, judge, lambda_matrix, total_steps):
bank = RubricBank(embedding_model="Qwen3-Embedding-0.6B", top_k=2)
active_buffers = init_stage_buffers(stages=["Plan", "Research", "Review", "Answer"])
deferred_reflection_batch = None
for step in range(1, total_steps + 1):
queries, retrieval_mode = windowed_batch(data, step, window_k=3)
retrieved = {q: bank.retrieve(q, mode=retrieval_mode) for q in queries}
if deferred_reflection_batch is not None:
policy.update_on_reflection_tokens(deferred_reflection_batch, objective="GRPO")
all_task_samples = []
async_reflection_jobs = []
for q in queries:
rollouts = [rubric_guided_rollout(policy, q, tools, retrieved[q]) for _ in range(8)]
active_buffers[q], stage_scores = update_stagewise_rubric_buffers(
judge, q, rollouts, active_buffers.get(q, init_stage_buffers()), caps=[3, 2, 2, 3]
)
advantages = compute_stage_advantages(stage_scores, lambda_matrix)
all_task_samples.extend(pack_stage_token_samples(q, rollouts, advantages))
async_reflection_jobs.append(
launch_async(prepare_reflection_batch, policy, judge, q, rollouts, stage_scores, active_buffers[q], bank)
)
policy.update_on_task_tokens(all_task_samples, ref_policy=ref_policy, objective="SS-GRPO")
deferred_reflection_batch = collect_completed(async_reflection_jobs)
if step % 10 == 0:
bank.save_atomic(step)3.7 Code search and paper-to-source mapping
代码搜索未找到开源实现。已检查 arXiv HTML/source 中的 project/GitHub 链接、Web 搜索 RubricEM GitHub / RubricEM-8B GitHub / Stage-Structured GRPO GitHub,以及 GitHub repository search;仅发现无关的同名自动化测试仓库,未发现作者官方 repo。因此本笔记不设置 github / github_ref,也不存在 released code 与论文公式的实现差异可比对。
Code reference: 代码搜索未找到开源实现(2026-05-16);下表映射到 arXiv source sections,而非 released code。
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Overall framework / trajectory notation | sections/method.tex; sections/Intro.tex | 未公开;见伪代码 train_rubricem |
| Rubric-guided scaffold | sections/method_1_scaffolding.tex; sections/appen_scaffold.tex | 未公开;见 rubric_guided_rollout |
| SS-GRPO objective | sections/method_2_ssgrpo.tex; sections/appen_theory.tex | 未公开;见 compute_stage_advantages, ss_grpo_loss |
| Evolving-rubric judge | sections/method_2_ssgrpo.tex; sections/appen_evolving_judge.tex | 未公开;见 update_stagewise_rubric_buffers |
| Reflection meta-policy / rubric bank | sections/method_3_evolving.tex; sections/appen_async_detail.tex | 未公开;见 prepare_reflection_batch, RubricBank |
| Full procedure | sections/appen_algo.tex | 未公开;Algorithm 1 |
论文公式与 released code 实现差异:无 released code,无法检查实现是否偏离论文公式;训练配置数字均来自 arXiv source 的 appendix training details,而非通用 README/default config。
4. Experimental Setup (实验设置)
Datasets and benchmarks
长形式 benchmark:
| Benchmark | Scale | Evaluation |
|---|---|---|
| HealthBench | 1000 medical questions subsample | GPT-4 LLM-as-judge,按 per-question rubrics 评估 accuracy、completeness、context awareness、communication,报告 rubric satisfaction rate |
| ResearchQA | 756 scientific research questions | GPT-4 LLM-as-judge,expert-authored rubric items,5-point coverage scale,报告 normalized coverage |
