MSA: Memory Sparse Attention for Efficient End-to-End Memory Model Scaling to 100M Tokens
Paper: arXiv:2603.23516 Code: EverMind-AI/MSA Code reference:
main@77fbdfde(2026-05-06) Model: EverMind-AI/MSA-4B Authors: Yu Chen*, Runkai Chen*, Sheng Yi, Xinda Zhao, Xiaohong Li, Jianjin Zhang, Jun Sun, Chuanrui Hu, Yunyun Han, Lidong Bing, Yafeng Deng, Tianqiao Chen Affiliations: Evermind, Shanda Group, Peking University PDF: GitHub PDF Homepage: evermind.ai DOI: 10.5281/zenodo.19103670 Year: 2026 Code Status: 官方实现与 benchmark runner 已公开;本笔记的代码映射、伪代码和实现差异基于main@77fbdfde。
1. Motivation (研究动机)
这篇论文关注的是一个非常“基础设施级”的问题:如何把 LLM 的可用记忆容量从 128K–1M token,扩展到接近人类终身记忆量级的 100M token,同时又不牺牲精度、效率和端到端可训练性。
作者给出的出发点非常明确:
- 很多真实任务——例如超长小说理解、Digital Twins、长期 persona 保持、长历史 agent reasoning——都要求模型能够稳定利用数千万到上亿 token 的历史信息。
- 现有 long-context LLM 虽然把上下文扩到了 128K、256K、甚至 1M,但离“终身记忆”仍差了两个数量级。
- 如果只是把 context window 继续堆大,full attention 的计算和显存成本会迅速失控。
论文把现有长时记忆方案分成三类,并指出它们各自的根本缺陷:
- Parameter-Based Memory
- 代表:LoRA / Continual Pre-training / test-time training(如 Titans)
- 优点:和主流 LLM 架构兼容,语义融合深
- 缺点:不具备 lifetime memory,可持续写入时容易 catastrophic forgetting,记忆管理也困难
- External Storage-Based Memory
- 代表:RAG、MemAgent
- 优点:可以扩展到很大的外部知识库
- 缺点:retrieval pipeline 与生成模型解耦,不是 end-to-end differentiable;检索质量上限受 embedding / rerank pipeline 限制
- Latent State-Based Memory
- 代表:DSA、MemGen、RWKV、DeltaNet
- 优点:直接在模型 latent state / KV 空间操作,语义对齐更自然
- 缺点:要么像 sparse attention 那样难以扩到 100M,要么像 linear attention 那样用固定状态压缩历史,最终不可避免地丢信息
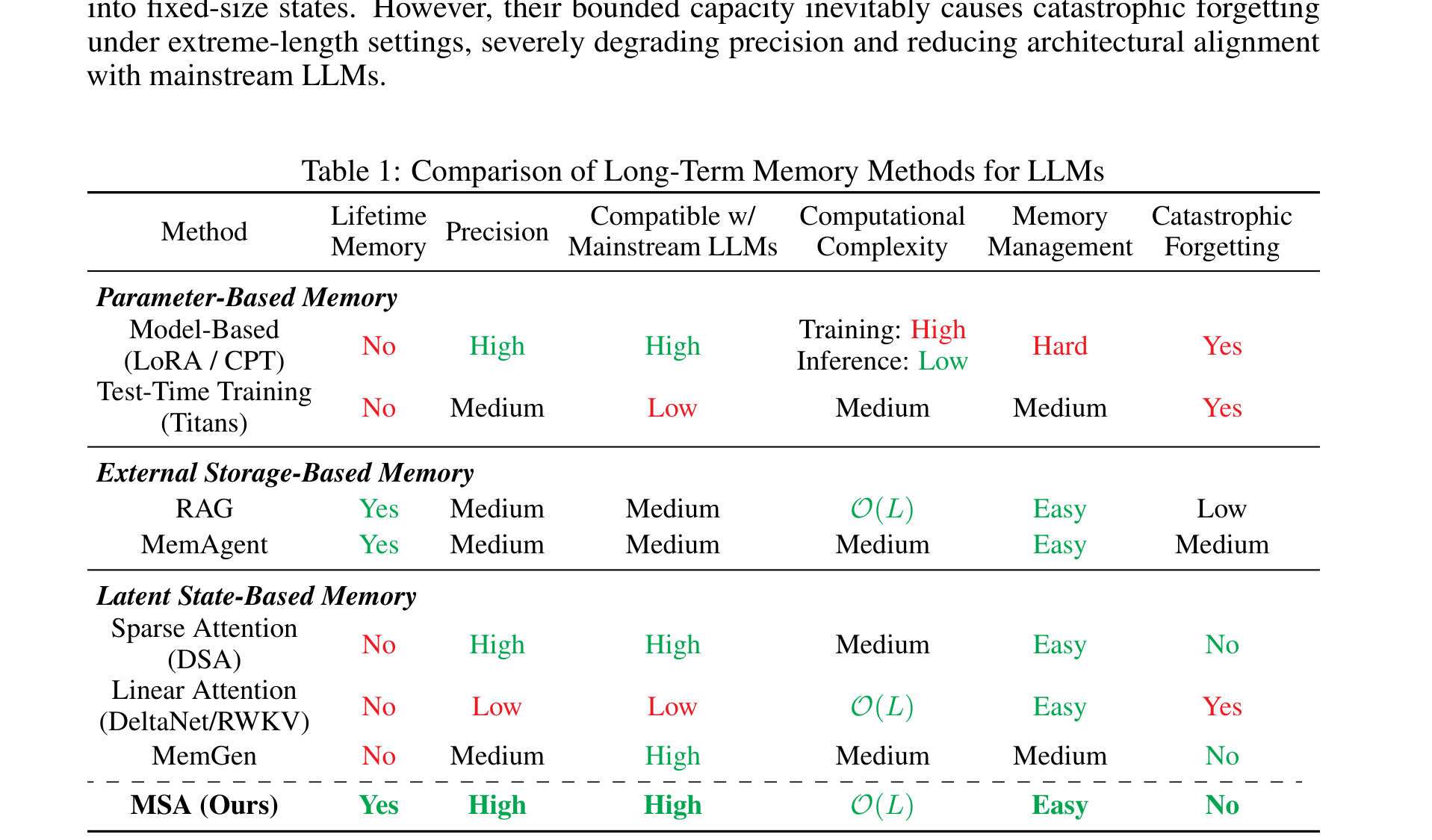
Table 1 解读:这张表非常清楚地总结了作者的目标函数。理想方法应该同时满足 Lifetime Memory=Yes、Precision=High、Compatible w/ Mainstream LLMs=High、Computational Complexity=O(L)、Memory Management=Easy、Catastrophic Forgetting=No。表中只有 MSA 被作者声称完整满足这六项要求,这也是整篇论文要证明的核心主张。
因此,这篇论文真正想解决的问题不是“如何让检索更强”,而是:
能否构建一种 intrinsic memory mechanism,既保留 latent-state memory 的语义对齐优势,又具有 external memory 的超大容量,同时还能端到端训练?
