Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Paper: arXiv:2512.24873 Code: alibaba/ROLL;alibaba/terminal-bench-pro Code reference:
alibaba/ROLL main@c09bc8bc (2026-05-11);alibaba/terminal-bench-pro main@874af409 (2026-04-01)
1. Motivation (研究动机)
当前 agentic coding / agentic crafting 的核心瓶颈不是单次回答能力,而是模型在真实环境中连续“计划—执行—观察—修正”的闭环学习能力不足。论文把问题拆成三层:第一,传统 SFT 多依赖静态人类示范,难覆盖长程工具调用、终端执行、错误恢复和环境反馈;第二,已有 RL 配方常是 ad-hoc 的,面对长 horizon、稀疏延迟奖励和 rollout/training 异步时容易不稳定;第三,开源社区缺少能同时闭合 data generation、agent execution、policy optimization 的端到端 agentic 训练生态。
本文目标是构建一个可复用的 Agentic Learning Ecosystem (ALE),并在其上训练 ROME(ROME is Obviously an Agentic Model)。ALE 不是单一模型或 prompt 框架,而是把 ROLL(后训练/强化学习框架)、ROCK(可隔离的 sandbox 环境管理器)和 iFlow CLI(上下文工程与 agent runtime)接成一个生产级流水线。ROME 则作为这个生态的验证样例:基于 Qwen3-MoE,经过大规模 agentic 数据、CPT、SFT 与 RL 逐级训练。
这个问题值得研究,因为 agent 能力的提升最终取决于是否能从真实执行反馈中学习,而不是只在离线文本上拟合。若训练、环境和部署上下文不一致,模型可能在 benchmark 上有效、在真实 CLI/IDE 工作流中失效;若奖励只在整条 trajectory 末尾给出,token-level credit assignment 又会让长程训练噪声极大。ROME/ALE 的贡献在于把“agent 数据构造—隔离执行—策略优化—生产部署”做成同一闭环,并用 Terminal Bench Pro 检验终端任务上的泛化。
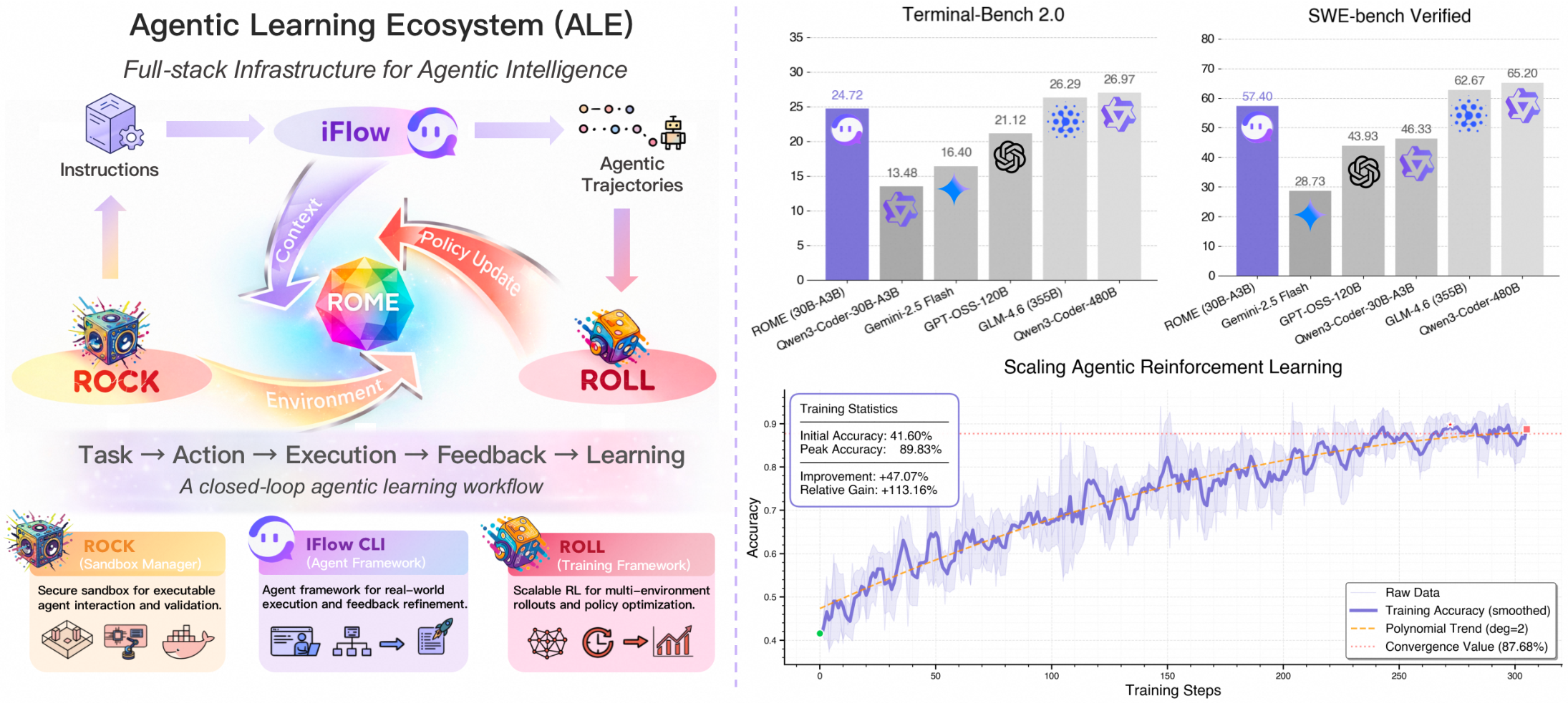
Figure 1 解读:这张总览图把论文的主张压缩成两条线:上半部分是 ALE 的三组件闭环(ROLL/ROCK/iFlow CLI),下半部分是 ROME 在终端、SWE、工具调用和通用 agent benchmark 上的效果。它强调 ROME 的性能不是单独来自某个模型结构,而是来自数据、环境、训练算法和部署框架的一体化。
2. Idea (核心思想)
核心洞察:agentic RL 的自然决策单位不是 token,而是一次语义完整的环境交互 chunk,例如“调用工具并读取结果”“修改文件并运行测试”“基于观察决定下一步”。因此,策略优化也应把 credit assignment、importance sampling、masking 和 rollout curriculum 上移到 interaction chunk 级别,而不是在长达数千 token 的序列上平均处理奖励。