| DeepResearchBench (DRB) | 100 complex research questions | RACE scoring,Gemini judge 同时评估 report content quality 与 citation accuracy |
| ResearchRubrics | 101 open-ended deep research prompts | LLM-as-judge,expert prompt-specific rubrics,覆盖 factual grounding、reasoning、synthesis、relevance、clarity、citation use,报告 binary score |
短形式 out-of-domain benchmark:SimpleQA、2WikiMultihopQA(1000 multi-hop questions)、WebWalker(680 web navigation questions)、DeepSearchQA(900 search-intensive questions)。短形式任务在同一 agent pipeline 与 search tools 下 zero-shot 评估,RL 阶段没有使用 short-form data。
训练数据:SFT queries 来自 DR Tulu 使用的约 13K open-ended research questions,由 Gemini-3.1-Pro teacher 生成 stage-structured trajectories;RL 使用同一 DR Tulu RL dataset rl-research/dr-tulu-rl-data,约 4.9K diverse deep research queries。训练 query 来源包括 SearchArena 的 realistic search conversations 和 OpenScholar 的 research-oriented questions。
Baselines
对比对象覆盖三类:
- Closed Deep Research:Claude-Sonnet Search、Perplexity-Sonar (High)、Perplexity Deep Research、Gemini Deep Research、Gemini 3.1 Pro + Search、GPT-5 + Search、OpenAI Deep Research。
- Fixed Pipeline Deep Research:WebThinker QwQ-32B、WebThinker-32B-DPO、Ai2 ScholarQA — Claude Sonnet。
- Open Deep Research Models:Search-R1-7B、WebExplorer-8B、Tongyi DeepResearch-30B-A3B、DR Tulu-8B (SFT)、DR Tulu-8B (RL, 1900 steps)。
Training config
SFT:
- Base model / framework: Qwen3-8B, LLaMA-Factory, DeepSpeed ZeRO-3。
- Optimization: 5 epochs, LR , cosine scheduler with 10% warmup, BF16, weight decay 0.0。
- Batch / length: batch size per device 1, gradient accumulation 16, effective batch size 128 = 8 GPUs 16 accum., max sequence length 16,384 tokens。
- Hardware / masking: 8 NVIDIA H100 80GB;对
<tool_output>做 span masking,不在搜索结果 token 上给梯度。
RL:
- Algorithm / rollout: GRPO / SS-GRPO, 8 rollouts per prompt, 32 unique prompts per step, effective batch size 256。
- Optimization: LR , constant scheduler, KL coefficient , KL estimator KL3, PPO-style clipping, temperature 1.0。
- Length / tools: max response length 18,432 tokens, max prompt length 8,192 tokens, max total pack length 26,624 tokens, max tool calls per trajectory 10。
- System components: ZeRO-3 with CPU offloading, gradient checkpointing enabled;judge model 和 rubric generation model 都是 Gemini Flash;rubric buffer cap per stage = 3, 2, 2, 3;rubric bank 使用 Qwen3-Embedding-0.6B, retrieval top-, reflection trajectories sampled = 1, windowed curriculum , bank 每 10 steps 保存。
Ablation runs 使用同一 600-step budget 和 2 nodes,从同一 RubricEM-SFT checkpoint 开始;最终 RubricEM run 使用 4 nodes,训练 1400 RL steps。奖励设计只使用 rubric-based judge signals,不加入 format reward、citation reward 或 tool-use heuristics。
5. Experimental Results (实验结果)
Main long-form performance
RubricEM-8B (RL, 1400 steps) 在开源/非专有模型中平均分最高,且 8B 模型接近 proprietary deep research systems。主结果如下:
| Model | HealthBench | ResearchQA | DRB | ResearchRubrics | Average |
|---|---|---|---|---|---|
| Gemini 3.1 Pro + Search | 47.5 | 74.5 | 44.4 | 49.1 | 53.9 |
| GPT-5 + Search | 59.5 | 78.2 | 50.7 | 60.5 | 62.2 |
