PaperBanana: Automating Academic Illustration for AI Scientists
Authors: Dawei Zhu, Rui Meng, Yale Song, Xiyu Wei, Sujian Li, Tomas Pfister, Jinsung Yoon Affiliations: Peking University, Google Cloud AI Research arXiv: 2601.23265 Project Page: dwzhu-pku.github.io/PaperBanana GitHub: dwzhu-pku/PaperBanana
1. Motivation (研究动机)
- 学术插图是科研瓶颈: 尽管 LLM 驱动的 autonomous AI scientist 已能自动化文献综述、想法生成、实验迭代等研究流程,但生成符合出版标准的学术插图(方法论示意图和统计图表)仍然是一个显著瓶颈,需要大量人工投入。
- 现有方法的局限性:
- 代码生成方法(TikZ、Python-PPTX、SVG):虽然能处理结构化内容,但在表达复杂视觉元素(如专用图标、自定义形状)方面存在表现力限制。
- 图像生成模型(Gemini、GPT-Image 等):虽然具有强大的指令跟随和高质量视觉输出能力,但直接生成满足学术规范的插图仍然困难。
- 缺乏评估基准: 自动化学术插图生成领域缺乏专门的评估基准,阻碍了方法的严格评估和比较。
2. Idea (核心思想)
- 核心洞察: 将学术插图生成建模为一个参考驱动的多智能体协作流程——通过检索参考示例来学习”生成什么”(结构)和”如何生成”(风格),然后通过迭代自我批评来精炼输出质量。
- 关键创新: 设计了五个专业化 Agent(Retriever、Planner、Stylist、Visualizer、Critic)组成的协作团队,将插图生成分解为线性规划阶段(检索→规划→风格化)和迭代精炼循环(可视化↔批评),实现从原始科学文本到高保真出版级插图的自动转化。
- 与现有方法的本质区别: 不同于直接使用图像生成模型或代码生成的端到端方法,PaperBanana 通过显式解耦内容规划和风格优化,利用参考集合自动合成美学指南,并引入 Critic Agent 闭环反馈机制来恢复风格化过程中可能丢失的内容忠实性。
3. Method (方法)
3.1 总体框架
PaperBanana 是一个参考驱动的 agentic 框架,由五个专业化 Agent 协作完成学术插图的自动生成。整体流程分为两个阶段:Linear Planning Phase(线性规划阶段)和 Iterative Refinement Loop(迭代精炼循环)。
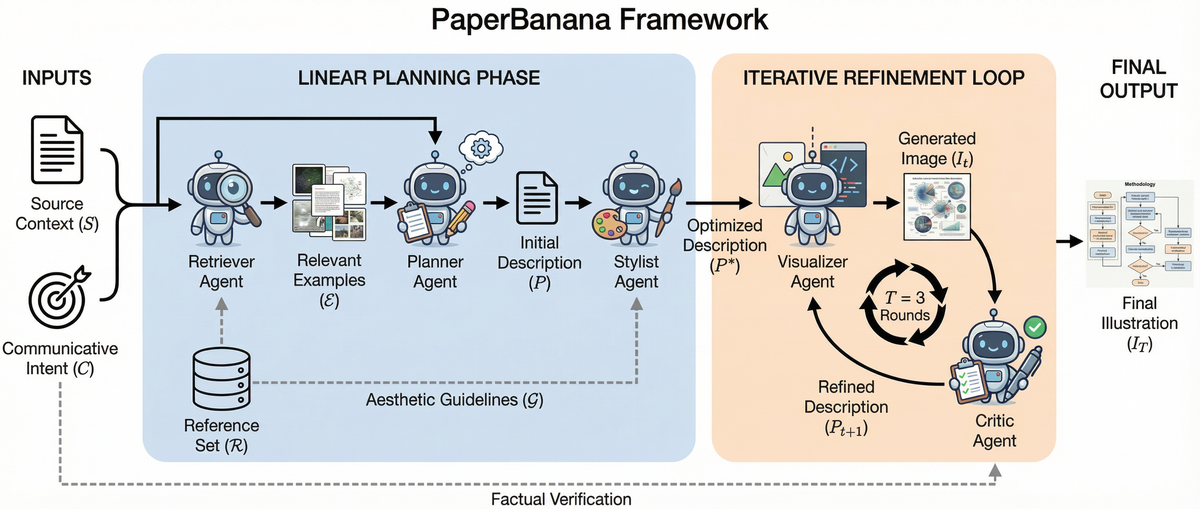
Figure 2 解读: 该框架图展示了 PaperBanana 的完整工作流程。左侧输入为 Source Context (方法论文本)和 Communicative Intent (图片说明)。Linear Planning Phase 包含三个 Agent 的线性流水线:Retriever Agent 从参考集 中选择相关示例 ,Planner Agent 生成初始描述 ,Stylist Agent 利用自动合成的 Aesthetic Guidelines 将 精炼为风格优化版本 。右侧的 Iterative Refinement Loop 由 Visualizer Agent 和 Critic Agent 组成闭环:Visualizer 将描述渲染为图像 ,Critic 通过事实验证生成修正描述 ,循环 轮后输出最终插图 。