2. Idea (核心思想)
MSA 的核心思想可以概括为三句话:
- 用 document-level sparse attention 替代 full attention:不是让 query 看完整个 100M-token memory,而是先在 latent routing space 里找 Top-k 文档,再只对这些文档的压缩 KV 做 attention。
- 把 retrieval 融进模型内部的 latent state:检索用的不是外部 embedding pipeline,而是模型内部 learnable router projector 产生的 routing query / routing key,因此整个过程可以 end-to-end differentiable。
- 把“训练短、推理长”的位置偏移问题交给 document-wise RoPE 解决:每篇文档独立编号,避免随着文档数增加导致 position drift,从而支持 64K 训练外推到 100M 推理。
和现有方法相比,MSA 的本质区别在于:
- 不同于传统 RAG:RAG 是“先检索、再阅读”的外部流水线;MSA 是“latent routing + sparse attention”的内部统一框架。
- 不同于 linear attention memory:linear attention 把全部历史压进固定状态;MSA 保留显式 document selection,尽量避免固定状态压缩带来的 catastrophic forgetting。
- 不同于只做工程级 KV offload:MSA 不只是把 KV 搬到 CPU,而是从架构层面把 memory bank 组织成可训练、可检索、可扩展的 compressed latent store。
作者最终想实现的是:
decouple memory capacity from reasoning —— 推理能力由 backbone 负责,记忆容量由稀疏 latent memory 扩展。
3. Method (方法)
3.1 总体架构:Memory Sparse Attention layer
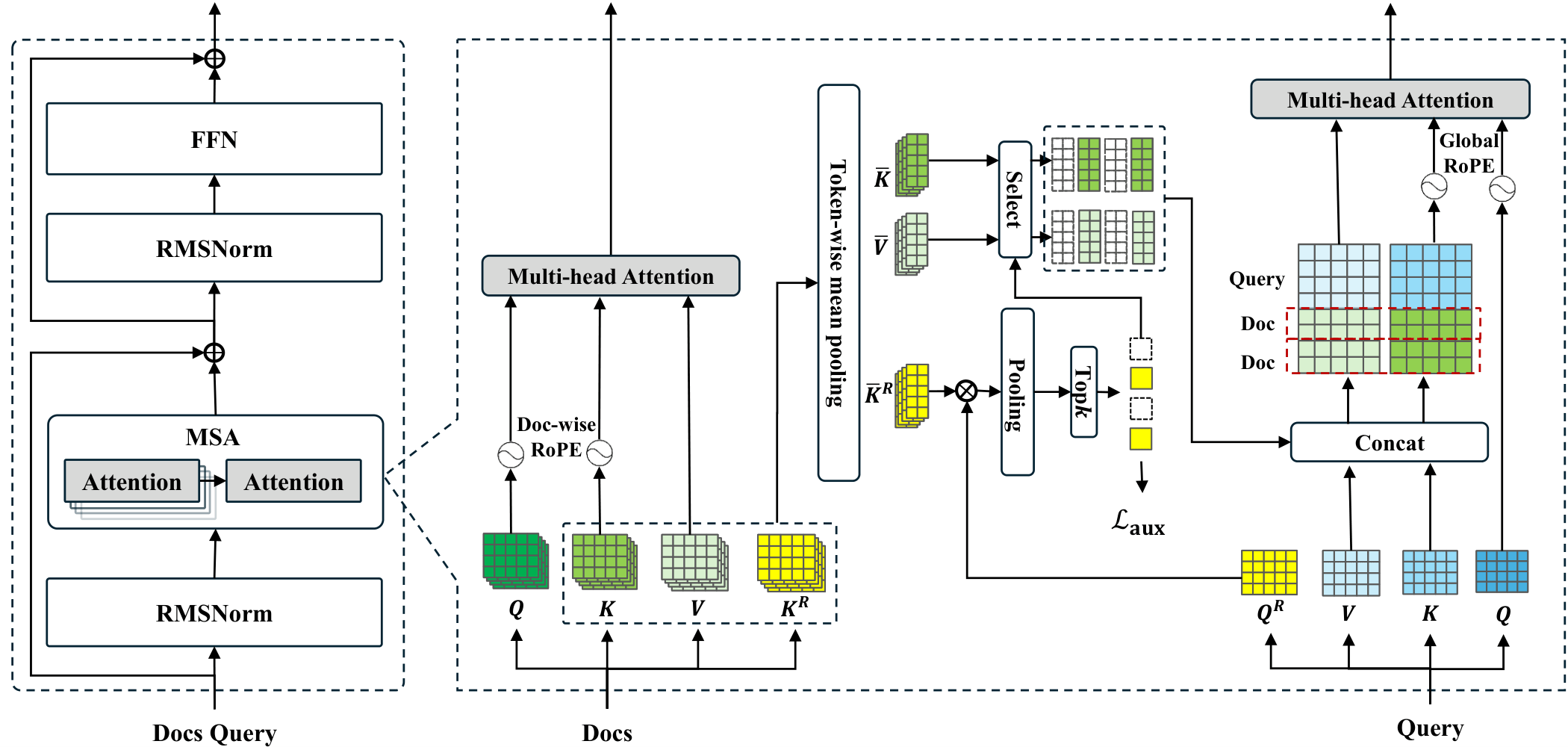
Figure 2 解读:左侧是 MSA block 在 Transformer layer 内的位置:它只替换 attention 部分,FFN、RMSNorm 等主干保持不变,因此和 mainstream LLM backbone 高度兼容。中间是 document 侧:每篇文档先通过 backbone 投影出 ,再额外通过 router projector 得到 ,之后做 chunk-wise mean pooling 压缩。右侧是 query 侧:query 同样产生 ,在 routing space 中与压缩后的 做相似度匹配,选出 Top-k 文档,再把这些文档的压缩 与 query 本地 拼接,进入真正的 multi-head attention。图中最重要的结构信息是:routing 与 content attention 分离,但仍在一个可训练框架里闭环。
设 memory bank 中有文档集合 ,文档 的 hidden states 为 。对某个 attention head ,MSA 先计算标准 content KV 和专门的 routing key:
然后对文档做 chunk-wise mean pooling ,得到压缩后的 latent memory:
对 query hidden states ,模型计算:
第 个文档第 个 chunk 的路由分数定义为:
文档级分数是 chunk 最大值:
最后,只把被选中的 Top-k 文档压缩 KV 与 query 本地 KV 拼起来:
这里有一个很关键的实现决策:MSA routing 只应用在模型后半层。作者认为前几层 hidden states 还没有形成足够高层的语义抽象,不适合做高质量检索;因此前半层只做 independent document processing,而不做 sparse retrieval。
Released code 让这个逻辑更清晰:MSAModel 把 36 层都替换成 MemorySparseAttention,但 EverMind-AI/MSA-4B/config.json 的 router_layer_idx=18,19,...,35,所以只有后 18 层真的做 Top-k memory routing;前 18 层仍然走文档内 causal attention / prompt-response attention。doc_ids 是整套实现的分区信号:doc_ids>0 表示 memory document tokens,doc_ids==0 表示 query / active context,doc_ids==-2 表示 template prefix,生成阶段追加 token 时会先用 -1 进入 prompt/response mask。
论文公式与 released code 实现差异:主路由的 reduction 逻辑基本一致,但 released checkpoint 的 msa_config 把 head_reduce_method=mean、query_reduce_method=max、chunk_reduce_method=max 固定下来;更细一点看,prefill inference branch 只有在 aux_loss_method == "INFONCE" 时才显式 normalize router Q/K,而公开 checkpoint 是 INFONCE_DECOUPLE,因此这条 inference 路径更接近 raw router dot-product;training _forward() 分支则用 "INFONCE" in aux_loss_method,会覆盖 INFONCE_DECOUPLE。另外,aux_loss=False 是公开推理 checkpoint 的配置,不代表论文训练阶段没有 auxiliary routing loss。仓库没有公开训练 launch script,因此训练 schedule 仍只能按论文/README 记录,不能从代码脚本复现。
3.2 Parallel / Global RoPE:解决 train-short, infer-long 的位置漂移
MSA 的第二个关键设计是 document-wise RoPE + global RoPE 的混合位置编码。
问题背景是:如果训练时只有少量文档、推理时文档数暴增,那么标准 global positional encoding 会让 token position id 随总文档数单调增加,导致 inference 时的位置信号远超训练分布,产生严重的 position drift。
作者的解决方法是:
