Memory in the Age of AI Agents: A Survey
Authors: Yuyang Hu, Shichun Liu, Yanwei Yue, Guibin Zhang, Boyang Liu, Fangyi Zhu, Jiahang Lin, Honglin Guo, Shihan Dou, Zhiheng Xi, Senjie Jin, Jiejun Tan, Yanbin Yin, Jiongnan Liu, Zeyu Zhang, Zhongxiang Sun, Yutao Zhu, Hao Sun, Boci Peng, Zhenrong Cheng, Xuanbo Fan, Jiaxin Guo, Xinlei Yu, Zhenhong Zhou, Zewen Hu, Jiahao Huo, Junhao Wang, Yuwei Niu, Yu Wang, Zhenfei Yin, Xiaobin Hu, Yue Liao, Qiankun Li, Kun Wang, Wangchunshu Zhou, Yixin Liu, Dawei Cheng, Qi Zhang, Tao Gui, Shirui Pan, Yan Zhang, Philip Torr, Zhicheng Dou, Ji-Rong Wen, Xuanjing Huang, Yu-Gang Jiang, Shuicheng Yan 等 47 位作者 Affiliations: National University of Singapore, Renmin University of China, Fudan University, Peking University, Nanyang Technological University, Tongji University, UC San Diego, Hong Kong University of Science and Technology (Guangzhou), Griffith University, Georgia Institute of Technology, OPPO, Oxford University arXiv: 2512.13564 GitHub: Shichun-Liu/Agent-Memory-Paper-List
1. Motivation (研究动机)
- Agent Memory 研究碎片化严重:随着基于 foundation model 的 AI agent 研究迅速扩展,agent memory 领域涌现了大量工作,但这些工作在动机、实现、假设和评估协议上存在显著差异,术语定义松散,导致概念混乱。
- 现有分类体系不足:传统的 long-term/short-term memory 二分法无法捕捉当代 agent memory 系统的多样性和动态性。2025 年涌现的新方向(如从经验中蒸馏可复用工具的 memory 框架、memory-augmented test-time scaling 方法)在早期分类方案中被严重忽视。
- 概念边界模糊:Agent Memory 与 LLM Memory、RAG (Retrieval-Augmented Generation)、Context Engineering 等相关概念经常被混淆,研究者和实践者难以准确定位自己的工作。
