Recursive Multi-Agent Systems
Paper: arXiv:2604.25917 Code: RecursiveMAS/RecursiveMAS Code reference:
main@bfb0a4e9(2026-05-02)
1. Motivation (研究动机)
现有 LLM-based multi-agent systems(MAS)通常把协作建立在显式文本消息上:Planner、Critic、Solver、Tool-Caller 等 agent 需要先把中间想法解码成 token,再交给下一个 agent 重新编码。这带来三个瓶颈:一是每轮协作都要付出 vocabulary-space decoding 的延迟和 token 成本;二是文本消息把连续 hidden-state 压成离散语言,信息传递受限;三是 prompt/feedback 式优化只能改上下文或指令,难以让整个 MAS 作为一个端到端系统共同学习。
这篇论文要解决的具体问题是:能否把“单模型 recursive / looped computation”的 scaling axis 扩展到多 agent 协作本身,让整个 agent system 在 latent space 中递归地传递、修正和共同优化,而不是让每个 agent 作为孤立模块输出文本。
这个问题值得研究,因为 MAS 的优势本来就在于异构角色组合;如果协作通道仍依赖长文本,系统越复杂越慢、越贵、越难训练。RecursiveMAS 的目标是把协作本身变成可训练的连续计算图,从而同时提升推理精度、端到端速度和 token efficiency。
2. Idea (核心思想)
核心洞察:把整个 multi-agent system 看成一个 recursive computation graph;每个 agent 类似 recursive language model 中的一层,agent 间不传递文本,而是通过轻量 RecursiveLink 传递 latent thoughts。 Inner RecursiveLink 负责同一 agent 内部的 latent auto-regressive generation,Outer RecursiveLink 负责异构 agent hidden-state 之间的维度/分布对齐。
关键创新是两层:架构上,RecursiveMAS 用 residual MLP adapter 把 agent 串成闭环,使中间轮次完全在 latent space 协作,最后一轮才由末端 agent decode 文本;训练上,论文提出 inner-outer loop learning,先 warm up 每个 agent 的 inner link,再保留跨轮计算图,用最终预测的 CE loss 共享地给所有 outer links 分配 credit。
与 TextGrad / prompt refinement 相比,它不是把自然语言反馈写回 prompt;与 MoA 相比,它不是并行产生文本再聚合;与 LoopLM 相比,它把递归从单个模型内部扩展到系统级;与 Recursive-TextMAS 相比,它保留相同 recursive MAS 拓扑但把中间通信从 text 改为 latent states。
3. Method (方法)
3.1 Overall framework:把 MAS 变成 latent-space recursive loop
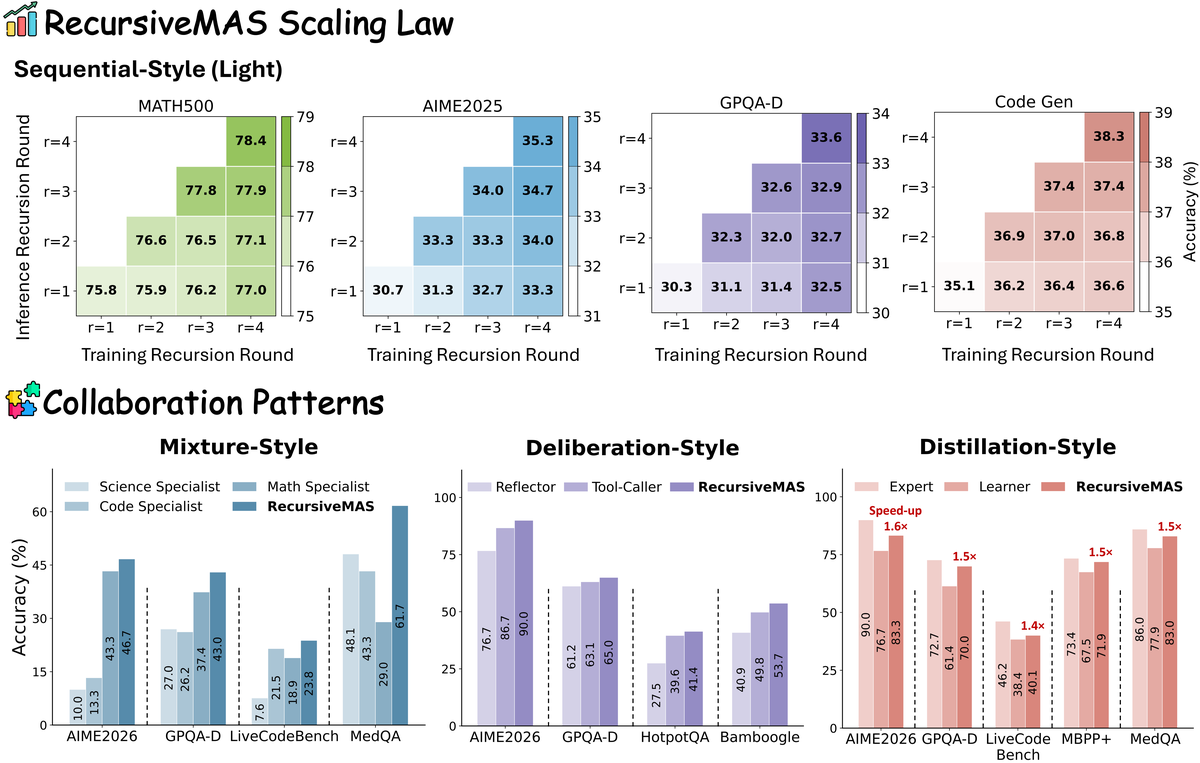
Figure 1 解读:上半部分展示 training-time recursion 与 inference-time recursion 的 scaling landscape:训练和推理递归轮数同时增加时性能最高。下半部分展示 RecursiveMAS 在 sequential、mixture、distillation、deliberation 等多种 MAS 结构中都能带来增益,说明方法不是绑定某个固定拓扑。

Figure 2 解读:RecursiveMAS 将多个异构 agent 组织成闭环。每个 agent 在自身内部生成 latent thoughts,然后通过 outer RecursiveLink 传给下一个 agent;最后一个 agent 的 latent output 又反馈回第一个 agent,形成多轮递归。关键是中间轮次不输出文本,只在隐藏空间中协作,最终轮才 decode final answer。