- Document-wise RoPE:每篇文档的 position id 都从 0 重新开始,完全解耦“文档内位置”与“总 memory bank 大小”。
- Global RoPE for active context:对于 query 和 autoregressive generation 的 active context,再额外用全局位置偏移,使模型感知到“retrieved background → query → generation”的顺序关系。
这个设计的意义非常大:它让模型能在 64K 训练上下文 下学会 memory access,再外推到 100M 推理上下文,而不必真的在训练时看到 100M 长度。
3.3 训练:Generative Retrieval + auxiliary routing loss
MSA 的训练分成两部分:continuous pre-training 和 post-training。
3.3.1 Continuous Pre-training
作者在一个 158.95B tokens 的去重语料上做 continuous pre-training,目标是让模型学会 Generative Retrieval:模型不是输出“相关文档 embedding”,而是自回归生成相关文档的 document IDs。
为了显式监督 layer-wise routing,作者引入 auxiliary loss 。设正样本文档集合为 ,负样本文档集合为 ,正样本分数为 ,与之配对的负样本分数为 ,则:
这本质上是一个 supervised contrastive routing objective,目的是让 router 在 latent routing space 里把 relevant chunks 和 irrelevant chunks 拉开。
训练采用两阶段优化:
- warm-up phase learning rate =
- main pre-training phase learning rate =
这个 schedule 的直觉是:先把 router 训准,再让主任务生成损失主导。
Released code 中,训练相关 loss 被落在 MSAForCausalLM.forward():总损失写成 lmloss_weigth * loss + recloss_weight * reconstruction_loss + auxloss_weight * aux_loss + ansloss_weight * answer_loss,auxiliary loss 由每层输出的 docs_score 和 batch_aux_labels 计算。实现支持 INFONCE_DECOUPLE / BCE / focal InfoNCE 等变体;公开 MSA-4B 配置的 aux_loss_method=INFONCE_DECOUPLE、infonce_loss_temp=0.1、auxloss_weight=0.1 与论文“contrastive routing objective”的叙述一致。
3.3.2 Post-Training
Post-training 采用 two-stage curriculum SFT:
- 第一阶段:在 8K context 上训练 QA / instruction-following 能力
- 第二阶段:清洗数据,并把 memory context 从 8K 扩到 64K
作者强调,这个 curriculum 对超长外推非常重要,因为它让模型逐步暴露在更长的 memory context 下,而不是一次性从短上下文跳到超长上下文。
3.4 推理:Three-Stage Inference + Memory Parallel
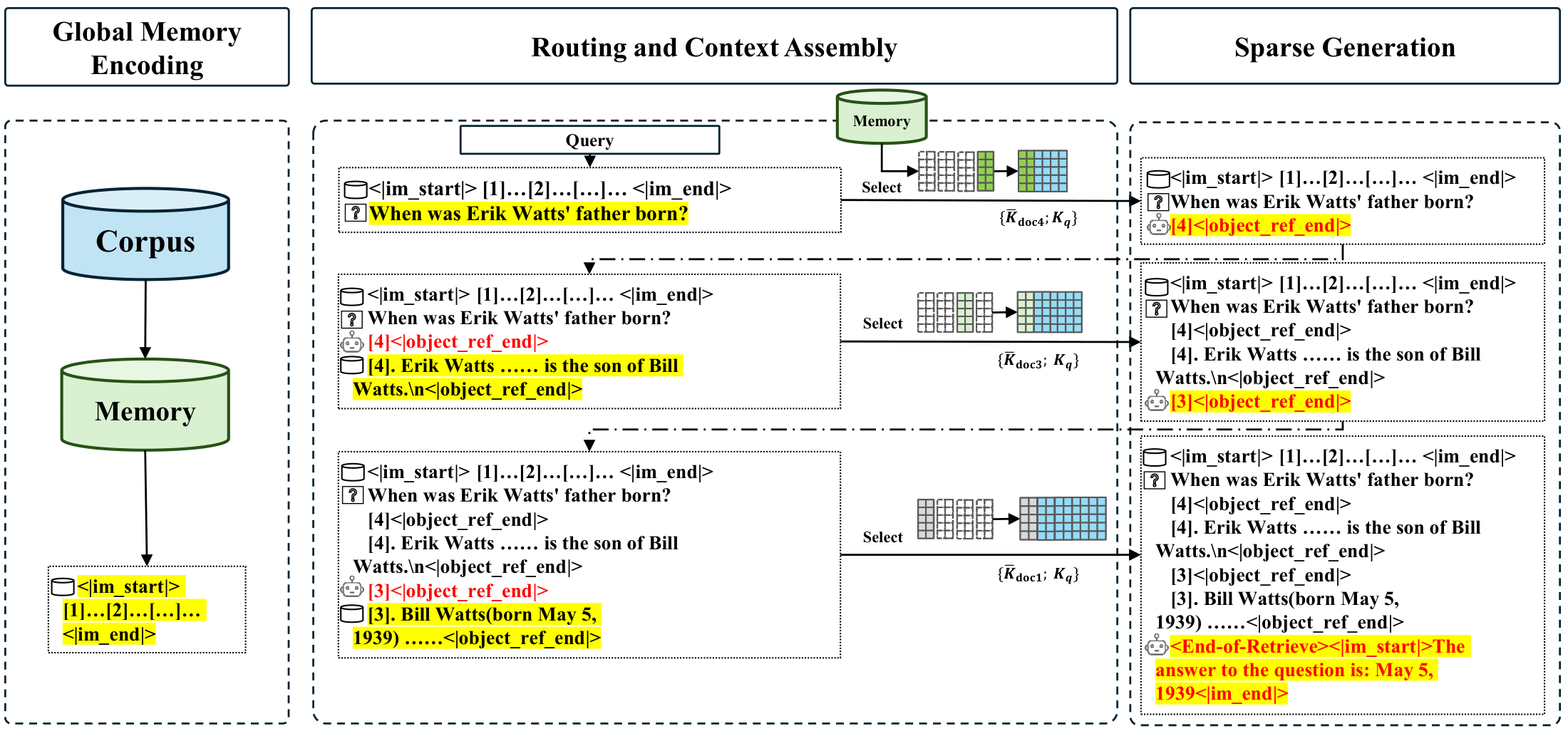
Figure 3 解读:这张图给出了 MSA 的完整推理流程。左侧是 Global Memory Encoding:先离线把 corpus 编码成压缩后的 memory bank。中间是 Routing and Context Assembly:给定 query,模型先生成 document IDs,再根据这些 ID 取回相应文档,拼进新一轮 query。右侧是 Sparse Generation:在拼好的 sparse context 上自回归生成最终答案。图中最值得注意的是黄色高亮部分,它表示模型不是一次性检索完,而是可以多轮检索、逐轮扩展 context。
MSA 的 inference pipeline 分成三阶段:
- Global Memory Encoding(离线)
- 对所有文档前向一次
- 计算并缓存压缩后的
- Routing and Context Assembly(在线)
- 计算 query 的
- 与全局 匹配,选 Top-k 文档
- 只加载这些文档的压缩
- Sparse Generation(在线)
- 在组装好的 sparse context 上做自回归生成
为了把 100M token memory 跑在单个 2×A800 节点上,作者进一步提出 Memory Parallel:
- GPU-resident routing keys: 放 GPU,保证 routing 低延迟
- CPU-offloaded content KV: 放 host DRAM,被选中后再异步拉回 GPU
- distributed scoring:query broadcast 到各 GPU,各卡只算本地 shard 的 routing score,再做全局 reduce
论文给了一个很实在的量级估算:对 100M token、pooling kernel 、8 heads、head dim 128、18 layers、BF16 而言,仅压缩后的 cache 就大约需要 169GB。这比 2×A800 的总显存 160GB 还高,所以必须做 tiered storage。
Released code 把三阶段推理拆成更工程化的 cache 状态:prefill_stage1 先把 memory document tokens 按 pooling_kernel_size=64 做 chunk mean pooling,并缓存 pooled_k/pooled_v 与可选的 pooled_router_k;prefill_stage2 对 query 计算 routing score,通过 memory_client.doc_query() 取回被选 chunk 的 compressed KV,并在这一阶段把 template prefix、retrieved chunks 和当前 query KV 拼成 variable-length FlashAttention 输入;后续逐 token generate 分支是在已有 compacted KV cache 后追加新 K/V,并用 F.scaled_dot_product_attention 解码。这个实现说明 MSA 的“memory”不是原文 token 全量参与 attention,而是先在 latent KV 空间压缩,再按 query 选择少量 chunk/document 参与 attention。