- 缺乏统一框架:需要一个系统性框架来调和现有定义、桥接新兴趋势、阐明 memory 在 agentic 系统中的基础原理,为未来研究提供清晰的概念基础。
2. Idea (核心思想)
本综述提出了一个 “Forms–Functions–Dynamics” 三维统一分类体系 来组织和理解 agent memory 研究:
- Forms(形式):memory 的载体是什么?—— Token-level Memory、Parametric Memory、Latent Memory
- Functions(功能):agent 为什么需要 memory?—— Factual Memory、Experiential Memory、Working Memory
- Dynamics(动态):memory 如何运作和演化?—— Memory Formation、Memory Evolution、Memory Retrieval
与现有综述的根本区别在于:不再简单地按 long-term/short-term 划分,而是从 表示形式、功能目的、生命周期动态 三个正交维度全面刻画 agent memory,将其定位为 agentic 系统的 一等公民(first-class primitive),而非简单的辅助存储模块。
3. Method (方法)
3.1 整体框架
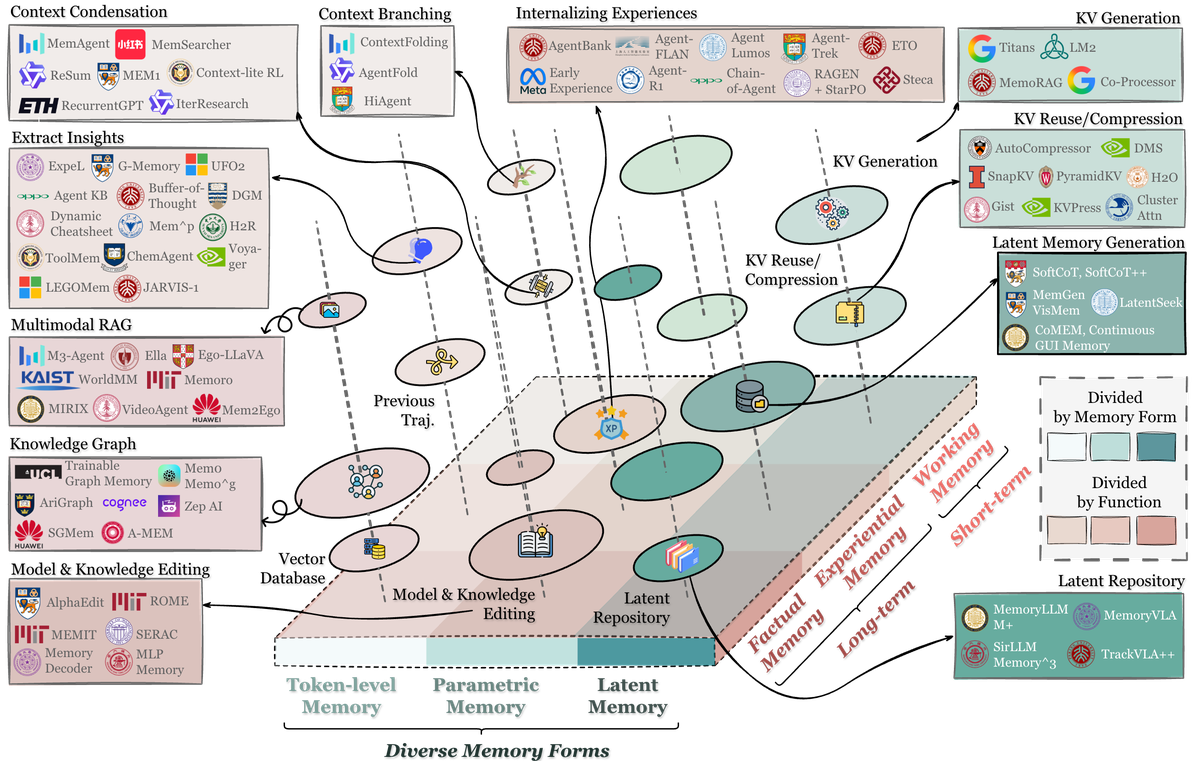
Figure 1 解读:此图展示了 agent memory 的统一分类体系全景。底部是三种 memory forms(Token-level、Parametric、Latent Memory),中部通过”Forms–Functions–Dynamics”三角将 memory 按其主要形式和功能进行定位,上方和四周分布着代表性系统(如 MemGPT、Reflexion、MemoryLLM 等)。右侧展示了按功能(Factual/Experiential/Working Memory)和按形式(Divided by Memory Form)的分类视角,以及 Latent Repository 的代表系统。该图将整个领域的核心概念和代表方法整合到一个统一的可视化框架中。
3.2 Agent Memory 与相关概念的区分

Figure 2 解读:此 Venn 图展示了 Agent Memory 与 LLM Memory、RAG、Context Engineering 四个概念之间的关系。Agent Memory 独特地关注 持久的、自我演化的认知状态,整合事实知识和经验知识;LLM Memory 侧重模型内部的架构优化(如 attention management、long context processing);RAG 聚焦于静态知识访问;Context Engineering 关注瞬态资源管理。四者存在交叉区域(如 Memory Graph、KV compression/reuse、Few-shot prompting),但 Agent Memory 的核心特征在于跨任务持久性和环境驱动的自适应演化。
形式化定义:
- Agent 集合 ,环境状态空间 ,状态转移