形式化地,单模型 latent generation 先由标准 Transformer 在 continuous representation 中递推:
Recursive computation 则复用同一变换多轮细化 hidden states:
RecursiveMAS 把这个思想推广到 个 agent 组成的系统 :每个 agent 的 latent state 是系统 collective latent state 的一部分,递归演化是 。
3.2 RecursiveLink:同 agent 内递归 + 跨 agent latent transfer

Figure 3 解读:Inner link 用在同一 agent 内,把 last-layer embedding 映射回 input embedding space,使 agent 能继续以 latent thought 形式自回归生成;Outer link 用在不同 agent 之间,通过额外 residual projection 处理 hidden dimension / embedding distribution 不一致的问题。残差分支保留原始语义,MLP 分支只需学习分布偏移。
Inner RecursiveLink 对同一 agent 的 last-layer hidden vector 做二层 residual 变换:
其中 是 GELU。Outer RecursiveLink 用额外线性层 把 source agent 的 hidden state 投到 target agent 空间:
直觉上,RecursiveLink 不是让小 adapter 重新学完整语义,而是让 residual path 保持语义连续性,MLP path 只修正“上一 agent / 上一步 hidden-state 分布”和“下一 agent input embedding 分布”之间的偏移。这也是为什么论文在 Table 4 中看到 residual + 2-layer 设计最稳。
**论文公式与 released code 实现差异:**论文公式 (3)(4) 写的是简化 residual MLP;released code 的 modeling.py 在 inner/outer adapter 前后都加入 LayerNorm,且 outer adapter 的 hidden dimension 是 out_dim * 2。因此笔记中的伪代码以 code 为准,公式解释以 paper 为准。
3.3 Inner-Outer Loop learning:先 warm-up latent thought,再系统级 credit assignment
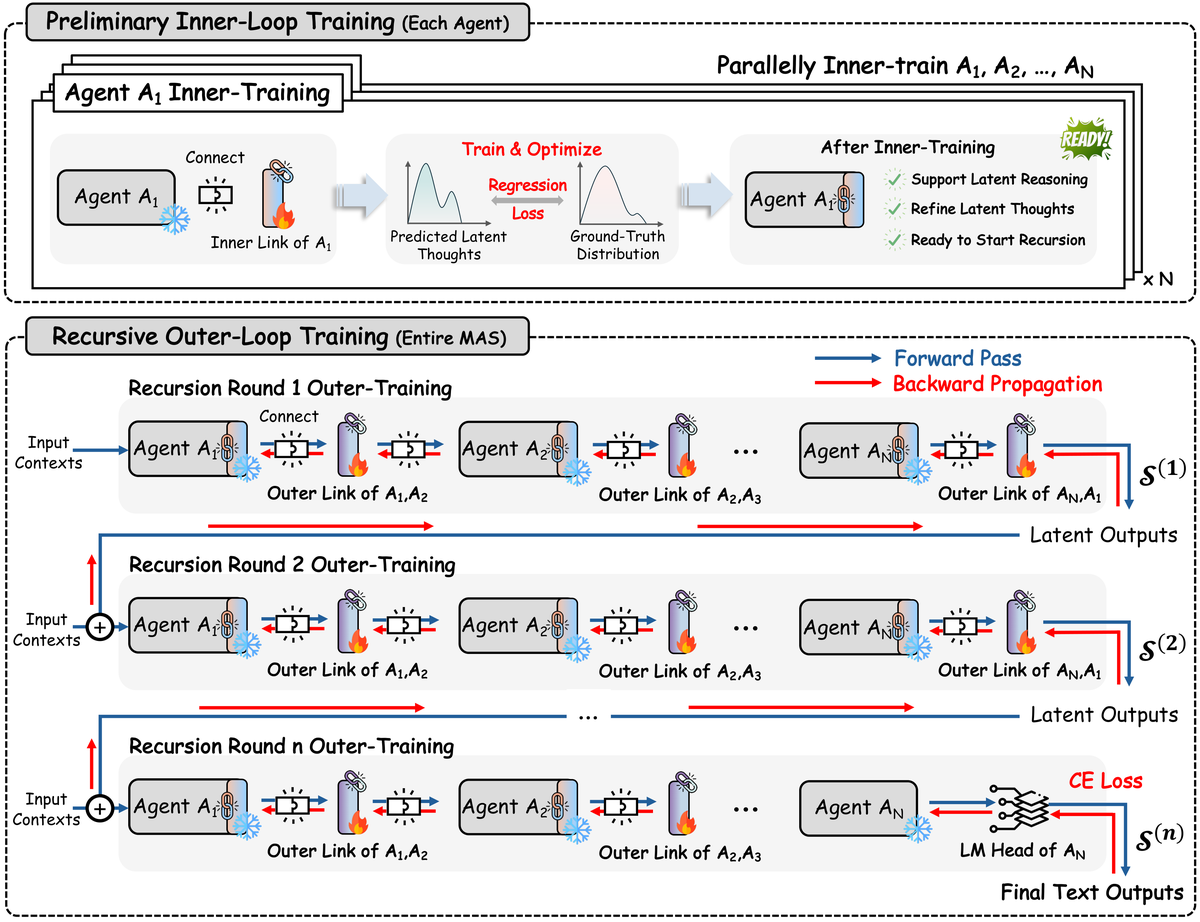
Figure 4 解读:训练分两段。第一段对每个 agent 并行做 inner-loop training,使 inner RecursiveLink 学会把模型产生的 latent thoughts 对齐到 ground-truth text 的 embedding distribution。第二段把整个 MAS 按递归轮次 unroll,最终文本预测产生 CE loss,梯度沿完整计算图回传到所有 outer links,实现 system-level co-optimization。
Inner-loop 训练目标是让 inner link 输出贴近 ground-truth answer 的 input-embedding distribution:
Outer-loop 将系统递归 unroll 轮后,只在最终文本预测上用交叉熵:
论文还给出两条理论解释。复杂度上,text-based recursive MAS 需要
而 RecursiveLink-enabled collaboration 将 expensive vocabulary decoding 项替换为 latent transform:
由于实践中 ,这解释了为什么递归越深,latent-space 通信相对 text communication 的速度和 token 优势越明显。学习动态上,Theorem 4.1 说明 confident-token text recursion 的梯度范数趋近 ,而 RecursiveLink 的梯度可保持接近常数级:
3.4 PyTorch-style pseudocode(基于 released code)
Inner RecursiveLink released code 对应 modeling.py::Adapter,比论文公式多了 pre/post LayerNorm:
import torch
import torch.nn as nn
class InnerRecursiveLink(nn.Module):
def __init__(self, hidden_size: int):
super().__init__()
self.proj1 = nn.Linear(hidden_size, hidden_size)
self.act = nn.GELU()
self.proj2 = nn.Linear(hidden_size, hidden_size)
self.pre_ln = nn.LayerNorm(hidden_size)
self.post_ln = nn.LayerNorm(hidden_size)
def forward(self, x: torch.Tensor) -> torch.Tensor:
h = self.pre_ln(x)
delta = self.proj2(self.act(self.proj1(h)))
return self.post_ln(x + delta)Outer RecursiveLink released code 对应 modeling.py::CrossModelAdapter,将 source hidden size 映射到 target hidden size:
class OuterRecursiveLink(nn.Module):
def __init__(self, in_dim: int, out_dim: int):
super().__init__()
hidden_dim = out_dim * 2
self.ln_source = nn.LayerNorm(in_dim)
self.proj1 = nn.Linear(in_dim, hidden_dim)
self.act = nn.GELU()
self.proj2 = nn.Linear(hidden_dim, out_dim)
self.residual_proj = nn.Linear(in_dim, out_dim)
self.ln_target = nn.LayerNorm(out_dim)
def forward(self, x: torch.Tensor) -> torch.Tensor:
h = self.ln_source(x)
delta = self.proj2(self.act(self.proj1(h)))
return self.ln_target(self.residual_proj(x) + delta)Sequential-style inference 的 released pipeline 在 inference_utils/inference_mas.py 中按 Planner → Critic/Refiner → Solver → Planner feedback 执行 latent rollout:
@torch.no_grad()
def sequential_recursive_inference(batch, agents, links, args):
feedback_to_planner = None
final_text = None
for round_id in range(args.num_recursive_rounds):
planner_prompt = build_planner_prompt(batch, feedback_to_planner)
planner_hidden = autoregressive_latent_rollout(
model=agents["planner"].model,
rollout_inner_adapter=agents["planner"].inner_link,
input_embeds=embed(planner_prompt),