3.5 Memory Interleave:多跳推理不是一次检索,而是迭代检索
对于 multi-hop query,单轮 Top-k selection 往往不够,因为模型需要先找到第一跳证据,再用这份证据去定位第二跳证据。MSA 的做法是 Memory Interleave:
- 基于原始 query 生成一轮 document IDs
- 取回对应原文,把它们附加到 query 后面
- 用扩展后的 query 再做一轮 retrieval / generation
- 重复,直到模型认为证据足够,转而输出最终答案
也就是说,MSA 不是“retrieve once, answer once”,而是:
generative retrieval → context expansion → retrieval again → final answer
这使它更像一个内生的 multi-hop memory reasoning mechanism,而不是外部代理式 pipeline。
代码里的 Memory Interleave 不是一个独立 agent planner,而是 MSAGenerationMixin._sample() 中的生成状态机:模型先生成形如 [12][45]... 的 document ID 字符串;遇到 <|object_ref_end|> 后把这些 ID 对应的原文拼回 source_context_list;遇到 <End-of-Retrieve> 或超过检索轮长度上限后进入最终回答阶段。这样做把“显式文档 ID 生成”和“latent sparse attention routing”区分开:前者负责多跳证据展开,后者负责每次 active context 内的高效 attention。
3.6 伪代码(基于 released code)
Code reference:
main@77fbdfde(2026-05-06) — pseudocode based onsrc/msa/memory_sparse_attention.py,src/msa/model.py, andsrc/msa/generate.py.
3.6.1 Stage-1:把 memory documents 压缩成 latent chunks
import torch
import torch.nn.functional as F
def prefill_stage1_build_memory(hidden_states, doc_ids, attention_mask, q_proj, k_proj, v_proj,
router_k_proj, pooling_kernel_size=64, decouple_router=True, aux_loss_method="INFONCE_DECOUPLE"):
# doc_ids > 0 are memory-document tokens; each consecutive doc id is one document.
query_states = q_proj(hidden_states) # [B, L, Hq, D]
key_states = k_proj(hidden_states) # [B, L, Hkv, D]
value_states = v_proj(hidden_states) # [B, L, Hkv, D]
doc_token_mask = (doc_ids > 0) & (attention_mask == 1)
doc_indices = torch.nonzero(doc_token_mask, as_tuple=False)
max_doc_id = int(doc_ids.max().item())
global_doc_ids = doc_indices[:, 0] * (max_doc_id + 1) + doc_ids[doc_token_mask]
_, doc_lengths = torch.unique_consecutive(global_doc_ids, return_counts=True)
offsets = F.pad(doc_lengths.cumsum(0), (1, 0))[:-1]
token_rank_in_doc = torch.arange(global_doc_ids.numel(), device=doc_ids.device) - torch.repeat_interleave(offsets, doc_lengths)
chunk_ids = token_rank_in_doc // pooling_kernel_size
max_chunks_per_doc = (doc_ids.shape[1] // pooling_kernel_size) + 1
global_chunk_ids = global_doc_ids * max_chunks_per_doc + chunk_ids
pooled_k, pooled_v = sequence_mean_pool_kv(key_states, value_states, doc_indices, global_chunk_ids)
pooled_router_k = None
if decouple_router:
router_k = router_k_proj(hidden_states)[doc_indices[:, 0], doc_indices[:, 1]]
pooled_router_k = sequence_mean_pool(router_k, global_chunk_ids)
# In inference prefill code this is `== "INFONCE"`; training `_forward()` uses `"INFONCE" in aux_loss_method`.
if aux_loss_method == "INFONCE":
pooled_router_k = F.normalize(pooled_router_k, p=2, dim=-1)
return pooled_k, pooled_v, pooled_router_k3.6.2 Router:从 query 选择 Top-k memory documents
def score_and_select_docs(routing_q, pooled_router_k, query_mask, chunk_mask, chunk_to_doc_id,
top_k_docs=16, head_reduce="mean", query_reduce="max", chunk_reduce="max",
normalize_router=False):