本文的关键创新是把系统工程和算法改造结合起来:ALE 提供可规模化的 agentic 数据和执行基础设施;ROME 训练流水线先用 CPT 建立代码/工具/推理基础,再用 error/task-aware masked SFT 对齐多轮交互,最后用 IPA(Interaction-Perceptive Agentic Policy Optimization)在 chunk 级别做强化学习。与只做 prompt orchestration 或只做单轮 RLVR 的方法相比,ROME 把 agent 的“真实执行状态”纳入训练闭环。
与 PPO/GRPO/普通 REINFORCE 的差别在于:论文先选 REINFORCE 作为工业异步训练的低偏差 baseline,再针对 off-policy inference/training mismatch、稀疏奖励和关键分叉点引入 chunk-level discounted return、chunk-level clipped importance sampling、chunk-level masking,以及从专家/自采样轨迹中间状态继续 rollout 的 Chunk-Level Initialized Resampling。
3. Method (方法)
3.1 ALE:把训练、执行和部署上下文接成闭环
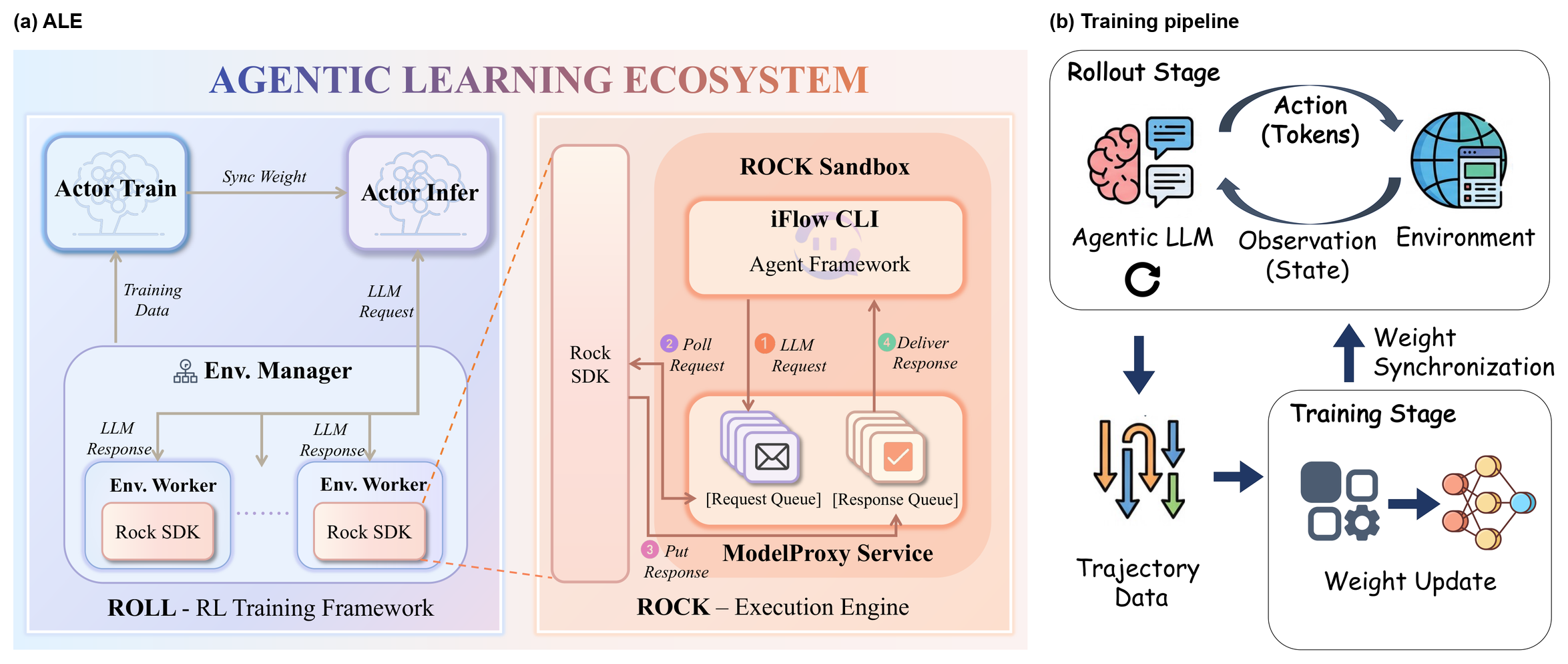
Figure 2 解读:左侧展示 ALE 的系统闭环:ROLL 负责策略训练和 rollout 调度,ROCK 提供可复现的 sandbox 环境,iFlow CLI 负责 agent 侧上下文管理与真实用户接口。右侧展示训练流水线:模型在环境中生成轨迹,ROCK 返回 observation/reward,ROLL 更新权重,再同步到 inference worker 继续采样。
ALE 的系统边界很清晰:ROLL 不重新实现 agent 的复杂上下文拼接逻辑,而是把它交给 iFlow CLI;ROCK 通过隔离环境承载文件系统、终端、web shopping 等任务;ROLL 作为分布式 RL 框架处理 actor_train、actor_infer、reference、critic、reward 等角色。这样做的直觉是:agent 的训练环境越接近部署环境,SFT/RL 学到的行为越不容易在上线时崩掉。
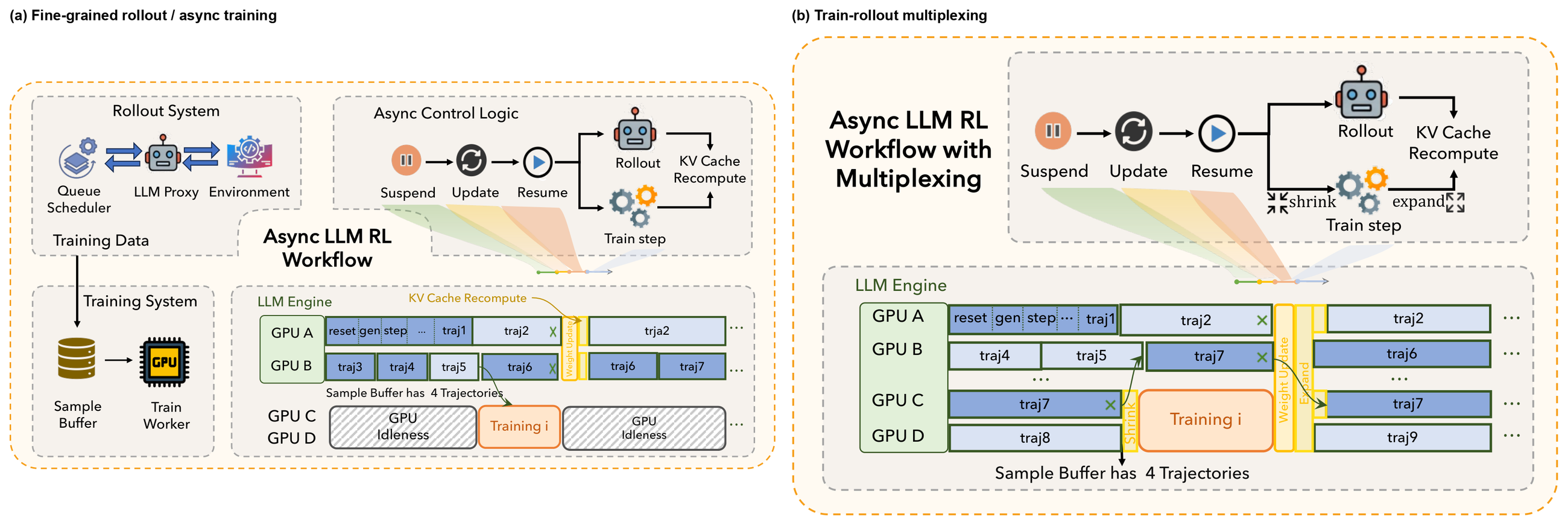
Figure 3 解读:ROLL 的重点是消除 rollout 阶段的系统瓶颈。图 3a 把 rollout 拆成 LLM generation、environment interaction、reward 三个相对独立的阶段,并允许样本级并行;图 3b 说明 train-rollout multiplexing:训练 burst 期间缩小 rollout GPU 池,rollout 高峰时再扩张,减少长尾任务造成的 GPU bubble。
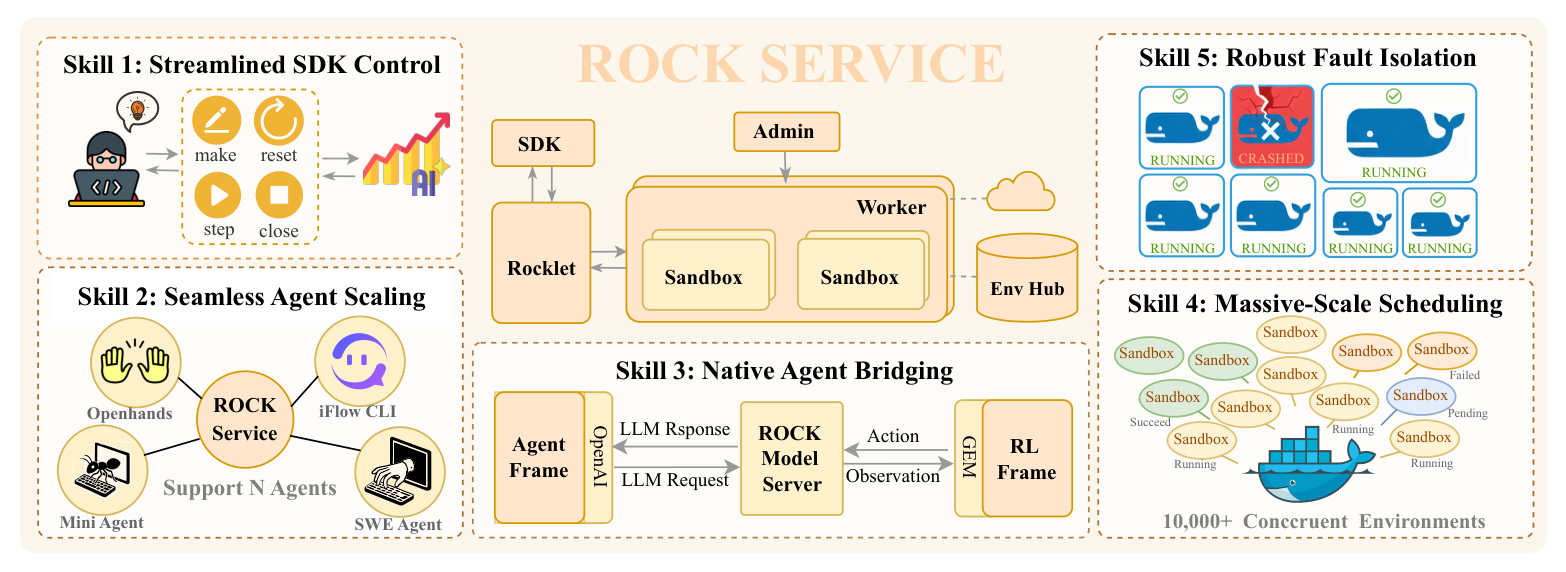
Figure 4 解读:ROCK 负责 sandbox 生命周期管理,抽象出 Make/Reset/Step/Close 这类 GEM API。对 agentic RL 来说,这个组件的价值不只是“能跑代码”,还包括环境隔离、权限控制、任务初始化、执行反馈和验证信号,从而降低 reward hacking 与不可复现环境带来的噪声。