attention_mask=mask(planner_prompt),
latent_steps=args.latent_steps,
)
planner_latent = run_inner_adapter(agents["planner"].inner_link, planner_hidden)
planner_to_refiner = run_outer_adapter(links["outer_12"], planner_latent)
refiner_hidden = autoregressive_latent_rollout(
model=agents["critic"].model,
rollout_inner_adapter=agents["critic"].inner_link,
input_embeds=concat(embed_refiner_prompt(batch), planner_to_refiner),
attention_mask=None,
latent_steps=args.latent_steps,
)
refiner_latent = run_inner_adapter(agents["critic"].inner_link, refiner_hidden)
refiner_to_solver = run_outer_adapter(links["outer_23"], refiner_latent)
solver_hidden = autoregressive_latent_rollout(
model=agents["solver"].model,
rollout_inner_adapter=agents["solver"].inner_link,
input_embeds=concat(embed_solver_prompt(batch), refiner_to_solver),
attention_mask=None,
latent_steps=args.latent_steps,
)
solver_latent = run_inner_adapter(agents["solver"].inner_link, solver_hidden)
feedback_to_planner = run_outer_adapter(links["outer_31"], solver_latent)
final_text = run_text_generation_stage(
model_name_or_path=agents["solver"].path,
user_prompts=build_final_solver_prompts(batch, refiner_to_solver),
max_new_tokens=args.max_new_tokens,
temperature=args.temperature,
top_p=args.top_p,
)
return final_text论文训练算法的 released repo 尚未给出完整训练脚本;下面是按论文 Figure 4 / Eq. (5)(6) 的 algorithm-level pseudocode,而不是 code-verified training implementation:
def train_recursivemas(agent_system, dataloader, inner_links, outer_links, optimizer):
for agent in agent_system.agents:
for x, y in dataloader:
h = agent.rollout_latent(x, inner_links[agent])
target = agent.embed_text(y)
loss_in = 1.0 - torch.cosine_similarity(inner_links[agent](h), target).mean()
loss_in.backward()
optimizer.step(); optimizer.zero_grad()
for x, y in dataloader:
state = agent_system.initialize_state(x)
for _ in range(agent_system.num_recursive_rounds):