# routing_q: [B, H, Q, D], pooled_router_k: [B, C, H, D]
# Released INFONCE_DECOUPLE inference path leaves this False; training path may normalize.
if normalize_router:
routing_q = F.normalize(routing_q, p=2, dim=-1)
pooled_router_k = F.normalize(pooled_router_k, p=2, dim=-1)
scores = torch.matmul(routing_q, pooled_router_k.permute(0, 2, 3, 1)) # [B, H, Q, C]
scores = scores.masked_fill(~(query_mask[:, None, :, None] & chunk_mask[:, None, None, :]), -torch.inf)
if head_reduce == "mean":
scores = scores.mean(dim=1) # [B, Q, C]
else:
scores = scores.max(dim=1).values
if query_reduce == "max":
chunk_scores = scores.max(dim=1).values
elif query_reduce == "mean":
chunk_scores = masked_mean(scores, query_mask[:, :, None], dim=1)
else: # released code also supports "last"
chunk_scores = scores[torch.arange(scores.shape[0]), query_mask.sum(dim=1) - 1]
doc_scores = scatter_reduce_chunks_to_docs(chunk_scores, chunk_to_doc_id, reduce=chunk_reduce)
k_per_sample = torch.minimum((doc_scores > -1e9).sum(dim=1), torch.full_like(doc_scores[:, 0], top_k_docs))
sorted_doc_ids = torch.argsort(doc_scores, dim=1, descending=True)
return mask_after_k(sorted_doc_ids, k_per_sample), doc_scores3.6.3 Sparse attention:只把 template / selected chunks / query 拼进 FlashAttention
def prefill_stage2_sparse_attention(query_states, key_states, value_states, template_kv,
selected_chunk_kv, attention_mask):
template_k, template_v = template_kv
selected_k, selected_v, num_selected_chunks = selected_chunk_kv
num_q = attention_mask.sum(dim=1)
kv_lengths = template_k.shape[2] + num_selected_chunks + num_q
q_final = pack_valid_query_tokens(query_states, attention_mask)
k_final, v_final = allocate_compacted_kv(kv_lengths)
scatter_template_prefix(k_final, v_final, template_k, template_v)
scatter_selected_memory_chunks(k_final, v_final, selected_k, selected_v, num_selected_chunks)
scatter_current_query_kv(k_final, v_final, key_states, value_states, attention_mask)
return flash_attn_varlen_func(
q_final,
k_final.transpose(0, 1),
v_final.transpose(0, 1),
cu_seqlens_q=prefix_sum(num_q),
cu_seqlens_k=prefix_sum(kv_lengths),
causal=True,
)3.6.4 Memory Interleave:显式 document-ID 生成 + 原文回填
def memory_interleave_generate(model, tokenizer, query, idx_to_doc, max_generate_tokens=256):
response = ""
inner = ""
stage = 1
while len(response) < max_generate_tokens:
token = model.generate_next_token()
response += tokenizer.decode(token)
inner += tokenizer.decode(token)
if stage == 1 and ("<|object_ref_end|>" in inner or not looks_like_doc_id_prefix(inner)):
stage = 2
if stage == 2:
doc_ids = parse_document_ids(inner)
source_text = "".join(f"[{i}]. {idx_to_doc[i]}\n" for i in doc_ids if i in idx_to_doc)
model.append_source_context(source_text + "<|object_ref_end|>")
inner = ""
stage = 1
if "<End-of-Retrieve>" in response:
model.append_source_context(f"<|im_start|>The user's question is: {query}\n<|object_ref_end|>")