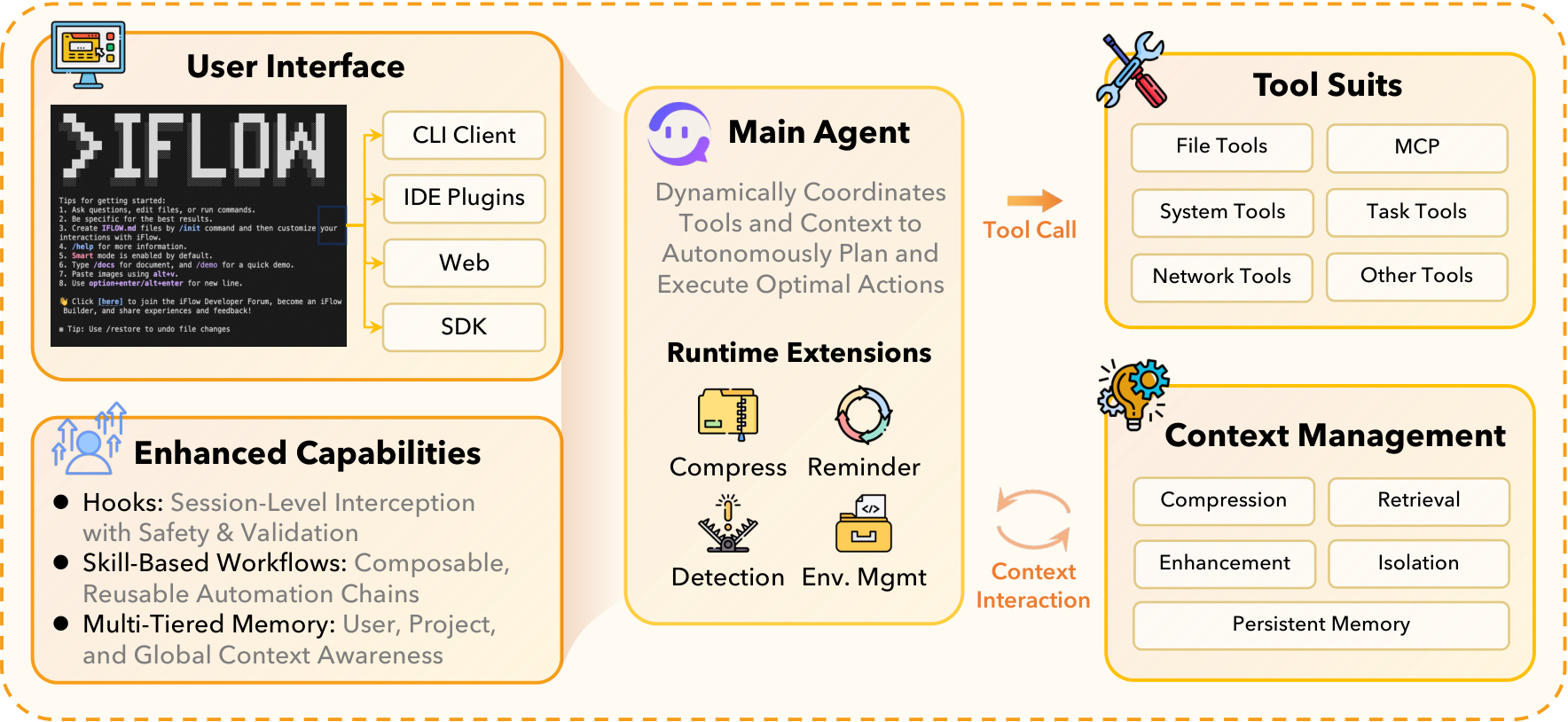
Figure 5 解读:iFlow CLI 在 ALE 中承担真实 agent runtime 的角色。论文特别强调 Agent Native Mode:ROCK 中的 ModelProxyService 拦截 agent sandbox 发出的 LLM 请求,而这些请求已经由 iFlow CLI 编排好完整历史上下文;ROLL 只作为 generation backend。这样训练时的上下文管理与部署时一致,避免“训练框架复刻 CLI 逻辑”带来的维护和分布偏移问题。
3.2 数据:从静态代码到可执行 agent trajectory
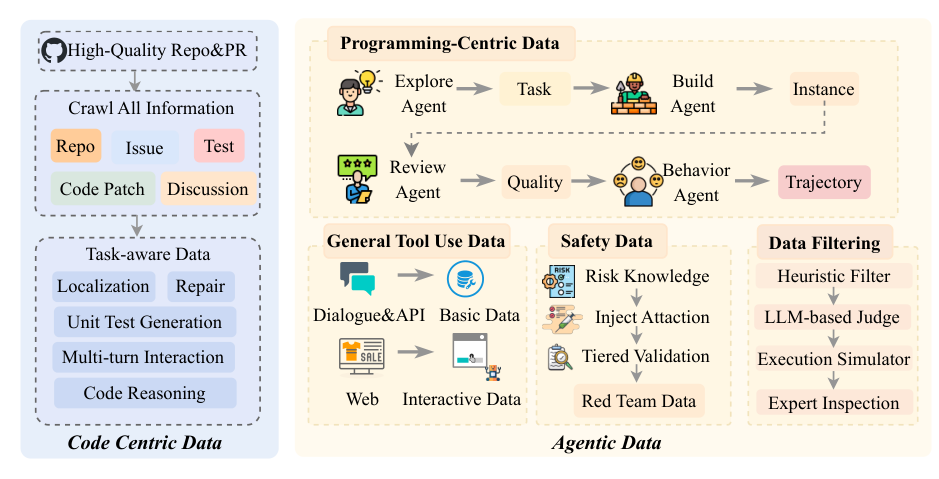
Figure 6 解读:数据部分分为 code-centric basic data 与 agentic data。前者从约一百万个高质量 GitHub 仓库中构造代码理解、定位、修复、测试生成等基础能力数据;后者把任务 prompt、Docker/build/test 环境、unit tests 与 agent 多轮行为轨迹打包为 instance/trajectory,使模型学习“观察反馈后继续修正”的闭环行为。
论文报告的关键数据规模如下:CPT Stage I 使用约 500B tokens 的结构化代码任务、一般推理与工具使用数据;Stage II 使用约 300B tokens 的合成行为轨迹,由强 teacher(如 Qwen3-Coder-480B-A35B-Instruct、Claude)在 sandbox 中生成。agentic 数据合成还包括 76K instances / trajectory records,总计 30B tokens;RL 候选集约 60K 个高质量候选实例,最终保留约 2K 个中等难度、结果可验证的 RL instances。
3.3 ROME 训练流水线:CPT → masked SFT → IPA RL
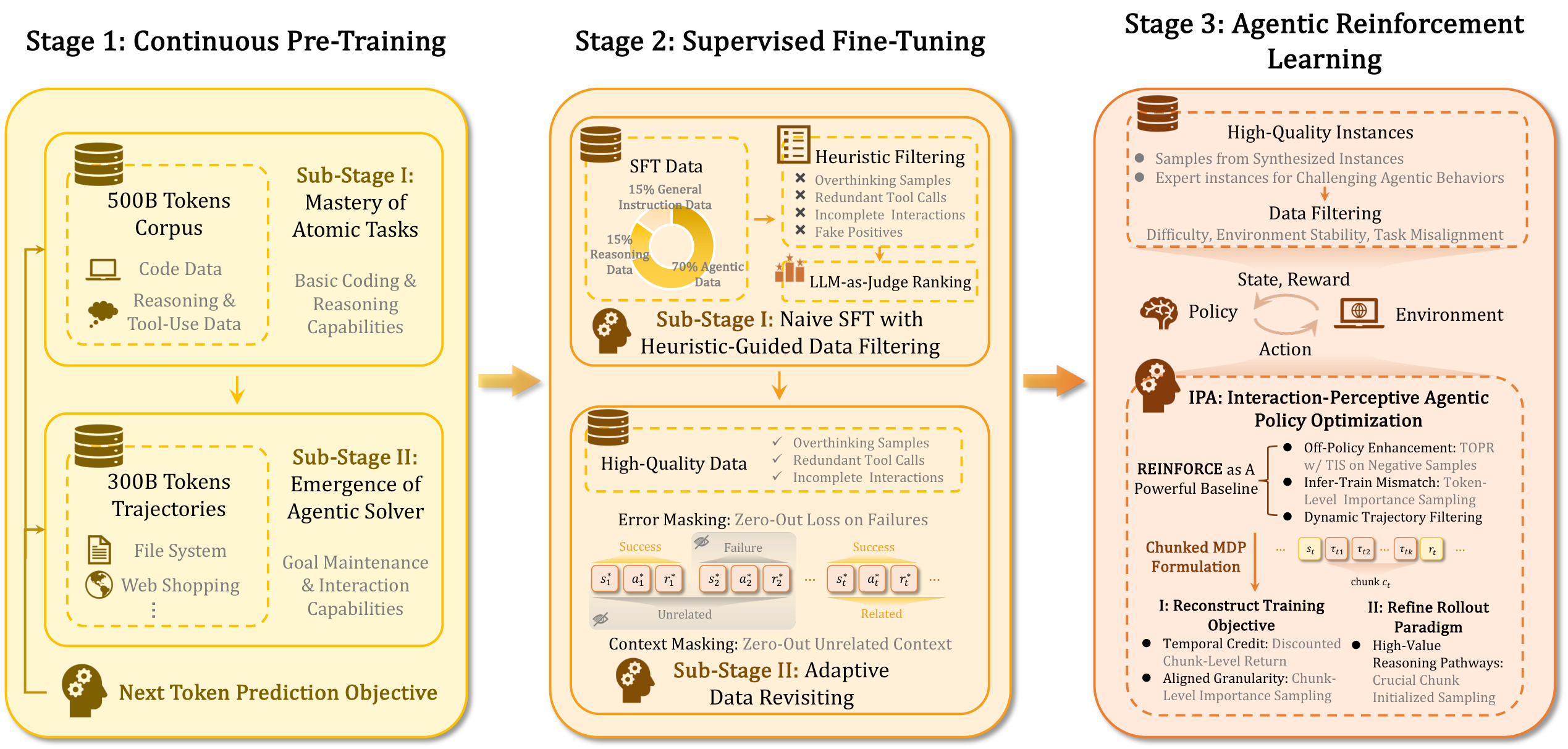
Figure 7 解读:ROME 的训练不是直接上 RL。Stage I CPT 建立代码语义和基础工具行为;Stage II CPT 让模型从 teacher 轨迹中形成 agentic solver;随后 SFT 通过 error masking 和 task-aware context masking 避免错误 turn 和不相关历史污染梯度;最后 IPA 在可验证实例上进行 chunk-level RL。
CPT 的论文报告配置:Stage I 采用 next-token prediction,global batch size 为 32M tokens,constant learning rate 为 ;Stage II 沿用 Stage I 超参,但将 weight decay 从 0.1 线性退火到 0.01。公开 ROLL 仓库没有 ROME 的精确 launch config,因此这些训练数值在本笔记中标为 paper-reported;code-verified 的 ROLL 示例配置另见下方 code mapping。
SFT 的核心是 interaction-level mask。给定多轮轨迹 ,论文写成:
其中
直觉上, 屏蔽执行失败、超时、语法错误等 turn, 屏蔽与当前子任务无关或被压缩/裁剪导致上下文分布不一致的历史 turn。