state = agent_system.forward_one_round(state, inner_links, outer_links)
logits = agent_system.decode_final_agent(state)
loss_out = torch.nn.functional.cross_entropy(logits, y)
loss_out.backward()
optimizer.step(); optimizer.zero_grad()3.5 Code-to-paper mapping
Code reference:
main@bfb0a4e9(2026-05-02) — pseudocode and mapping based on this commit
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Inner RecursiveLink | modeling.py | Adapter.forward |
| Outer RecursiveLink | modeling.py | CrossModelAdapter.forward |
| Released MAS style/checkpoint map | load_from_repo.py | STYLE_SPECS, DATASET_DEFAULT_SPLIT |
| High-level system loading | system_loader.py | LoadedMASSystem, load_mas_system, _OUTER_LAYOUTS |
| Sequential latent inference | inference_utils/inference_mas.py | autoregressive_latent_rollout, run_inner_adapter, run_outer_adapter, run_refiner_latent_stage |
| CLI inference defaults | run.py | build_parser, build_common_cli, apply_recommended_settings |
| Mixture / distill / deliberation variants | inference_utils/inference_mas_mixture.py, inference_utils/inference_mas_distill.py, inference_utils/inference_mas_deliberation.py | style-specific inference pipelines |
| Answer extraction / code eval helpers | inference_utils/answer_utils.py, inference_utils/lcb_utils.py | benchmark-specific evaluation utilities |
Released code gap:README.md 明确说完整 training/inference pipeline 和全部 training data/implementation details 仍是 TODO;当前 commit 主要提供 checkpoint loading 与 downstream inference demo。因此 paper 的 inner-outer training objective 可从论文公式复现,但不能从 released repo 的训练脚本逐行核验。
4. Experimental Setup (实验设置)
4.1 Tasks / datasets
论文覆盖 9 个 benchmark:
- Mathematical Reasoning:MATH500(500 道 MATH 子集题)、AIME2025(30 道 competition math)、AIME2026(30 道 competition math)。AIME2025/2026 报告 Pass@10 accuracy。