| OpenAI Deep Research | 53.8 | 79.2 | 46.9 | 59.7 | 59.9 |
| WebThinker-32B-DPO | 39.4 | 74.2 | 40.6 | 41.9 | 49.0 |
| Tongyi DeepResearch-30B-A3B | 46.2 | 66.7 | 40.6 | 49.5 | 50.8 |
| DR Tulu-8B (SFT) | 38.1 | 68.5 | 39.0 | 38.4 | 46.0 |
| DR Tulu-8B (RL, 1900 steps) | 50.2 | 74.3 | 43.4 | 46.4 | 53.6 |
| Qwen3-8B + Our Search | 24.5 | 58.4 | 28.2 | 24.5 | 33.9 |
| RubricEM-8B (SFT) | 39.0 | 71.8 | 43.0 | 42.8 | 49.2 |
| RubricEM-8B (RL, 1400 steps) | 49.3 | 74.5 | 47.8 | 50.3 | 55.5 |
关键读数:RubricEM 从 SFT 到 RL 的 average 从 49.2 提升到 55.5(+6.3);相对 DR Tulu-8B (RL, 1900 steps) 的 average 53.6,RubricEM 用 1400 steps 达到 55.5。它在 ResearchQA、DRB、ResearchRubrics 三项上是非专有模型最佳,但 HealthBench 上 DR Tulu-8B RL 的 50.2 略高于 RubricEM 的 49.3。
Ablation: RL training recipes

Figure 5 解读:600-step budget 下,Baseline RL、SS-GRPO、Meta-Policy、RubricEM 都从同一个 SFT checkpoint 出发。RubricEM 在 average delta over SFT、DRB、HealthBench、ResearchQA 上整体曲线最高,说明 SS-GRPO 的 stage-level credit 和 Reflection Meta-Policy 的 experience reuse 不是替代关系,而是互补;只加 SS-GRPO 或只加 Meta-Policy 均能改善,但 full recipe 最稳定。
Ablation: scaffold and experience reuse

Figure 6 解读:Panel (a) 显示 structured SFT 相比 unstructured SFT 在 DRB/HealthBench/ResearchQA 上分别为 43.0 vs 39.8、39.0 vs 34.2、71.8 vs 70.2,说明 scaffold 直接提高蒸馏质量。Panel (b) 显示 structured RL 的 gain 曲线高于 unstructured RL,说明 scaffold 也让后续 RL 更有效。Panel (c) 控制 Gemini-3.1-Pro 和同一 search backend,只改变 prompt,Our Scaffold 在 DRB 上达到 43.5,高于 ReAct 的 39.9。Panel (d) 显示 RubricEM 在 cross-episode pass 1 与 within-episode pass 2 中分别 +0.4、+0.7,而 Baseline RL 在相同 retrieval 设置下为 -0.5、-0.6,说明 memory/reuse 不是简单增加上下文,而依赖训练出的 reflection meta-policy。
Short-form transfer
| Model | SimpleQA | 2Wiki | WebWalker | DSQA | Avg. |
|---|---|---|---|---|---|
| DR Tulu-8B (SFT) | 75.5 | 66.5 | 31.9 | 5.3 | 44.8 |
| DR Tulu-8B (RL, 1900 steps) | 80.1 | 68.0 | 39.1 | 8.3 | 49.0 |
| Qwen3-8B + Our Search | 84.0 | 61.5 | 42.6 | 15.2 | 50.8 |
| RubricEM-8B (SFT) | 92.1 | 77.5 | 64.7 | 37.0 | 67.8 |
| RubricEM-8B (RL, 1400 steps) | 92.3 | 78.8 | 70.0 | 53.0 | 73.5 |
短形式结果说明:虽然 RL 只用 long-form queries,RubricEM-8B RL 在 SimpleQA、2Wiki、WebWalker、DSQA 全部超过 DR Tulu baseline,平均 73.5;最明显的是 DSQA,从 SFT 的 37.0 提升到 RL 的 53.0。
Limitations
作者明确指出三类限制:第一,long-horizon agentic RL 依赖 search tool calls 和外部 LLM judging,训练比标准 offline RL/SFT 更容易受 API delay、network instability、rollout-judge latency 影响;主大规模 RL run 中训练服务器多次 shutdown/restart,虽然从 checkpoint 恢复,但可能给 asynchronous reflection branch、rubric bank 和 judge-feedback pipeline 引入超过设计中 one-step lag 的 staleness。第二,Gemini Flash 是 cost-effective judge;更强或专门化 judge 可能提升 stage-level credit 与 reflection reward,但会增加成本和延迟。第三,rubric-guided meta-policy 继承 judge/rubric 的偏差风险:不良 criteria 可能强化浅层偏好、biased standards 或 overconfident synthesis,memory 还可能跨任务传播这些错误。
Overall conclusion:RubricEM 证明了在没有 verifiable rewards 的开放式 deep research 任务中,显式 rubric interface 可以同时用于结构化 policy、细粒度 credit assignment 和 experience reuse;最终 8B model 在四个 long-form benchmark 上平均 55.5,超过可比开源模型,并通过 ablation 支持 structure、assign、evolve 三个组件的互补性。