- Agent 策略:,其中 为 memory 信号, 为任务描述
- Memory 系统:,通过三个算子驱动生命周期:
- Formation:(从原始信息中提取 memory 候选)
- Evolution:(整合到现有 memory 库)
- Retrieval:(根据上下文检索 memory)
3.3 Forms:Memory 的承载形式
3.3.1 Token-level Memory(符号化、离散、可编辑)
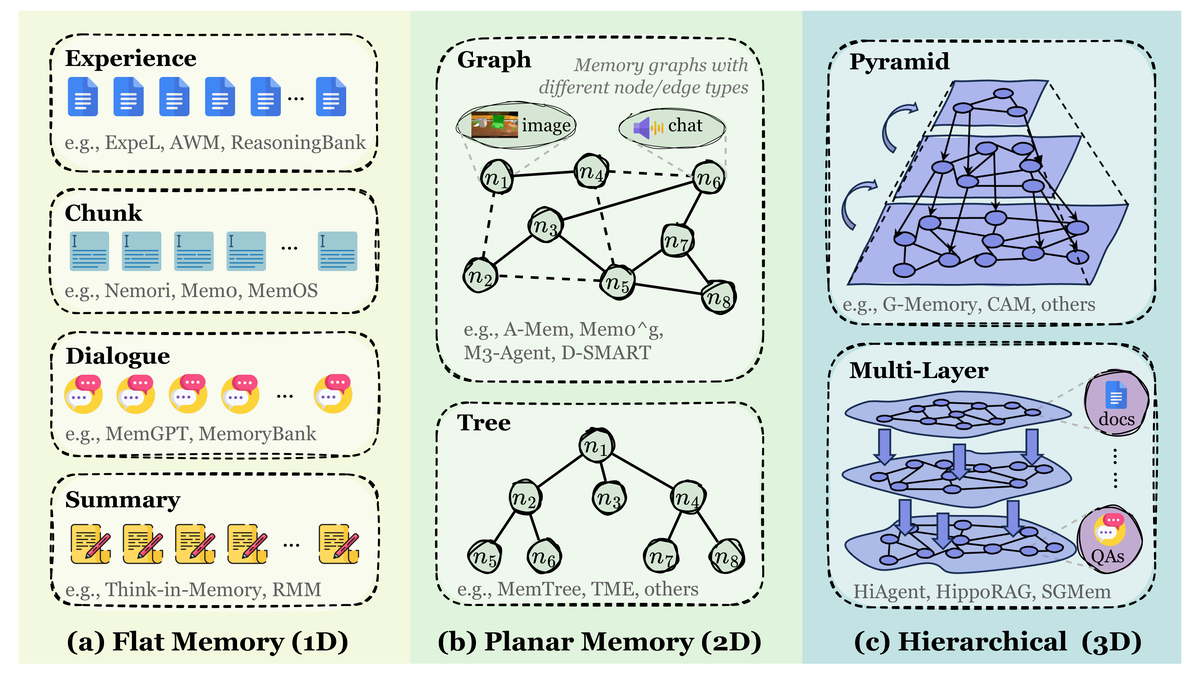
Figure 3 解读:展示了 Token-level Memory 按拓扑复杂度分为三类:(a) Flat Memory (1D) — 线性序列或独立集合,无显式拓扑,常用于 Chunk 集、Dialogue 日志、Experience 池(如 ExpeL, MemGPT, Think-in-Memory);(b) Planar Memory (2D) — 单层结构化组织,通过 Graph 或 Tree 关联记忆单元(如 A-Mem, MemTree);(c) Hierarchical Memory (3D) — 多层结构,通过 Pyramid 或 Multi-layer 图实现跨层抽象和推理(如 G-Memory, HiAgent, HippoRAG)。
三种 Token-level Memory 的特点:
| 类型 | 拓扑结构 | 优势 | 局限 |
|---|---|---|---|
| Flat (1D) | 无显式拓扑 | 简单、可扩展、灵活追加/删除 | 缺乏关系建模,检索依赖相似度 |
| Planar (2D) | 单层图/树/表 | 建立显式关联,支持结构化检索 | 必须在单一模块中整合所有记忆 |
| Hierarchical (3D) | 多层金字塔/多层图 | 支持多粒度推理和跨层检索 | 构建和维护成本高 |
3.3.2 Parametric Memory(隐式、抽象、可泛化)
分为两类:
- Internal Parametric Memory:直接修改模型原始权重(如 Character-LM fine-tuning、ROME/MEND knowledge editing、SELF-PARAM KL distillation)
- External Parametric Memory:通过附加参数模块(Adapter、LoRA、辅助 LM)携带记忆,不修改原始模型权重(如 MLP-Memory、K-Adapter、WISE、MemLoRA)
优势:不增加推理开销,记忆被隐式编码;局限:更新困难,容易灾难性遗忘。
3.3.3 Latent Memory(内部表示、连续、机器原生)

Figure 4 解读:展示了 Latent Memory 在 LLM agent 中的三种集成方式:(a) Generate — 辅助模型(SLM, LoRA, Decoder heads)生成 latent embeddings,注入到 LLM 的 layer-wise transformer forward 中干预或增强推理过程;(b) Reuse — 直接复用先前计算的 KV cache 或中间 embeddings 作为记忆;(c) Transform — 通过 Token Selection、Token Merge、Token Projection 等操作压缩/重构现有 latent 状态以保留关键信息。