- Scientific / Medical:GPQA-Diamond、MedQA。论文描述 GPQA-Diamond 为 GPQA 最难 split;MedQA 为 medical licensing-style questions;具体测试样本数论文未详细说明。
- Code Generation:LiveCodeBench-v6、MBPP Plus。代码题通过提取 generated code block 并在 sandbox 中跑测试;具体测试样本数论文未详细说明。
- Search QA:HotpotQA、Bamboogle。两者用于 multi-hop / search-intensive QA;具体测试样本数论文未详细说明。
4.2 Collaboration styles and models
Table 1 中的 4 类 MAS 拓扑:
| Collaboration Pattern | Roles / Models |
|---|---|
| Sequential Light | Planner: Qwen3-1.7B; Critic: Llama3.2-1B-Instruct; Solver: Qwen2.5-Math-1.5B-Instruct |
| Sequential Scaled | Planner: Gemma3-4B-it; Critic: Llama3.2-3B-Instruct; Solver: Qwen3.5-4B |
| Mixture | Code Specialist: Qwen2.5-Coder-3B-Instruct; Science Specialist: BioMistral-7B; Math Specialist: DeepSeek-R1-Distill-Qwen-1.5B; Summarizer: Qwen3.5-2B |
| Distillation | Learner: Qwen3.5-4B; Expert: Qwen3.5-9B |
| Deliberation | Reflector: Qwen3.5-4B; Tool-Caller: Qwen3.5-4B with Tool-Integration |
主要 baselines 包括 Single Agent(LoRA / Full-SFT)、Mixture-of-Agents(MoA)、TextGrad、LoopLM、Recursive-TextMAS,以及各 collaboration pattern 下的 standalone role agents。
4.3 Training / inference config
论文报告的训练设置:冻结所有 LLM agent 参数,只训练 inner / outer RecursiveLink;训练数据来自 s1K(math)、m1k(medical/science)、OpenCodeReasoning(code)、ARPO-SFT(agentic tool augmentation)。优化器为 AdamW,learning rate ,cosine LR scheduler,batch size 4;结果为 5 次 independent runs 的均值。训练硬件在 appendix 中描述为 H100 和 A100 GPUs。
论文报告的推理设置:top-p = 0.95;大多数 reasoning tasks temperature = 0.6,code generation temperature = 0.2;maximum generation length 按任务调节,appendix 中给出 MATH500 为 2000 tokens,MedQA / GPQA-Diamond / LiveCodeBench / MBPP Plus 为 4000 tokens,AIME2025/2026 为 16000 tokens。
Released code 中可核验的 inference defaults:run.py 默认 num_recursive_rounds=3、latent_length=32、temperature=0.6、top_p=0.95,math500 在 non-light style 下 max_new_tokens=2000,其他 dataset 为 4000;inference_utils/inference_mas.py 的 release recommended settings 对 sequential-light / sequential-scaled 设定了 dataset-specific batch_size 和 latent_length(例如 sequential_light/math500: batch_size=32, latent_length=48;sequential_scaled/gpqa: batch_size=16, latent_length=48)。Released repo 未提供完整训练 launch script,因此训练超参不能从代码配置文件二次验证。