stage = 4 # final answer stage
if model.finished_answer():
break
return response3.7 Code-to-paper mapping(released code)
Code reference:
main@77fbdfde(2026-05-06) — pseudocode and mapping based on this commit.
| Paper Concept | Source File | Key Class/Function | 说明 |
|---|---|---|---|
| MSA layer 替换 Transformer attention | src/msa/model.py | MSADeocoderLayer, MSAModel, MSAForCausalLM | 36 层都实例化 MemorySparseAttention;routing 是否启用由 router_layer_idx 控制 |
| Chunk-wise latent memory compression | src/msa/memory_sparse_attention.py | sequence_pooling_kv(), prefill_stage1 branch | 对 doc_ids>0 的文档 token 按 pooling_kernel_size=64 做 mean pooling,得到 compressed K/V chunks |
| Decoupled router projector | src/msa/memory_sparse_attention.py | router_k_proj, router_q_proj | decouple_router=True 时 routing 用独立 Q/K projection;content attention 仍用普通 K/V |
| Routing score / Top-k document selection | src/msa/memory_sparse_attention.py | _calculate_routing_scores_adaptive(), training _forward() | 公开配置为 head mean、query max、chunk max,top_k_docs=16 |
| Prefill stage-2 sparse context assembly | src/msa/memory_sparse_attention.py | prefill_stage2 branch | 把 template prefix、selected chunks、query KV pack 成 variable-length FlashAttention 输入 |
| Three-stage generation loop | src/msa/generate.py | MSAGenerationMixin._sample() | 维护 generate_stage、`< |
| Multi-GPU / Memory Parallel engine | src/msa_service.py, src/prefill.py | MSAEngine, PrefillStage1Worker | 使用 worker 对 memory shards 做 prefill、routing 和 cache 组织 |
| Runtime configs | src/config/memory_config.py, EverMind-AI/MSA-4B/config.json | GenerateConfig, ModelConfig, MemoryConfig, msa_config | doc_top_k=16、pooling_kernel_size=64、router_layer_idx=18-35、block_size=16000 |
| Benchmarks / evaluation | src/app/benchmark.py, src/benchmarks.py, scripts/run_benchmarks.sh | benchmark registry / runner | 支持 README 中列出的 QA benchmark;LLM-as-judge 由 scripts/calculate_llm_score.sh 触发 |
4. Experimental Setup (实验设置)
4.1 任务与数据集
论文在两个维度上评测 MSA:
- Question Answering (QA)
- 9 个 benchmark:
- MS MARCO v1
- Natural Questions
- DuReader
- TriviaQA (10M)
- NarrativeQA
- PopQA
- 2WikiMultiHopQA
- HotpotQA
- MuSiQue
- memory bank 规模从 277K 到 10M tokens
- 9 个 benchmark:
- Needle-In-A-Haystack (NIAH)
- 使用 RULER
- 8 个子任务
- context length 从 32K 到 1M
4.2 指标
- QA
- 评测指标是 LLM judge score(0–5)
- 对标准 RAG,用固定检索深度报告
R@1 / R@5 / R@10 - 对 MSA,用
@adaptive,即模型自己决定需要检索多少文档
- NIAH
- 报告 8 个 RULER 子任务的平均 accuracy
4.3 模型与训练配置
- Backbone: Qwen3-4B-Instruct-2507
- Initialization:
- backbone 参数来自官方预训练权重
- router projectors 随机初始化
- Continuous Pre-training:
- 语料规模:158.95B tokens
- 目标:Generative Retrieval + auxiliary routing supervision
- 关键超参数(released checkpoint / inference config):
EverMind-AI/MSA-4B/config.json:num_hidden_layers=36,hidden_size=2560,num_attention_heads=32,num_key_value_heads=8msa_config:pooling_kernel_size=64,top_k_docs=16,router_layer_idx=18-35,decouple_router=True- routing reductions:
head_reduce_method=mean,query_reduce_method=max,chunk_reduce_method=max - auxiliary config:
aux_loss_method=INFONCE_DECOUPLE,infonce_loss_temp=0.1,auxloss_weight=0.1; released inference checkpoint setsaux_loss=False src/config/memory_config.pydataclass defaults:model_path="EverMind-AI/MSA-4B",GenerateConfig.max_generate_tokens=256,top_p=0.9,temperature=0.0,MemoryConfig.block_size=16000,slice_chunk_size=16384- benchmark runner overrides:
scripts/run_benchmarks.shsetsmax_length=2048and passes--block_size 2048;src/app/benchmark.pydefaults are--block_size 2048,--max_length 64when not overridden
- 模型变体:
- MSA-S1:只做第一阶段 post-training,memory context = 8K
- MSA-S2:完整 two-stage curriculum,memory context 从 8K 扩到 64K
- 代码可复现边界:仓库公开了 inference / benchmark / model implementation,但未公开完整 training launch script;因此 158.95B-token pretraining、warm-up LR 、main LR 、SFT curriculum 等训练数字仍来自论文/README,而不是可执行训练配置文件。
4.4 基线
QA 基线
- same-backbone RAG
- Qwen3-4B-Embedding + Qwen3-4B-Instruct-2507
- RAG + reranking(加 Qwen3-4B-Rerank)
- HippoRAG2
- best-of-breed RAG
- KaLMv2-Embedding-Gemma3-12B-2511 作 retriever
- generator 用 Qwen3-235B-Instruct-2507 或 Llama-3.3-70B-Instruct
- 可选 reranker:Qwen3-8B-Rerank
NIAH 基线
- Qwen3-4B-Instruct
- Qwen2.5-14B-1M
- Qwen3-30B-A3B
- Qwen3-Next-80B-A3B
- RL-MemoryAgent-14B
4.5 硬件与系统
- 论文明确声称:100M token inference 可以在 2×A800 GPUs 上运行
- 但完整训练硬件配置没有完全展开;只详细说明了推理时的 Memory Parallel / tiered storage 设计
5. Experimental Results (实验结果)
5.1 极端长度扩展:16K → 100M 只掉不到 9%
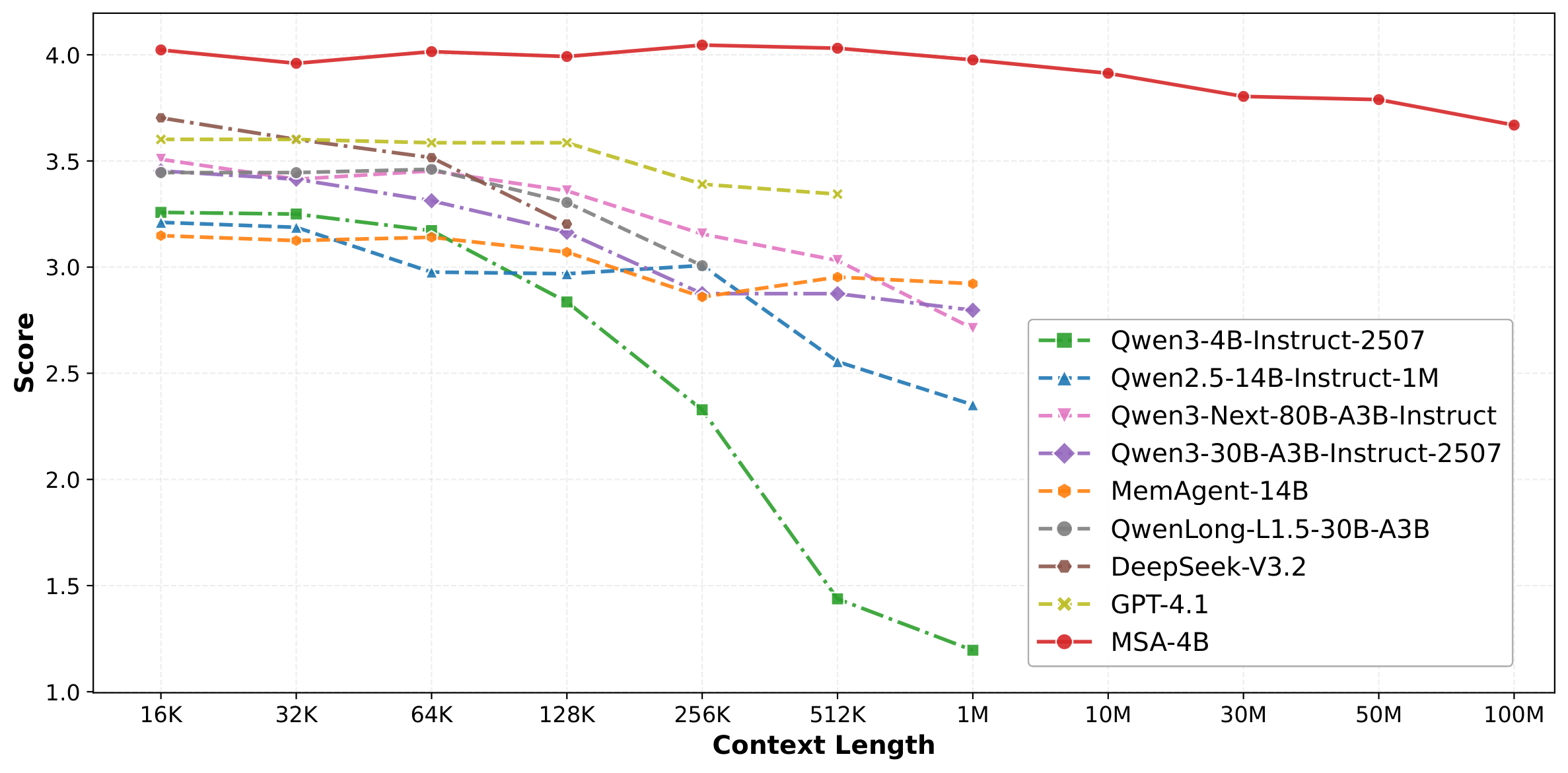
Figure 1 解读:这张图是论文最抓人的结果图。横轴从 16K 一直拉到 100M token,MSA 曲线始终保持在最上方,从约 4.02 降到约 3.67,整体 degradation < 9%。相比之下,普通 Qwen3-4B backbone 在 128K 之后急剧崩塌,到 512K 已接近失效;很多 long-context 或 memory baseline 也会在 1M 之前就明显掉点。这说明 MSA 不是单纯“能跑超长上下文”,而是 能在超长上下文下保持有效推理质量。
作者在分析部分进一步给出了复杂度结论:
其中 是总 memory size, 是 query length, 是平均 document length, 是 Top-k 文档数, 是 pooling size。也就是说,MSA 的核心卖点并不是低常数,而是把 memory scaling 的主导项变成线性。
5.2 QA:对 same-backbone RAG 全面领先
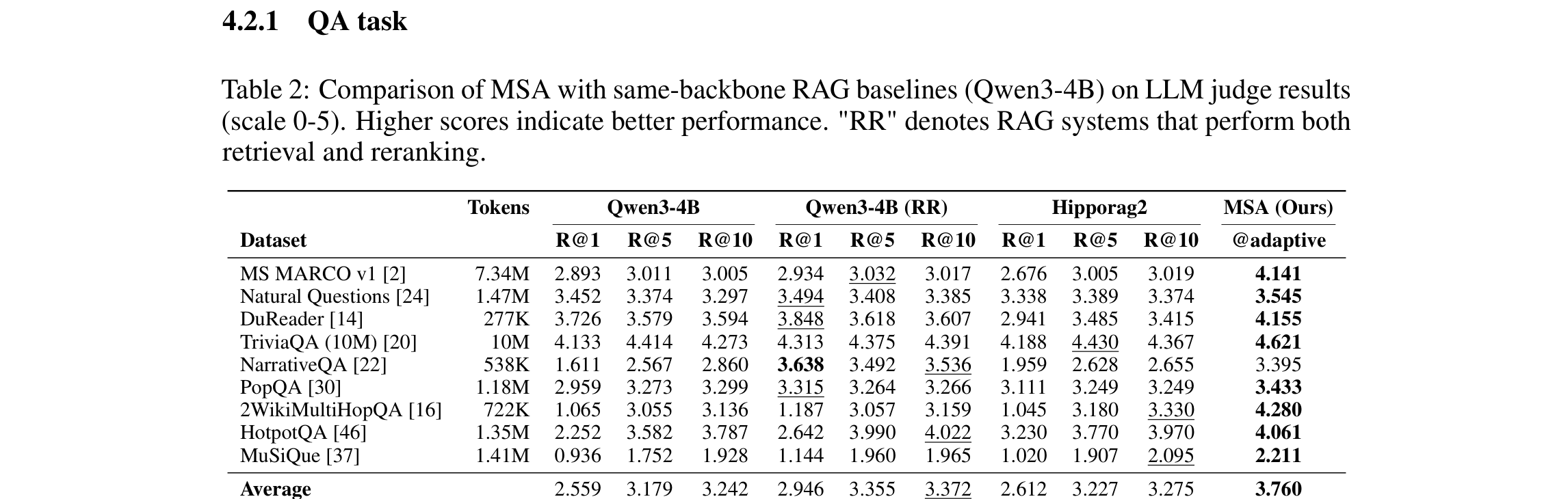
Table 2 解读:在和相同 backbone(Qwen3-4B)构造的 RAG baseline 对比时,MSA 在 9 个 QA benchmark 里除 NarrativeQA 外全部第一,平均分达到 3.760。而对手的 best average 分别是:标准 RAG 3.242、RAG+RR 3.372、HippoRAG2 3.275。作者给出的相对提升是:对 best RAG 分别提升 16.0% / 11.5% / 14.8%。
几个最有代表性的点:
- MS MARCO v1:MSA 4.141,显著高于 Qwen3-4B(RR) 的 3.032
- DuReader:MSA 4.155,高于 same-backbone best 的 3.848
- 2WikiMultiHopQA:MSA 4.280,远高于 best RAG 的 3.330
- HotpotQA:MSA 4.061,高于 HippoRAG2 的 3.970
唯一明显没赢的是 NarrativeQA:
- Qwen3-4B(RR) 最好为 3.638
- MSA 为 3.395
这说明 MSA 对 multi-hop 和 large-memory QA 非常强,但对某些更偏长篇叙事理解的数据,并不保证全面碾压 reranked RAG。
5.3 QA:面对大模型 RAG 仍然能打
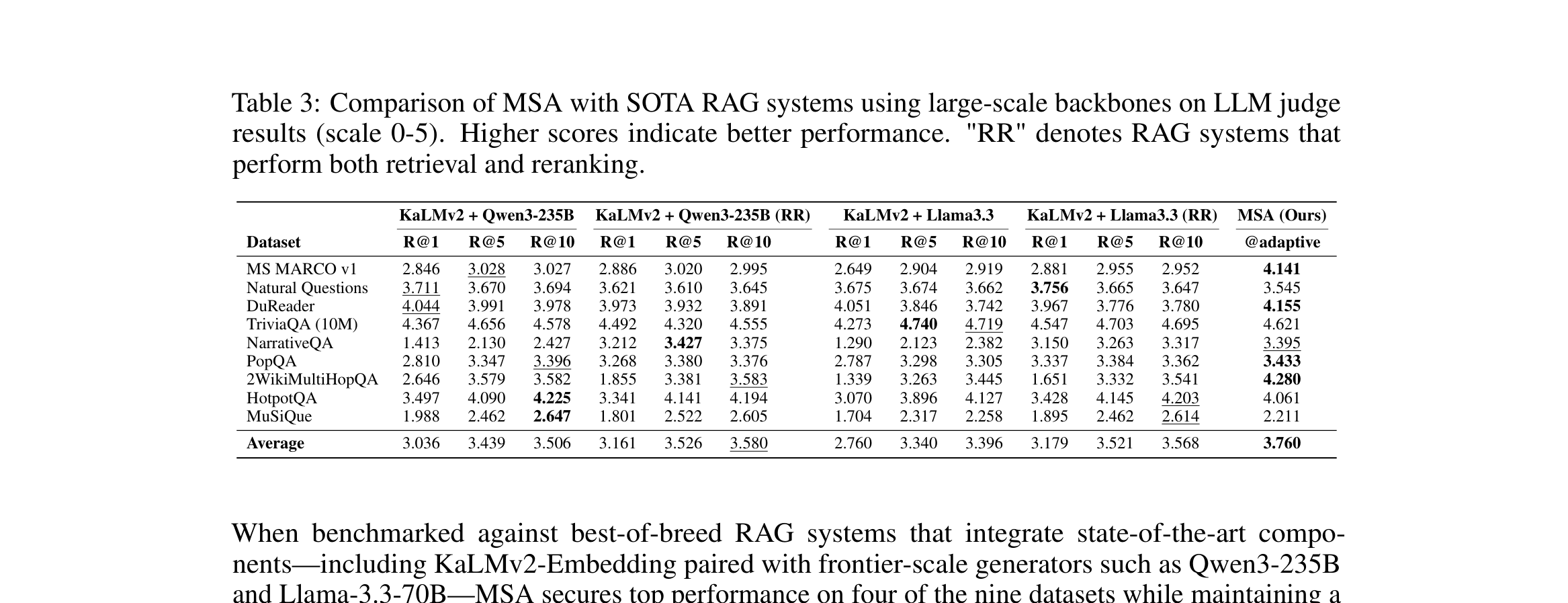
Table 3 解读:这里对手已经不是 same-backbone,而是 KaLMv2 + Qwen3-235B / Llama-3.3-70B 这种大规模 SOTA RAG 组合。即便如此,MSA 的平均分仍然达到 3.760,比最强平均基线 3.580(KaLMv2 + Qwen3-235B + RR)还高,作者按 strongest configuration 统计给出 +5.0% 的平均优势。