代表系统:
- Generate:Gist (gist tokens)、MemoryLLM (persistent tokens)、Titans (neural weights MLP)、MemGen (LoRA fragments)
- Reuse:Memorizing Transformers (external KV cache)、FOT (memory-attention KV)、LONGMEM (residual SideNet KV)
- Transform:ScissorHands (pruned KV)、SnapKV (aggregated prefix KV)、PyramidKV (layer-wise budget)、H2O (heavy hitter tokens)
3.3.4 三种 Memory Forms 的适配场景

Figure 5 解读:对比三种 memory 形式的特征和适用场景。Token-level Memory — 符号化、可寻址、透明,适合多轮聊天、个性化 agent、推荐系统、高风险领域(法律/金融/医疗);Parametric Memory — 隐式、抽象、可泛化,适合角色扮演、推理密集型任务、需要根本性新能力的场景;Latent Memory — 隐式、不可读、高效,适合多模态记忆、边缘部署、低资源/小数据场景。
3.4 Functions:Agent 为什么需要 Memory?

Figure 6 解读:展示了 agent memory 的功能分类体系,分为 (a) Long-term Memory 和 (b) Short-term Memory 两个时间域。Long-term 包含:Factual Memory(用户事实记忆 + 环境事实记忆,保障一致性/连贯性/适应性)和 Experiential Memory(Case-based + Strategy-based + Skill-based,支持持续学习和自我进化)。Short-term 包含 Working Memory(单轮的输入压缩/观察抽象 + 多轮的状态整合/层级折叠/认知规划)。
3.4.1 Factual Memory(“agent 知道什么?”)
回答 “What does the agent know?” — 存储和检索关于过去事件、用户偏好、环境状态的显式声明性事实。
- User Factual Memory:维持跨会话交互一致性
- Dialogue Coherence(对话连贯):MemGPT, MemoryBank, Livia, RMM
- Goal Consistency(目标一致):RecurrentGPT, A-Mem, MemGuide
- Environment Factual Memory:维持与外部世界的一致性
- Knowledge Persistence(知识持久):HippoRAG, MemTree, LMLM, WISE, MemoryLLM
- Shared Access(共享访问):MetaGPT, G-Memory, OASIS(多 agent 协作场景)