5. Experimental Results (实验结果)
5.1 Main comparison at recursion round
Table 3 在相同训练预算和模型设置下比较 whole-system performance:
| Method | MATH500 | AIME2025 | AIME2026 | GPQA-D | LiveCodeBench | MedQA |
|---|---|---|---|---|---|---|
| Single Agent (w/ LoRA) | 83.1 | 70.0 | 73.3 | 62.0 | 37.4 | 76.1 |
| Single Agent (w/ Full-SFT) | 83.2 | 73.3 | 76.7 | 62.8 | 38.6 | 77.0 |
| Mixture-of-Agents (MoA) | 79.8 | 60.0 | 63.3 | 47.6 | 27.0 | 57.5 |
| TextGrad | 84.9 | 73.3 | 76.7 | 62.5 | 39.8 | 77.2 |
| LoopLM | 84.6 | 66.7 | 63.3 | 48.1 | 24.9 | 56.4 |
| Recursive-TextMAS | 85.8 | 73.3 | 73.3 | 61.6 | 38.7 | 77.0 |
| RecursiveMAS | 88.0 | 86.7 | 86.7 | 66.2 | 42.9 | 79.3 |
论文总结 RecursiveMAS 相对每个 benchmark 的 strongest baseline 平均提升 8.3%;在 reasoning-intensive tasks 上,AIME2025 提升 18.1%,AIME2026 提升 13.0%,GPQA-Diamond 提升 5.4%。
5.2 Recursion depth scaling:精度、速度、token 同时改善
Table 2 对 Recursive-TextMAS 和 RecursiveMAS 在 下比较。论文报告平均性能提升随递归加深更明显: 平均 +8.1%, 平均 +19.6%, 平均 +20.2%。效率上,RecursiveMAS 相比 text-based recursion 的端到端 inference speedup 从 1.2× 增至 1.9×、2.4×;overall token usage reduction 从 34.6% 增至 65.5%、75.6%。

Figure 5 解读:递归轮数增加后,text-based MAS 的每轮中间文本 decode/encode 成本线性积累;RecursiveMAS 虽然也增加 latent computation,但省去了中间 token 生成,所以相对 speedup 随 增大而扩大。

Figure 6 解读:RecursiveMAS 中间轮次不产生自然语言 token,只有最终轮输出文本,因此 token reduction 在深递归下尤其明显。 的 75.6% reduction 是全文最直接支持“latent-space communication 更便宜”的结果之一。
5.3 Ablations and analyses
RecursiveLink design ablation(Table 4):
| RecursiveLink Design | MATH500 | GPQA-D | LiveCodeBench |
|---|---|---|---|
| 1-Layer | 84.4 | 63.2 | 40.1 |
| Res+1-Layer | 86.7 | 65.3 | 41.4 |
| 2-Layer | 85.6 | 64.5 | 40.5 |