3.4 IPA:把 RL 优化单位从 token 改成 interaction chunk
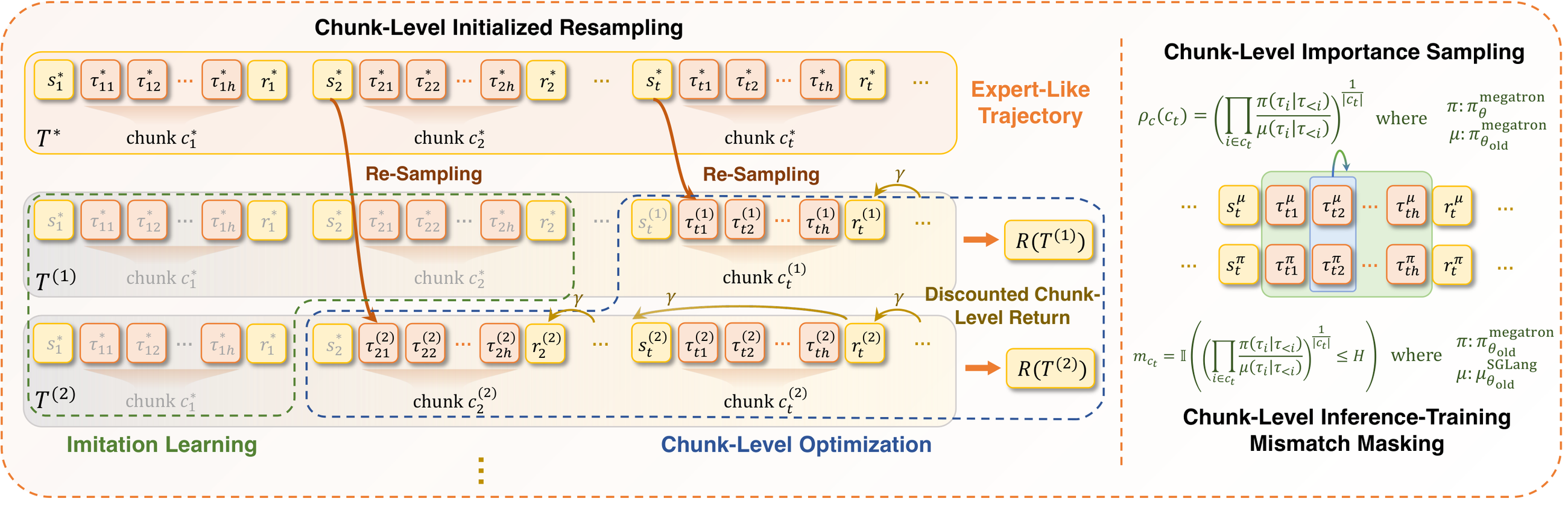
Figure 8 解读:IPA 的训练 pipeline 先从可验证 RL instance 中 rollout 多轮 trajectory,再按 environment interaction 边界切成 chunk。每个 chunk 汇聚一段连续 token 与其造成的环境状态转移,随后在 chunk 级计算 return、importance ratio、mask 和 resampling curriculum。
REINFORCE baseline 为:
为了适配异步 off-policy agentic training,论文先用 SGLang inference policy 产生轨迹,再用 Megatron training policy 更新。token/trajectory 级的 IS 在长轨迹上会过细或过粗,因此 IPA 定义 chunk-level ratio:
chunk-level discounted return 写作:
其中 是当前 chunk 到最终奖励相关 chunk 的距离。最终 Chunk-RL 梯度把正例 chunk 做 weighted supervised-like update,把负例 chunk 做 clipped IS update:
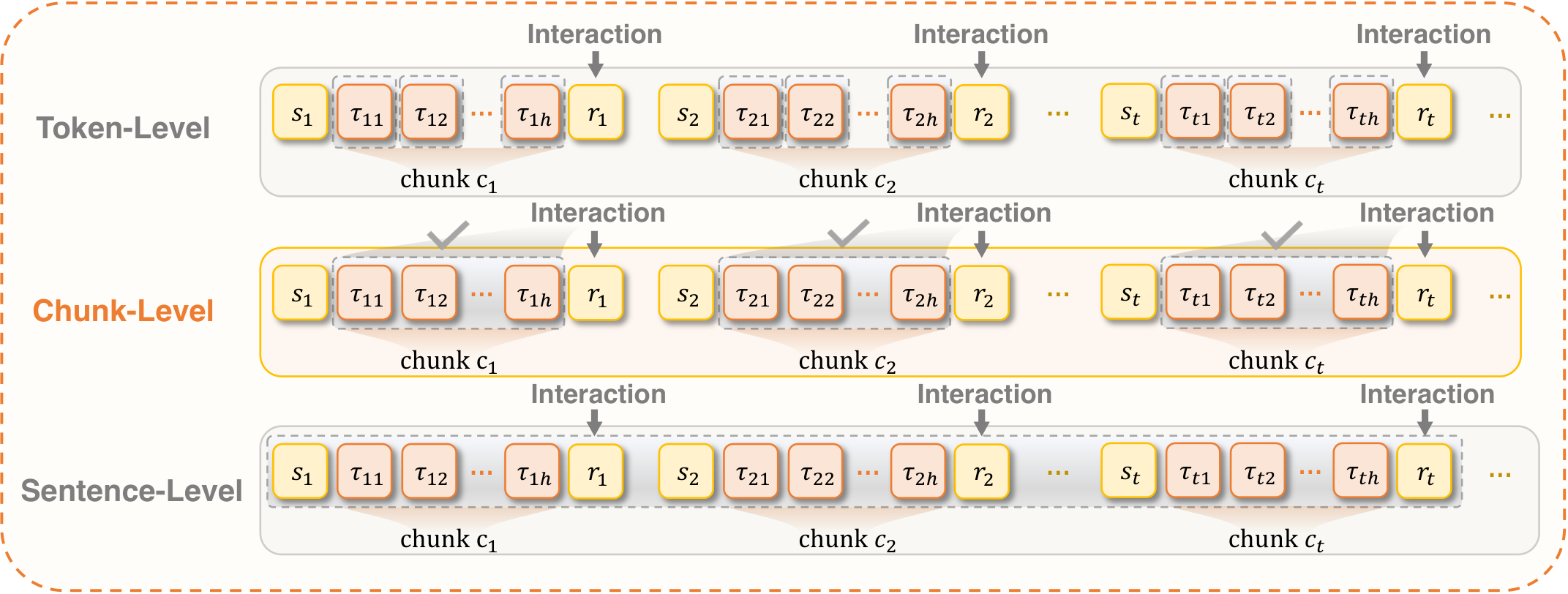
Figure 9 解读:图中对比 token-level、sentence-level 和 chunk-level importance sampling。token-level 与环境奖励粒度错配,sentence-level 又未必对应一次真实环境转移;chunk-level 刚好对应 agent action/observation 的自然边界,因此更适合长程 agentic credit assignment。
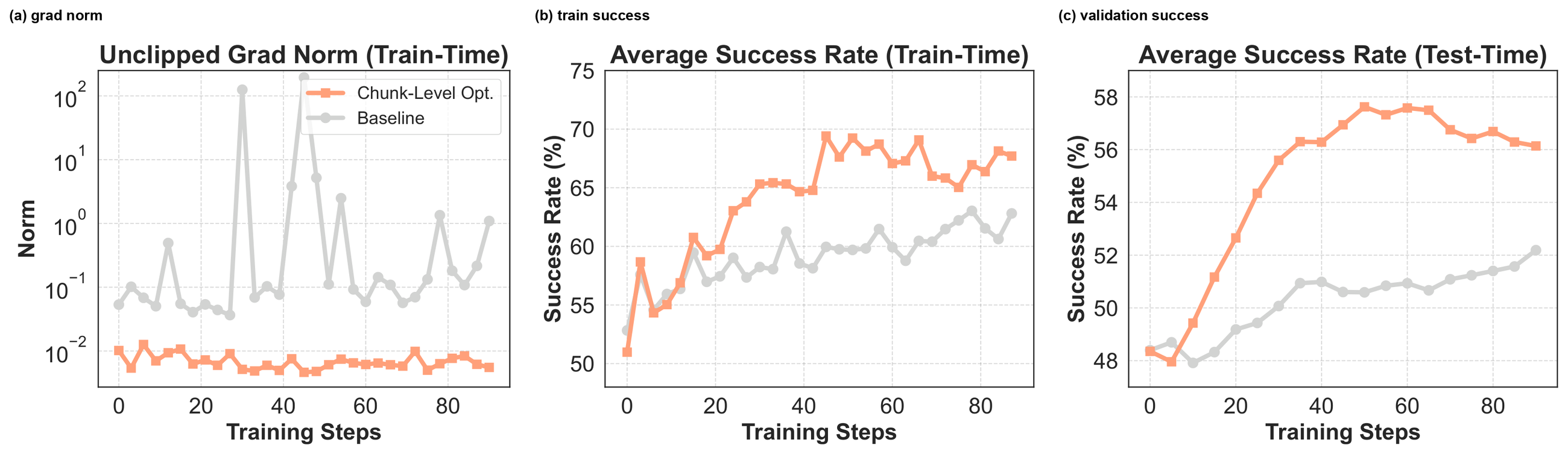
Figure 10 解读:该消融比较 chunk-level optimization 和 baseline。在 mini training set 上,chunk-level 版本在梯度/训练成功率/验证成功率曲线中更稳定,说明 chunk 粒度能把稀疏最终奖励映射回真正导致环境变化的交互段,而不是让所有 token 均摊同一个 outcome reward。
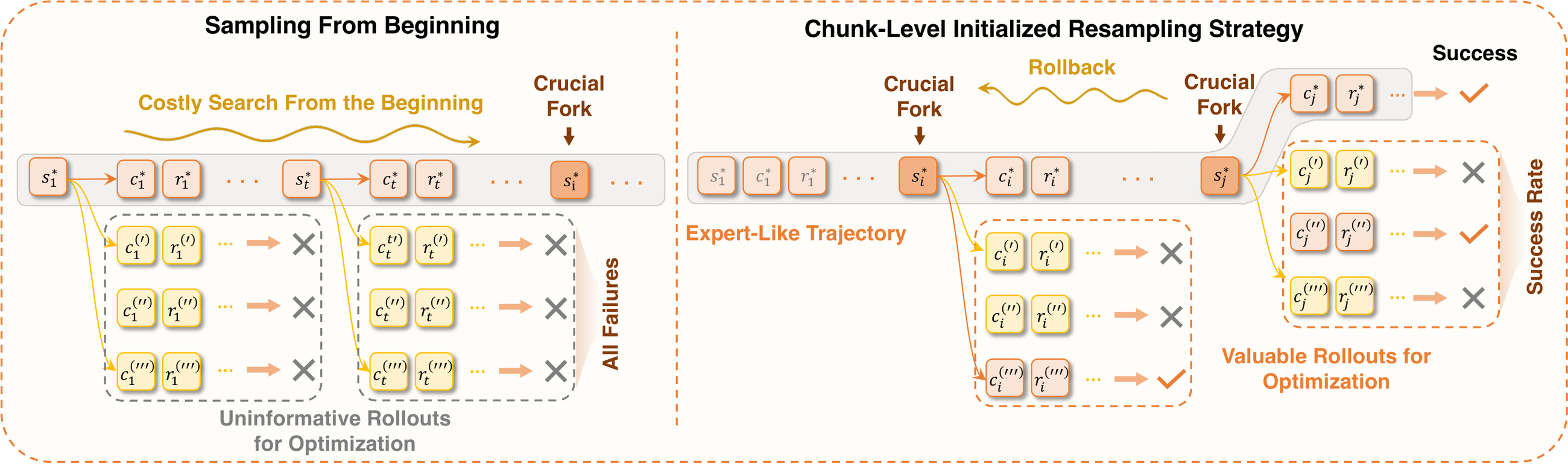
Figure 11 解读:Chunk-Level Initialized Resampling 的关键不是从初始状态一遍遍失败,而是从专家或自采样轨迹中的关键 fork 之后继续采样。模型先学会 tail chunk,再逐步 rollback 到更早的关键分叉点,形成 chunk-level curriculum。
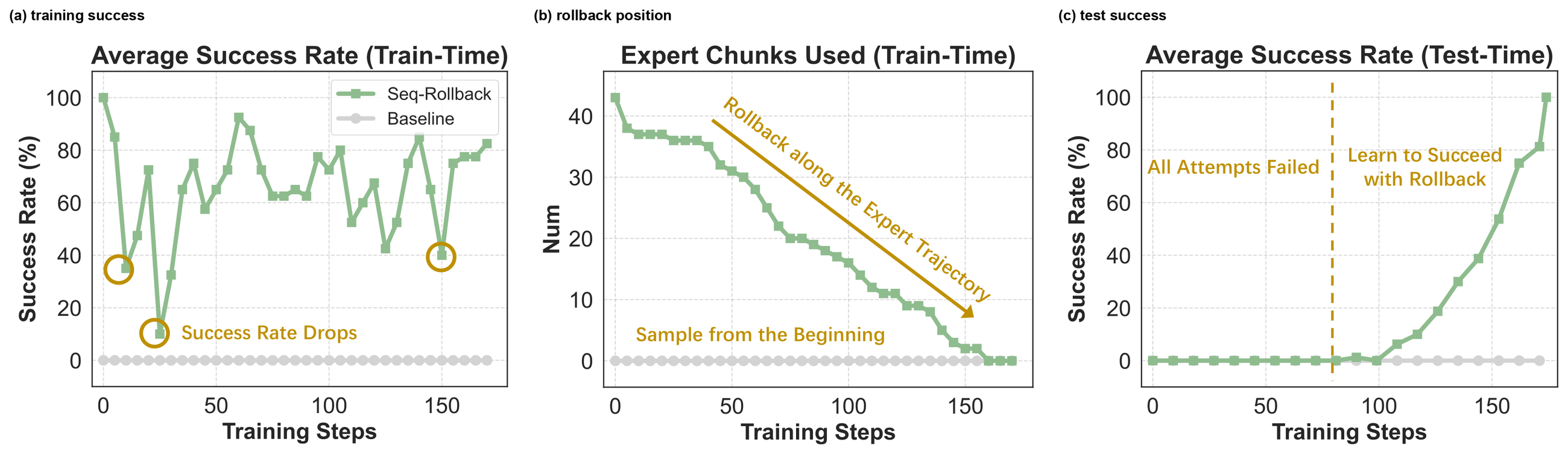
Figure 12 解读:Sequential Rollback 在挑战性任务上带来更多正向训练信号。左图展示训练 batch 中成功轨迹比例,baseline 几乎全失败;中图显示 rollback 点沿专家轨迹前移;右图显示即使 test-time 从初始状态采样,rollback 训练也能在 step 75 后打开与 baseline 的性能差距。