MSA 在 9 个数据集里拿下 4/9 的绝对最佳:
- MS MARCO v1:4.141
- DuReader:4.155
- PopQA:3.433
- 2WikiMultiHopQA:4.280
落后的数据集也值得注意:
- Natural Questions:3.545,低于 3.756
- TriviaQA:4.621,低于 4.740
- HotpotQA:4.061,低于 4.225
- MuSiQue:2.211,明显低于 2.647
论文作者自己的解释也很合理:在 MuSiQue 这类 multi-hop reasoning benchmark 上,235B generator 的参数规模和内在推理能力本身就更强,而 MSA 只有 4B。
这部分结果说明:
MSA 的价值不是“在同样参数下略优于 RAG”,而是 即使只用 4B backbone,也能把 memory mechanism 做到足够强,从而和大模型 RAG 组合正面对抗。
5.4 NIAH:1M token 下仍保持 94.84%
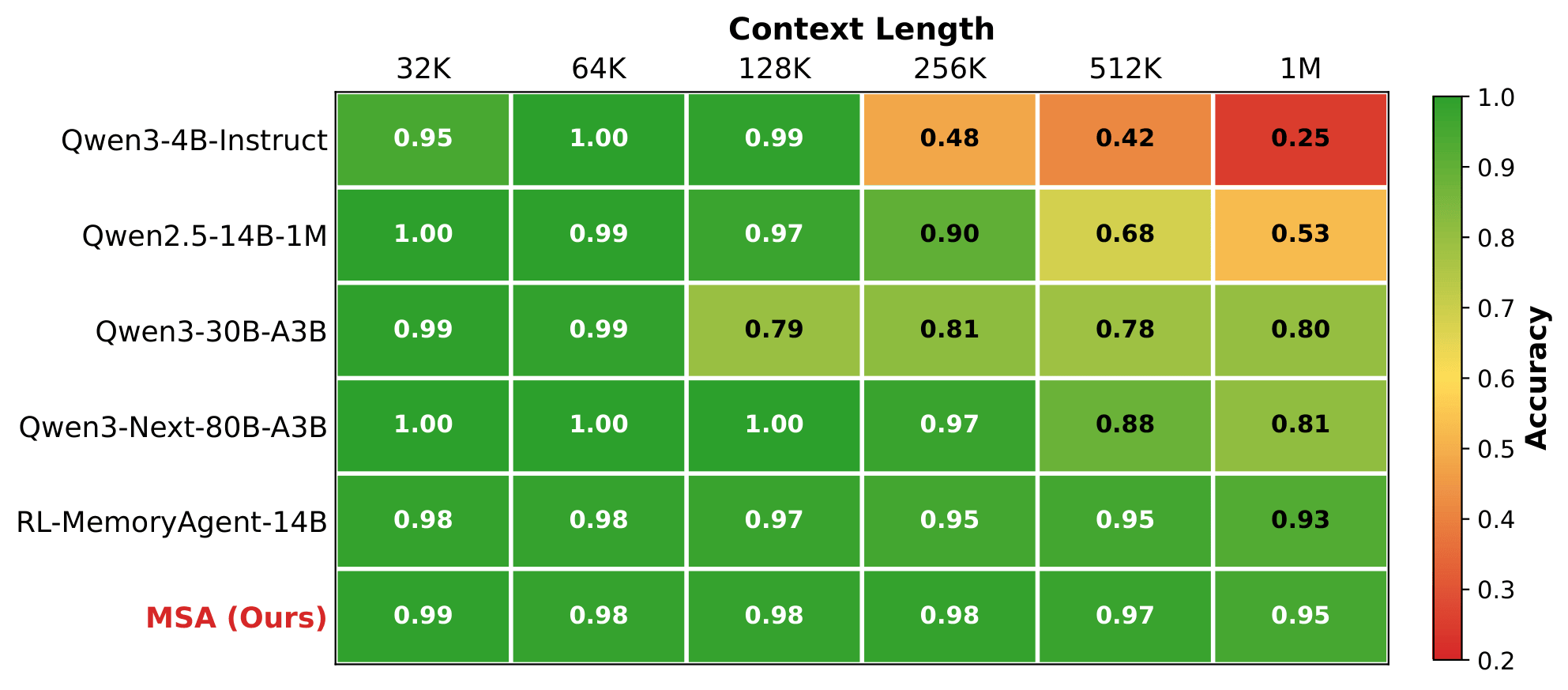
Figure 4 解读:这张热力图显示 MSA 在 RULER NIAH 上从 32K 一路扩到 1M token,准确率从 0.99 / 0.98 / 0.98 / 0.98 / 0.97 / 0.95 平滑下降,到 1M 仍是 94.84%。对比之下,原始 Qwen3-4B-Instruct 到 1M 只剩 24.69%;Qwen2.5-14B-1M 到 1M 是 52.53%;Qwen3-Next-80B-A3B 到 1M 约 80.78%;RL-MemoryAgent-14B 虽较稳,但 1M 也只有 92.66%。
更关键的是下降幅度:
- MSA:从 32K 的 98.77% 降到 1M 的 94.84%,只掉 3.93 个百分点
- RL-MemoryAgent-14B:从 98.42% 降到 92.66%,掉 5.76 个百分点
这说明 document-wise RoPE + sparse latent retrieval 的组合,确实让模型对超长 context 外推更稳。
5.5 Ablation:四个设计都不能随便删
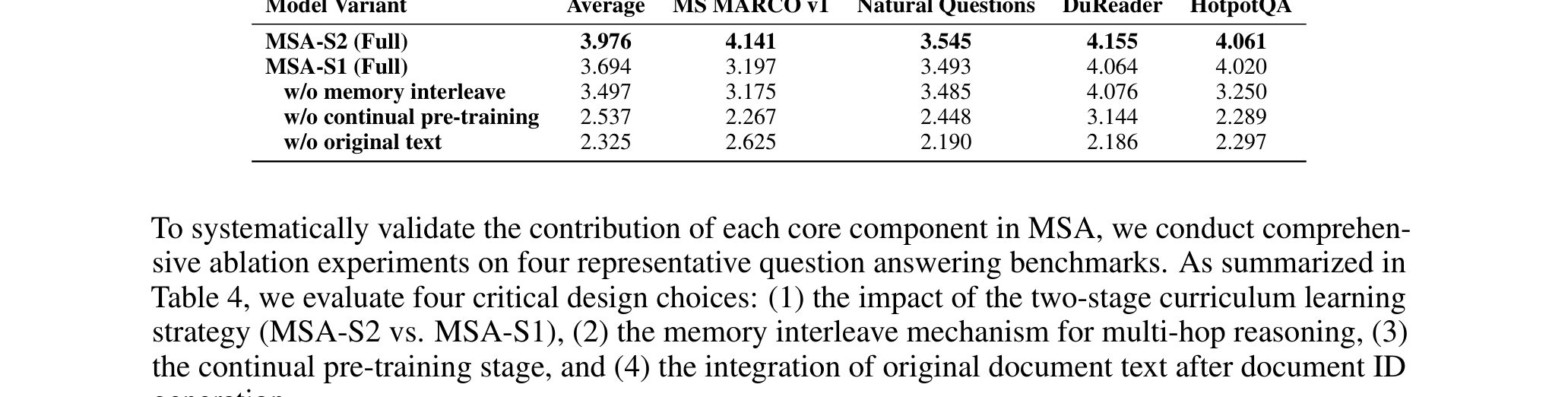
Table 4 解读:作者在四个 QA 数据集上做了非常有信息量的消融。完整的 MSA-S2 平均分 3.976,完整的 MSA-S1 是 3.694。去掉不同组件以后,分数分别掉到:
- w/o memory interleave:3.497
- w/o continual pre-training:2.537
- w/o original text:2.325
对应的关键信息是:
- Curriculum Learning 有效
- MSA-S2 vs MSA-S1:平均提升约 7.6%
- 在 MS MARCO 上从 3.197 → 4.141,提升尤其大
- Memory Interleave 对 multi-hop 很关键
- 平均从 3.694 掉到 3.497(约 -5.3%)
- HotpotQA 从 4.020 → 3.250,掉幅最大
- Continual Pre-training 是基础能力来源
- 平均从 3.694 掉到 2.537(约 -31.3%)
- HotpotQA 从 4.020 → 2.289,几乎崩盘
- Original Text 注入不能省
- 平均从 3.694 掉到 2.325(约 -37.1%)
- DuReader 从 4.064 → 2.186,掉了 46.2%
这个 ablation 很说明问题:MSA 不是只靠某一个 sparse retrieval trick 成功,而是 routing、continual pretraining、原文语义注入、multi-round interleave 几个组件协同工作。
5.6 局限性与总体结论
论文自己承认的局限主要有两点:
- 当任务需要跨多个文档、强耦合、结构紧密的信息对齐时,仅靠 intrinsic latent memory 仍然不够稳。
- Memory Interleave 是一个 promising direction,但当前设计还不够“principled”和高效,仍有改进空间。
我自己的补充判断:
- 优点
- 这是少数真正把“memory scaling”当成一等公民来设计的 LLM memory paper
- 兼顾了 architecture compatibility、end-to-end trainability、lifetime-scale inference 和 latency-aware system design
- 实验不只是秀一个 curve,而是覆盖 same-backbone RAG、large-backbone RAG、NIAH、ablation、efficiency
- 不足
- 代码已公开 inference / benchmark / model implementation,但没有公开完整训练脚本与数据构造 pipeline;论文中的训练 schedule 仍无法端到端复现
- released code 依赖 FlashAttention、Qwen3/Transformers 版本和自定义
doc_ids/cache 约定,可移植到其他 backbone 时工程成本不低 - 主要任务仍集中在 QA / NIAH,是否能直接泛化到更广义的 agent memory、长期对话 persona、或 continuous world modeling,还需要更多验证
总体来说,这篇论文最重要的价值不只是“又一个 long-context trick”,而是提出了一个更完整的判断标准:
真正可用的 LLM memory,不应该只是更长的 context window,而应该是一个 可训练、可路由、可压缩、可扩展到 100M token 的内生记忆系统。
现在代码已经公开,MSA 的价值判断更清楚:它不是只提出一个公式,而是给出了可运行的 latent-memory attention、cache staging、benchmark runner 和 multi-round retrieval 状态机;下一步最需要验证的是训练 recipe 与更广义 agent / long-horizon tasks 的可迁移性。