3.4.2 Experiential Memory(“agent 如何改进?”)
回答 “How does the agent improve?” — 编码历史轨迹、蒸馏策略、交互结果为持久化的可检索表示。

Figure 7 解读:按存储知识的 抽象级别 分为四类:(1) Case-based Memory — 保留原始轨迹和解决方案(如 Momento, ExpeL, JARVIS-1);(2) Strategy-based Memory — 将经验抽象为策略、模板或工作流(如 AWM, H²R, ReasoningBank);(3) Skill-based Memory — 蒸馏为可执行函数/API/MCP 协议(如 Voyager, SkillWeaver, Alita);(4) Hybrid Memory — 整合多种形式(如 G-Memory, Memp)。
3.4.3 Working Memory(“agent 当前在思考什么?”)
回答 “What is the agent thinking about now?” — 在单任务/会话中动态管理上下文的有容量限制的工作空间。
- Single-turn Working Memory:处理大规模即时输入
- Input Condensation:LLMLingua, ICAE, AutoCompressors(硬/软/混合压缩)
- Observation Abstraction:Synapse, VideoAgent, Context-as-Memory
- Multi-turn Working Memory:维护跨轮次的任务状态
- State Consolidation:MEM1, MemGen, ReSum, IterResearch(动态更新固定大小状态)
- Hierarchical Folding:HiAgent, Context-Folding, AgentFold(按子目标分解-折叠)
- Cognitive Planning:PRIME, SayPlan, KARMA, Agent-S(外化计划作为工作记忆核心)
3.5 Dynamics:Memory 如何运作和演化?

Figure 8 解读:展示了 memory 系统的完整运作动态,分为三个基本过程:(1) Memory Formation — 从原始数据中提取信息密集的 memory 单元,包括 Semantic Summarization、Knowledge Distillation、Structured Construction、Latent Representation、Parametric Internalization 五种方式;(2) Memory Evolution — 将新 memory 整合到现有库中,通过 Consolidation(合并)、Update(更新)、Forget(遗忘)机制维护;(3) Memory Retrieval — 根据任务上下文构建查询并从 memory 库中检索,包括 Timing & Intent(何时检索)、Query Construction(查询构建)、Retrieval Strategies(检索策略)、Post-Retrieval Processing(后处理)四个阶段。
3.5.1 Memory Formation(“如何提取记忆?“)
| 方式 | 描述 | 代表方法 |
|---|---|---|
| Semantic Summarization | 原始数据 → 紧凑摘要 | MemGPT (incremental), MemoryBank (partitioned), Mem1 (RL-optimized PPO) |
| Knowledge Distillation | 提取特定认知资产 | TiM (thoughts), AWM (workflows), ExpeL (insights), H²R (hierarchical insight) |
| Structured Construction | 构建拓扑化表示 | KGT (user graph), Mem0ᵍ (KG), GraphRAG (hierarchical KG), Zep (temporal KG) |
| Latent Representation | 编码为机器原生格式 | MemoryLLM (latent vector), M+ (cross-layer), CoMEM (multimodal embedding) |
| Parametric Internalization | 融入模型权重 | ROME (causal tracing), MEND (gradient decomposition), LoRA adapters |