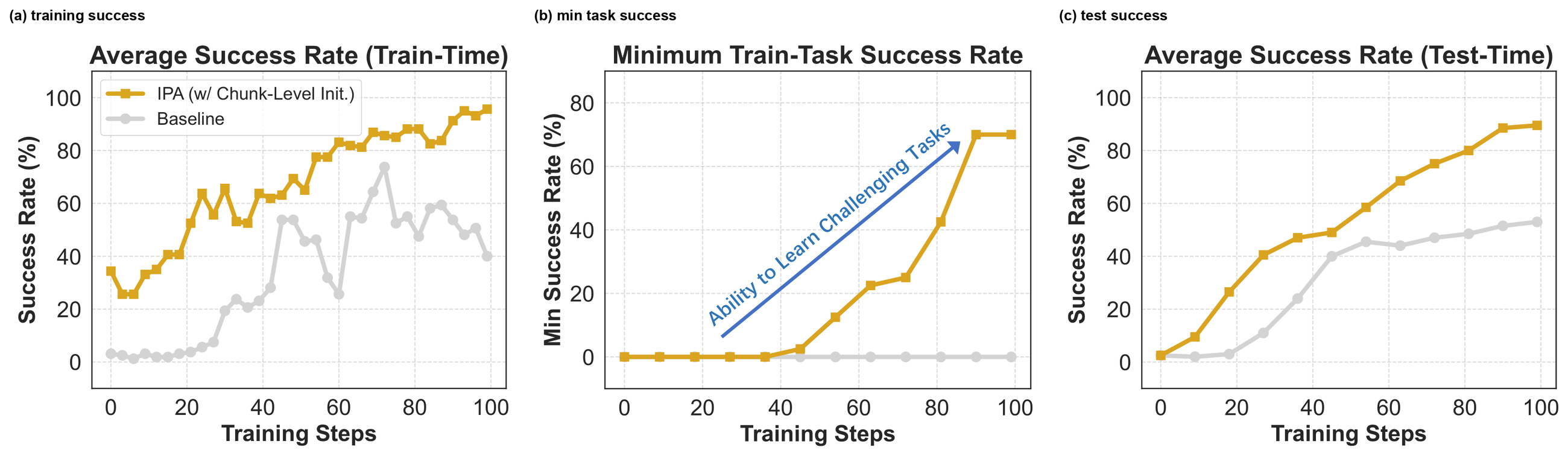
Figure 13 解读:Parallelized Initialization 的消融展示了 IPA with/without initialized resampling 的差异。早期训练成功率差距说明 initialized resampling 提供更丰富奖励信号;minimum success rate 的改善说明极难任务也能通过 curriculum 被学到;test-time 平均成功率提升说明这种中间状态训练没有只过拟合 tail,而能回到初始状态完成任务。
3.5 伪代码
import torch
import torch.nn.functional as F
def masked_sft_loss(policy, trajectory, eps=1e-8):
"""Paper §3.2.2: error-masked + task-aware context masked SFT."""
total_loss, total_tokens = 0.0, 0.0
for state_k, response_k, meta_k in trajectory.turns:
err_mask = 0.0 if meta_k["tool_error"] or meta_k["timeout"] else 1.0
task_mask = 1.0 if meta_k["relevant_to_current_subtask"] else 0.0
m_k = err_mask * task_mask
logp = policy.log_prob(response_k, context=state_k) # sum over turn tokens
total_loss = total_loss - m_k * logp
total_tokens = total_tokens + m_k * len(response_k.input_ids)
return total_loss / (total_tokens + eps)def chunkify_agent_trajectory(turns):
"""Split trajectory at semantic environment-interaction boundaries."""
chunks, current = [], []
for token_or_event in turns:
current.append(token_or_event)
if token_or_event.type in ('tool_result', 'terminal_observation', 'env_step_done'):
chunks.append(current)
current = []
if current:
chunks.append(current)
return chunks
def chunk_discounted_returns(chunks, final_reward, gamma=0.95):
returns = []
last = len(chunks) - 1
for k, _chunk in enumerate(chunks):
returns.append((gamma ** (last - k)) * final_reward)