| Res+2-Layer (ours) | 88.0 | 66.2 | 42.9 |
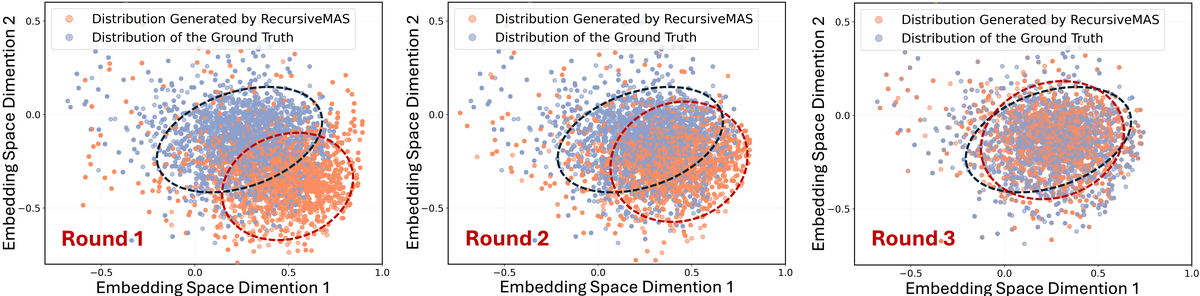
Figure 7 解读:embedding analysis 用 downstream QA 的样本比较递归过程中 latent states 与 ground-truth answer distribution 的接近程度。论文用它来说明 latent thoughts 不是任意中间向量,而是在递归后更接近正确答案语义区域。
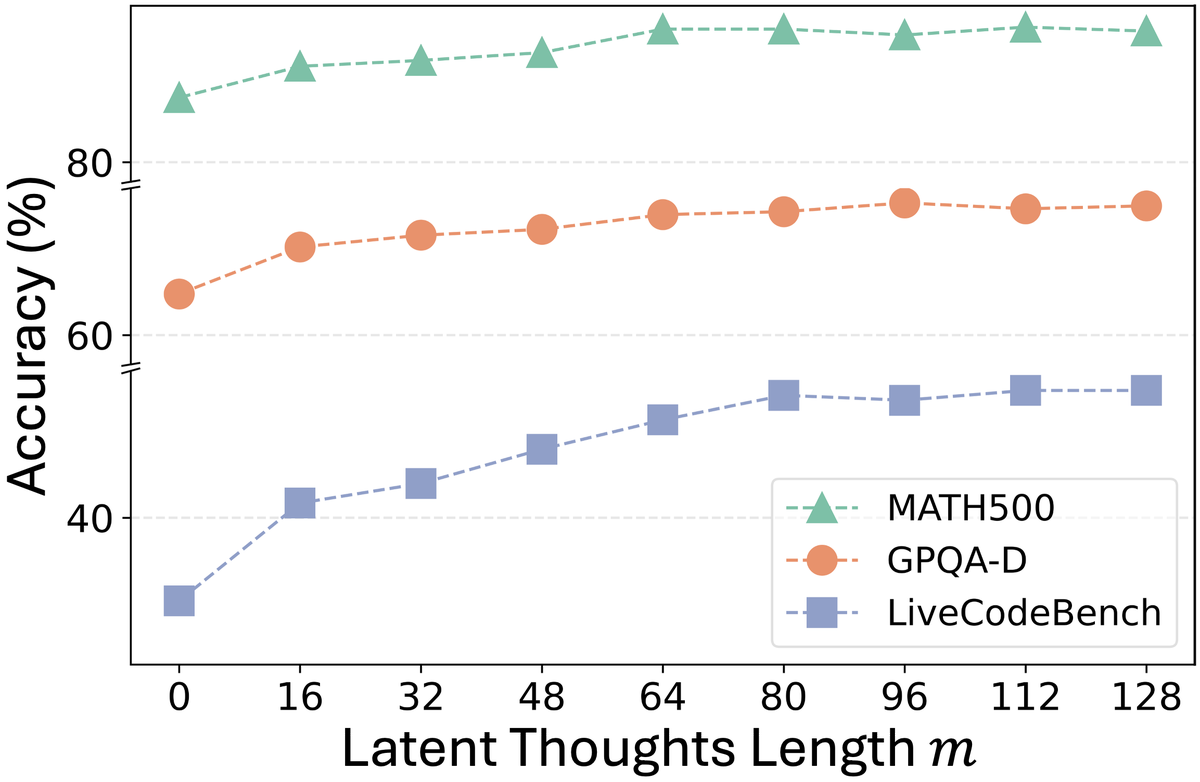
Figure 8 解读:latent thought length 过小时表达能力不足;增加 能提升性能,但到中等长度(论文描述约 )后趋于稳定,说明 RecursiveMAS 不需要像 text CoT 那样生成很长中间推理文本也能支持 agent 协作。
Cost analysis(Table 5):
| Method | GPU Mem. | Trainable Param. | Cost | Avg. Acc. |
|---|---|---|---|---|
| LoRA Training | 21.67 GB | 15.92M (0.37%) | $6.64 | 66.9 |
| Full-SFT | 41.40 GB | 4.21B (100%) | $9.67 | 68.6 |
| RecursiveMAS | 15.29 GB | 13.12M (0.31%) | $4.27 | 74.9 |
5.4 Generalization across collaboration patterns
Distillation-style(Table 6):RecursiveMAS 比 Learner 更强,同时比 Expert 快。AIME2026 / GPQA-D / LiveCodeBench / MBPP+ / MedQA 上,Expert accuracy 为 90.0 / 72.7 / 46.2 / 73.4 / 86.0,Learner 为 76.7 / 61.4 / 38.4 / 67.5 / 77.9,RecursiveMAS 为 83.3 / 70.0 / 40.1 / 71.9 / 83.0;论文总结它比 learner 平均 +8.0%,且相对 expert 保留 1.5× 端到端速度优势。
Mixture-style(Table 7):RecursiveMAS 在 AIME2026 / GPQA-Diamond / LiveCodeBench / MedQA 上为 46.7 / 43.0 / 23.8 / 61.7,高于单个 Math / Code / Science specialist 的最佳组合,论文总结平均比 strongest specialist +6.2%。
Deliberation-style(Table 8):RecursiveMAS 在 AIME2026 / GPQA-Diamond / HotpotQA / Bamboogle 上为 90.0 / 65.0 / 41.4 / 53.7;Tool-Caller 为 86.7 / 63.1 / 39.6 / 49.8;Reflector 为 76.7 / 61.2 / 27.5 / 40.9。论文总结相对原 tool-calling agent 平均 +4.8%。
5.5 Limitations / caveats
论文正文没有单独的 limitations section;作者未详细说明若干 benchmark 的实际 evaluation sample count。Released GitHub commit main@bfb0a4e9 也尚未发布完整 training pipeline / training data implementation details,因此内外循环训练可以从论文公式和图示理解,但不能从公开代码逐行复核。另一个实践 caveat 是 RecursiveMAS 需要访问 agent hidden states 和 embedding interfaces;这比普通黑盒 API agent orchestration 更依赖 open-weight / controllable model runtime。