3.5.2 Memory Evolution(“如何精炼记忆?”)
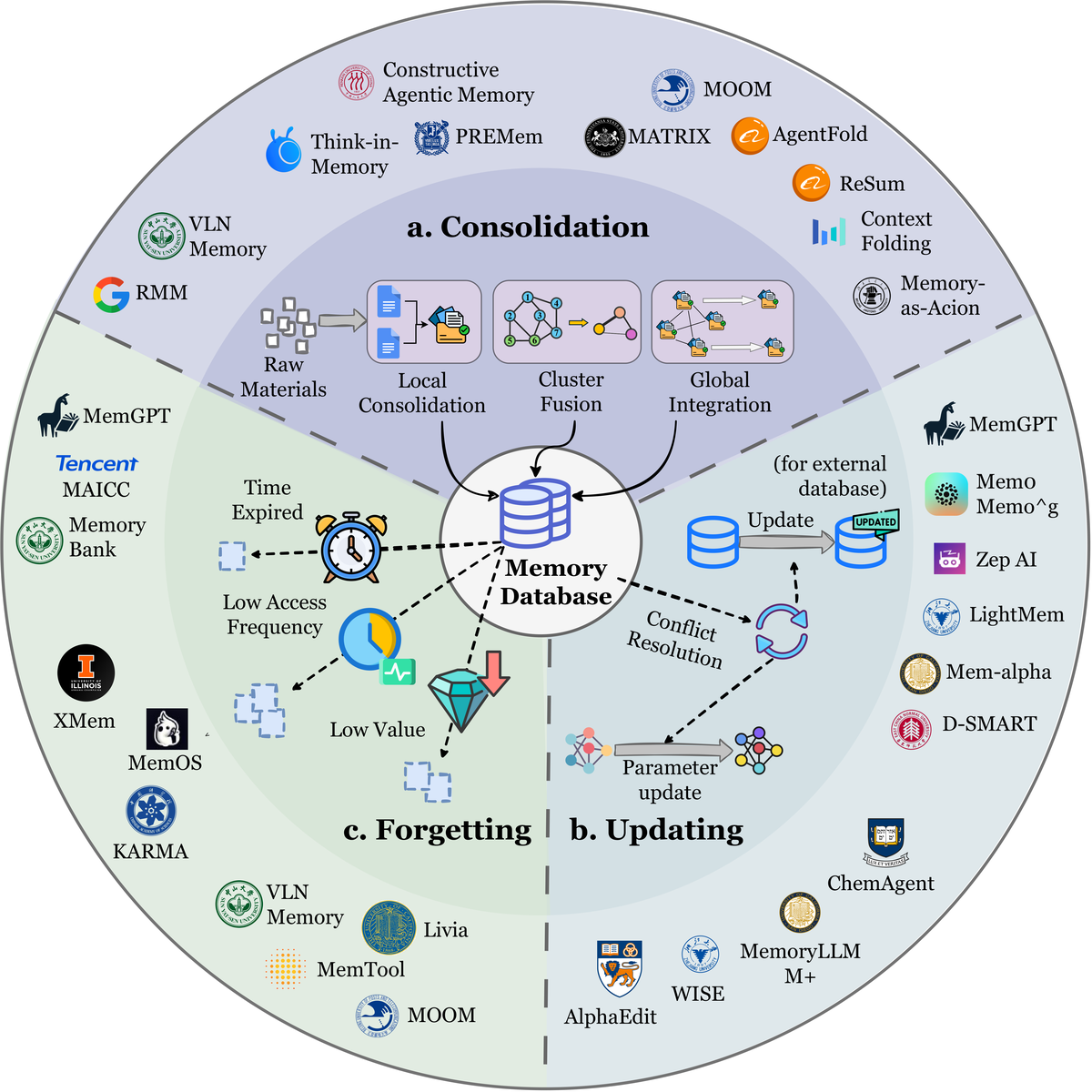
Figure 9 解读:展示了 Memory Evolution 的三个分支环绕中央 Memory Database:(a) Consolidation — 通过 Local Consolidation(如 RMM top-K 合并)、Cluster Fusion(如 PREMem 跨集群对齐)和 Global Integration(如 MOOM 角色稳定构建)合成洞察;(b) Updating — 通过外部数据库冲突解决和内部模型参数更新确保准确性(如 Zep temporal annotations、Mem-α RL-based update policy);(c) Forgetting — 基于 Time Expired(如 MemGPT FIFO eviction)、Low Access Frequency(如 XMem LFU, KARMA Bloom filters)和 Low Value(如 TiM/MemTool importance-driven)的策略优化效率。