return torch.tensor(returns, dtype=torch.float32)def ipa_chunk_rl_loss(policy, old_train_policy, inference_policy, chunks, final_reward, H=10.0):
"""Chunk-level weighted SL for positive chunks + clipped IS for negative chunks."""
returns = chunk_discounted_returns(chunks, final_reward)
losses = []
for c, G_c in zip(chunks, returns):
logp = policy.log_prob(c)
old_logp = old_train_policy.log_prob(c).detach()
infer_prob = inference_policy.prob(c).detach()
rho_c = torch.exp((logp.detach() - old_logp) / max(len(c), 1))
mask_c = (rho_c <= H).float()
if final_reward > 0:
losses.append(-infer_prob * G_c * mask_c * logp)
else:
losses.append(-infer_prob * torch.clamp(rho_c, 0.0, 1.0) * G_c * mask_c * logp)
return torch.stack(losses).mean()def chunk_initialized_resampling(policy, env, expert_chunks, fork_schedule):
"""Start rollouts from selected expert-like chunks, then roll back toward earlier forks."""
trajectories = []
for fork_idx in fork_schedule: # e.g. tail -> middle -> head
env.reset()
for chunk in expert_chunks[:fork_idx]:
env.replay(chunk) # prefill correct interaction history
traj = []
done = False
while not done:
action_chunk = policy.generate_next_chunk(env.context())
obs, reward, done, info = env.step(action_chunk)
traj.append((action_chunk, obs, reward, info))
trajectories.append(traj)
return trajectoriesCode reference:
alibaba/ROLL main@c09bc8bc (2026-05-11);alibaba/terminal-bench-pro main@874af409 (2026-04-01)— pseudocode and mapping based on these commits.