3.5.3 Memory Retrieval(“如何利用记忆?”)
四阶段检索流水线:
-
Retrieval Timing and Intent:自主决定何时触发检索及访问哪个 memory 源
- Automated Timing:MemGPT (OS-like invocation), ComoRAG/PRIME (fast-slow thinking), MemGen (latent triggers)
- Automated Intent:AgentRR (环境反馈切换), MemOS (MemScheduler 多源选择), H-MEM (分层路由)
-
Query Construction:弥合用户原始输入与 memory 索引之间的语义鸿沟
- Decomposition:Visconde, PRIME, MA-RAG, Agent KB
- Rewriting:HyDE (hypothetical document), MemoRAG (compressed memory → draft), MemGuide (intent extraction)
-
Retrieval Strategies:
- Lexical:TF-IDF, BM25(精度导向场景)
- Semantic:Sentence-BERT, CLIP embedding(大多数 agent memory 框架的默认选择)
- Graph:AriGraph, HippoRAG (PersonalizedPageRank), SGMem, Zep (temporal subgraph)
- Hybrid:Agent KB (lexical + semantic), MemoriesDB (temporal-semantic-relational)
-
Post-Retrieval Processing:
- Re-ranking & Filtering:Semantic Anchoring, learn-to-memorize (RL-based score aggregation), Memory-R1 (Answer Agent)
- Aggregation & Compression:ComoRAG (Integration Agent), G-Memory (role-specific condensation)
3.6 前沿方向
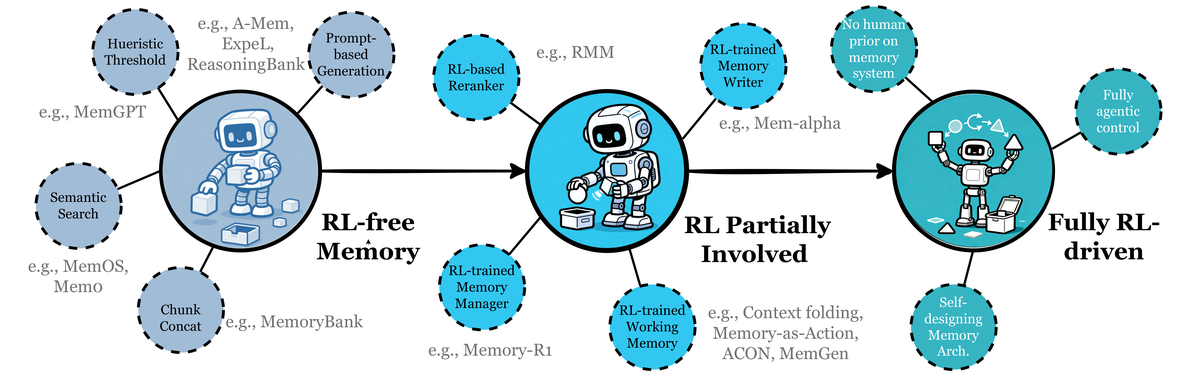
Figure 11 解读:展示了 RL-enabled agent memory 系统的演进路径:从 RL-free Memory(基于启发式/prompt 驱动,如 MemGPT, A-Mem, ExpeL)到 RL Partially Involved(RL 训练部分组件,如 RMM 的 RL-based Reranker、Memory-R1 的 RL-trained Memory Manager、Context Folding/MemGen 的 RL-trained Working Memory)再到未来的 Fully RL-driven(agent 完全自主控制 memory 架构和操作策略,自我设计 memory 架构)。
论文指出了 8 个前沿研究方向:
- Memory Retrieval → Memory Generation:从静态检索库中被动查找,转向主动生成适应当前上下文的新 memory 表示(如 MemGen 的 latent memory tokens, ComoRAG 的 retrieve-then-generate)
- Automated Memory Management:从手工规则到 agent 自主管理(memory construction/evolution/retrieval 统一到 agent 的 tool call 决策循环中)
- RL 与 Agent Memory 深度融合:预计 fully RL-driven memory systems 将成为下一阶段主导方向
- Multimodal Memory:目前尚无真正的 omnimodal memory 系统,需要统一的跨模态 memory 表示
- Multi-Agent Shared Memory:从孤立本地记忆到 agent-aware 的共享认知基底
- Memory for World Model:memory 机制是 world model 维持长期一致性的基石
- Trustworthy Memory:隐私保护、可解释性、幻觉缓解三大支柱
- Human-Cognitive Connections:借鉴认知科学的离线巩固、生成式重建等机制
4. 实验设置 (实验设置)
作为综述论文,本文不涉及自身实验,但系统梳理了该领域的 benchmarks 和开源框架:
Benchmarks 分类
| 类别 | 代表 Benchmark | 规模 | 特点 |
|---|---|---|---|
| Memory/Lifelong-oriented | MemBench, LoCoMo, LongMemEval, MemoryAgentBench | 300–53K samples | 直接评估 memory 构建/维护/利用能力 |
| Personalization | PersonaMem, PerLTQA, PrefEval, MPR | 194–108K samples | 用户建模、偏好追踪、会话一致性 |
| Long-context | LongBench, RULER, BABILong, MM-Needle | 13–280K tasks | 间接测试 memory 的长上下文处理能力 |
| Agent/Embodied | WebArena, SWE-Bench Verified, GAIA, AgentGym | 100–126K samples | 多步交互中隐式测试 memory |
开源框架
| 框架 | Factual | Experiential | 多模态 | 结构 | 已报告评测 |
|---|---|---|---|---|---|
| MemGPT | ✓ | ✓ | ✗ | hierarchical (S/LTM) | LoCoMo |
| Mem0 | ✓ | ✓ | ✗ | graph + vector | LoCoMo |
| MemOS | ✓ | ✓ | ✗ | tree memory + memcube | LoCoMo, PrefFEval, LongMemEval, PersonaMem |
| Zep | ✓ | ✓ | ✗ | temporal knowledge graph | LongMemEval |
| MIRIX | ✓ | ✓ | ✓ | structured memory | LoCoMo, MemoryAgentBench |
5. 实验结果 (实验结果)
主要发现
-
Token-level Memory 是当前最主流的形式:Table 1 收录了 100+ 种方法,绝大多数采用 token-level 存储,因其透明、可编辑、易于与任意 LLM 集成。
-
Experiential Memory 正成为核心差异化能力:从简单的 case replay (ExpeL, Synapse) 到策略蒸馏 (AWM, ReasoningBank) 再到可执行技能 (Voyager, SkillWeaver),抽象层次不断提升。
-
RL 正在深刻改变 memory 管理范式:
- RL-free(大部分早期工作)→ RL-assisted(RMM, Mem-α, Memory-R1, Context Folding)→ 未来的 Fully RL-driven
- Mem1 使用 PPO 优化摘要,MemAgent 使用 GRPO,Mem-α 将 memory 更新建模为 policy learning
-
Memory Generation 正在超越 Memory Retrieval:
- 传统范式:从静态 memory 库中检索 → 新范式:主动生成适应上下文的 memory 表示
- MemGen 通过 latent memory tokens 直接生成记忆,绕过显式检索
-
多模态和多 agent memory 仍处于早期阶段:
- 视觉/视频 memory 最受关注(VideoAgent, MA-LMM, Context-as-Memory)
- 音频等其他模态 memory 严重不足
- 多 agent 共享 memory 面临写冲突、权限控制等挑战
局限性
- 该领域缺乏统一的评测协议,不同方法使用不同 benchmark,难以直接比较
- 大量工作仅依赖 prompt engineering (PE) 而非训练优化,可能限制记忆管理的自主性
- Latent Memory 虽然高效但缺乏可解释性,难以调试和验证
- 当前 memory 系统在 trustworthiness 方面(隐私泄露、幻觉放大)研究不足
总结
本综述通过 “Forms–Functions–Dynamics” 三维框架,系统梳理了 agent memory 从形式(token-level/parametric/latent)、功能(factual/experiential/working)到动态(formation/evolution/retrieval)的完整图景。论文指出 memory 不仅是 agent 的辅助存储机制,更是实现 temporal coherence、continual adaptation 和 long-horizon competence 的核心基础设施,预示着 memory 将成为未来 agentic AI 设计中的一等公民。