Code-to-paper mapping
- ROLL agentic training loop:
roll/pipeline/agentic/agentic_pipeline.py中AgenticPipeline(line 52)和run()(line 208)对应论文图 2/3 的 actor_train → actor_infer 权重同步、validation rollout、training rollout、reference/old log prob、advantage、actor/critic update。代码中的 phase 7/11/12/13/14 分别对应 rollout batch、reference log probs、old log probs、advantage computation、training。 - 环境并行 rollout:
roll/pipeline/agentic/environment_worker.py中EnvironmentWorker(line 23)和run_rollout_loop()(line 95)对应 ROCK/环境交互侧;代码把一个 worker 下的多个 env manager 放进ThreadPoolExecutor,与论文 “fine-grained rollout / sample-level parallelism” 对齐。 - policy-gradient loss variants:
roll/pipeline/agentic/agentic_actor_pg_worker.py中loss_func()(line 29)、_compute_ppo_loss()(line 150)、_compute_vanilla_pg_loss()(line 200)、_compute_tis_loss()(line 214)、_compute_topr_loss()(line 260)、_compute_cispo_loss()(line 351)对应论文讨论的 REINFORCE / clipped IS / off-policy correction 家族。注意:公开 ROLL 当前代码未直接暴露论文命名的IPA类或 ROME 专用训练脚本。 - ROCK native integration:
roll/pipeline/agentic/env/sandbox/rock_tb_native_env.py、roll/pipeline/agentic/env/rock/sandbox_manager_v2.py、roll/pipeline/agentic/env/rock/agent_manager.py以及docs_roll/docs/Getting Started/Quick Start/rock_agent_native.md对应 Agent Native Mode、sandbox 管理和 ROCK service 连接。 - 可复现 benchmark:
alibaba/terminal-bench-pro公开 repo 包含 200 个 publictask.toml任务目录;README 声明完整 Terminal-Bench Pro 为 400 tasks(200 public + 200 private)、8 domains、平均约 28.3 test cases/task。该 repo 对应论文中的 Terminal Bench Pro benchmark,而不是 ROME 模型权重或 IPA 训练实现。
论文公式与 released code 实现差异:论文给出 IPA 的 chunk-level return / ratio / masking / initialized resampling 公式,但当前公开 alibaba/ROLL 仓库在本次检索到的 main@c09bc8bc 中没有名为 IPA 的专用实现;换言之,public ROLL 当前代码未直接暴露论文命名的 IPA或 ROME 精确 launch config;因此本笔记的 IPA 伪代码按论文公式写成,code mapping 只锚定到 ROLL 中已公开的 agentic pipeline、loss variants、ROCK integration 和 Terminal-Bench-Pro benchmark。
Code-verified ROLL 示例配置(非 ROME exact config)
- Config path:
examples/qwen2.5-7B-agentic_megatron/agentic_val_webshop_gigpo.yaml - Pipeline scale:
num_gpus_per_node=8,max_steps=1024,rollout_batch_size=64,val_batch_size=64,sequence_length=8192,eval_steps=10。 - Algorithm knobs:
adv_estimator="gigpo",step_reward_gamma=0.95,reward_clip=20,advantage_clip=0.2,ppo_epochs=1,use_kl_loss=true,kl_loss_coef=0.01。 - Actor train:
learning_rate=1.0e-6,weight_decay=0,per_device_train_batch_size=1,gradient_accumulation_steps=8,warmup_steps=10, Megatron strategy,device_mapping=list(range(0,8))。 - Actor infer: vLLM strategy,
max_new_tokens=1024,top_p=0.99,top_k=100,temperature=0.99,num_return_sequences=1。
4. Experimental Setup (实验设置)
数据集与规模
- CPT 数据:Stage I 约 500B tokens,覆盖结构化代码任务、Issue/PR 派生的定位/修复/测试生成、一般推理和工具使用;Stage II 约 300B tokens,由强 teacher 在 sandbox 中生成合成行为轨迹。
- Agentic data synthesis:约 76K instances / trajectory records,总计 30B tokens;instance 包含 task specification、Dockerfile、build/test commands、unit tests;trajectory 记录工具调用、文件编辑、环境反馈和错误恢复。
- RL instances:约 60K 高质量候选 RL instances,按多模型和 SFT 模型的 pass rate 估计难度后,保留约 2K 个中等难度、可验证、环境稳定的实例。
- Terminal Bench Pro:400 evaluation tasks,其中 200 public + 200 private,均匀分布在 8 个 domains;公开 GitHub repo 当前包含 200 个 public task directories。
Baselines
论文比较了 ROME(30B MoE,3B activated)与标准模型和大模型两组 baseline。标准组包括 Qwen3-Coder30B-A3B-Instruct、Devstral 2、GPT-OSS-120B、Gemini-2.5、GLM-4.5、GPT-5 Mini;大模型组包括 Qwen3-Coder Plus、Qwen3-Coder480B-A35B-Instruct、DeepSeek3.1、GLM-4.6、Kimi-2、Claude-Haiku-4.5。
Metrics
- Terminal-based execution:Terminal-Bench 1.0/2.0、SWE-Bench Verified、SWE-Bench Multilingual、Terminal-Bench-Pro Public/Private,主要报告 pass/success score。
- Tool-use:TAU2-Bench Retail/Airline/Telecom、BFCL-v3 Multi-Turn、MTU-Bench Single/Multi-Turn,衡量工具选择、调用和多轮协调。
- General agentic:GAIA、BrowseComp-ZH、ShopAgent Single/Multi-Turn,衡量多步推理、开放环境决策和交互式任务完成。
- RL ablation:训练成功率、minimum task success、test-time average success、sequential rollback 位置和成功曲线。
训练配置与可复现性边界
论文明确给出 CPT 的 global batch size 32M tokens、learning rate ,Stage II weight decay 从 0.1 退火到 0.01;ROME 总参数/激活参数为 30B/3B。论文未在正文中给出 GPU 型号/数量、完整 ROME launch script、IPA exact implementation file;公开代码检索找到的是 ROLL 框架与 Terminal-Bench-Pro benchmark。为避免把默认配置误认为 ROME 配置,本笔记只把上述数值标为 paper-reported,并单独列出 code-verified 的 ROLL 示例配置。
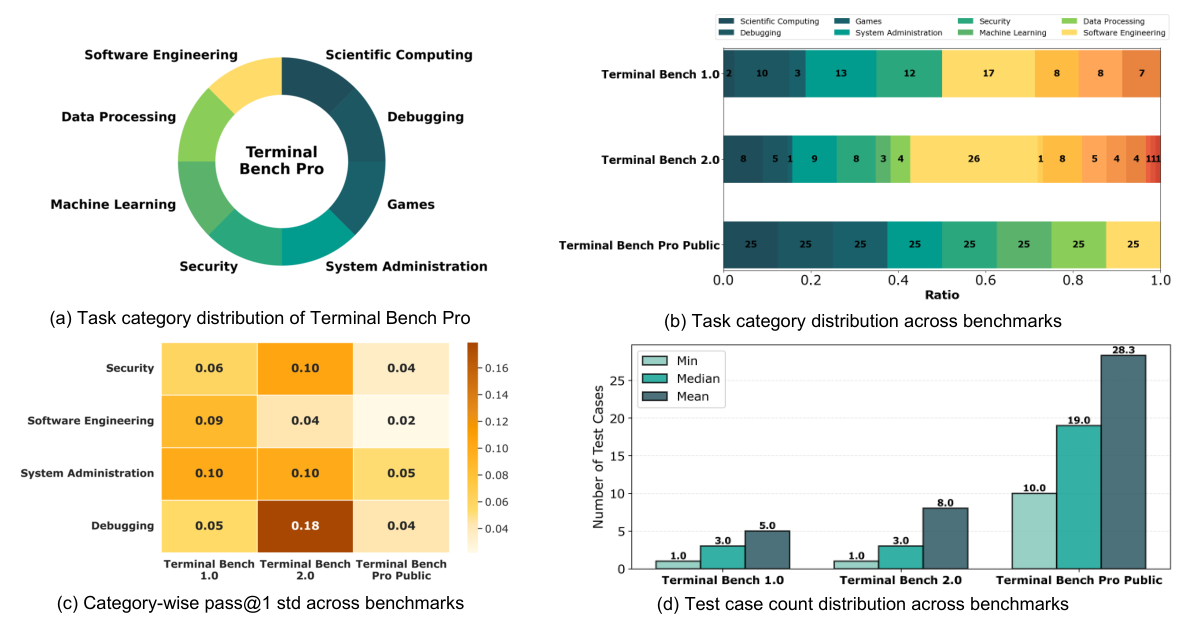
Figure 14 解读:Terminal Bench Pro 针对原 Terminal Bench 规模小、类别覆盖不均、环境方差和 contamination 控制不足的问题扩展。论文指出 Terminal Bench 1.0 只有 80 tasks,2.0 也只有 89 tasks;Terminal Bench Pro 扩展到 400 tasks,并平衡 8 个 domains,使分领域分析更稳定。
5. Experimental Results (实验结果)
Terminal-based benchmarks
标准模型组中,ROME 的 Terminal-Bench 1.0 为 41.50、Terminal-Bench 2.0 为 24.72、SWE-Bench Verified 为 57.40、SWE-Bench Multilingual 为 40.00、Terminal-Bench-Pro-Public 为 40.50、Terminal-Bench-Pro-Private 为 21.50,平均 37.60。对比同为 30B/3B 的 Qwen3-Coder30B-A3B-Instruct,ROME 平均从 25.94 提升到 37.60;在 SWE-Bench Verified 上从 46.33 到 57.40。
大模型组中,ROME 的平均 37.60 低于 Claude-Haiku-4.5 的 48.84、Qwen3-Coder Plus 的 43.36、GLM-4.6 的 42.45,但 ROME 只有 30B total / 3B activated;在 Terminal-Bench 1.0 上 ROME 41.50 接近或超过 Qwen3-Coder Plus 39.58、Qwen3-Coder480B-A35B-Instruct 37.92、DeepSeek3.1 38.75、Kimi-2 39.25,显示较强的参数效率。
Tool-use benchmarks
标准模型组中,ROME 在 TAU2-Bench Retail/Airline/Telecom 分别为 62.28 / 50.50 / 30.92,BFCL-v3 Multi-Turn 为 43.00,MTU-Bench Single/Multi-Turn 为 62.45 / 47.63,平均 49.46。这低于 GLM-4.5 58.78 和 GPT-5 Mini 58.38,但高于 Qwen3-Coder30B-A3B-Instruct 40.87、Devstral 2 39.35、Gemini-2.5 43.82。
大模型组中,ROME 的 tool-use 平均 49.46,低于 GLM-4.6 61.12、Kimi-2 60.52、Claude-Haiku-4.5 53.56 和 Qwen3-Coder480B-A35B-Instruct 51.11,但在 MTU-Bench Single-Turn 上达到 62.45,与 480B 级 Qwen3-Coder 的 63.87 接近。
General-agent benchmarks
标准模型组中,ROME 在 GAIA/BrowseComp-ZH/ShopAgent Single/ShopAgent Multi 上分别为 24.24 / 14.19 / 34.53 / 29.61,平均 25.64。这个平均值高于 Qwen3-Coder30B-A3B-Instruct 15.69、Devstral 2 16.30、GPT-OSS-120B 23.40、Gemini-2.5 22.66、GLM-4.5 24.78,但低于 GPT-5 Mini 35.59。
大模型组中,ROME 平均 25.64 高于 Qwen3-Coder Plus 23.99 和 Qwen3-Coder480B-A35B-Instruct 23.88,低于 DeepSeek3.1 32.16、GLM-4.6 29.00、Kimi-2 26.75、Claude-Haiku-4.5 32.51。结果说明 ROME 的优势更集中在终端执行和中等规模参数效率,而不是所有通用 agent benchmark 全面领先。
Ablation findings
IPA 的消融结论集中在三点:第一,chunk-level optimization 相比 token/trajectory 级 baseline 更稳定,能在 mini training set 上改善训练和验证成功曲线;第二,sequential rollback 能在极难任务中制造更多正奖励信号,避免 naive sampling 长时间全失败;第三,parallelized initialized resampling 在训练早期显著提高成功轨迹密度,并改善 test-time average success。论文没有把这些曲线全部转成表格数字,因此本笔记保留图解而不臆造数值。
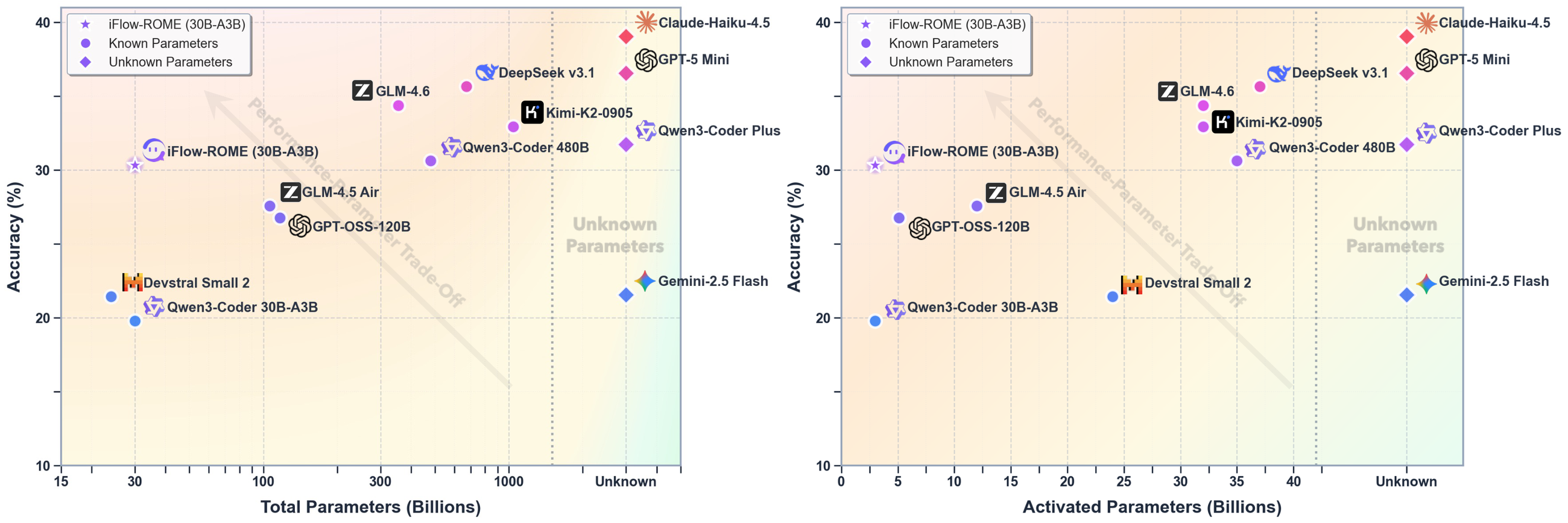
Figure 15 解读:性能-参数图说明 ROME 的定位:它不是用最大参数规模碾压,而是在 30B total / 3B activated 的 MoE 规模下取得接近或超过若干更大模型的 agentic/code-agent 平均表现。该图支持论文“ALE + IPA 提升参数效率”的论点,但也显示专有大模型在总体平均上仍领先。
Limitations
论文没有公开 ROME 权重、完整 ROME launch config 或 IPA 的独立开源实现;当前可验证公开代码主要是 ROLL 框架与 Terminal-Bench-Pro benchmark。实验上,ROME 在 Terminal-Bench-Pro-Private (21.50) 明显低于 GPT-5 Mini (29.50) 和 Claude-Haiku-4.5 (35.33),在 tool-use 大模型组平均也不占优;因此它的贡献更应理解为一个可扩展 agentic 训练生态和 chunk-level RL 方向,而非所有 agent benchmark 的绝对 SOTA。