3.2 任务形式化
将自动化学术插图生成形式化为从源上下文和交流意图到视觉表示的映射。设 为源上下文(方法论描述), 为交流意图(图片说明),目标是生成图像 :
可选地引入 个参考示例 ,其中 ,统一任务形式化为:
当 时退化为 zero-shot 生成。
3.3 各关键组件详解
(1) Retriever Agent — 参考检索
Retriever Agent 从固定参考集 中识别 个最相关的示例 ,为下游 Agent 提供结构和风格参考。采用生成式检索方法,让 VLM 在候选元数据上进行推理选择:
VLM 被指示同时匹配研究领域(如 Agent & Reasoning)和图表类型(如 pipeline、architecture),且视觉结构相似性优先于主题相似性。
(2) Planner Agent — 内容规划
Planner Agent 是系统的认知核心,接收 、 和检索到的示例 ,通过 in-context learning 将非结构化文本翻译为目标插图的详细文本描述 :
对于 diagram 任务,prompt 强调语义清晰性、纯白/浅色背景等规范;对于 plot 任务,要求精确的变量映射和每个数据点的坐标。
(3) Stylist Agent — 风格优化
Stylist Agent 自动遍历整个参考集合 ,合成涵盖以下维度的 Aesthetic Guideline :
- Color Palette: 背景使用 10-15% 不透明度的低饱和柔色调
- Shapes & Containers: 圆角矩形(5-10px)用于处理节点、3D 长方体用于张量
- Lines & Arrows: 正交连接线用于网络架构、贝塞尔曲线用于系统逻辑
- Typography & Icons: 无衬线字体用于标签,衬线/斜体用于数学变量
- Domain-Specific: Agent/LLM 论文用叙事式 UI 风格,CV 用空间几何风格
Stylist 将初始描述 精炼为风格优化版本 :
(4) Visualizer Agent — 视觉渲染
Visualizer Agent 将风格优化后的描述 转化为视觉输出。对于方法论示意图,使用图像生成模型直接渲染;对于统计图表,生成可执行的 Python Matplotlib 代码以确保数值精度:
- Diagram 模式:
- Plot 模式: (生成并执行 Matplotlib 代码)
初始描述 。
(5) Critic Agent — 迭代精炼
Critic Agent 与 Visualizer 形成闭环精炼机制。在每次迭代 ,Critic 检查生成图像 与原始源上下文 的一致性,识别事实偏差、视觉瑕疵并生成修正描述:
Visualizer-Critic 循环迭代 轮,最终输出 。
3.4 伪代码
Algorithm: PaperBanana Full Pipeline
# PaperBanana pipeline
examples = generative_retrieval(source_context, communicative_intent, reference_set, top_k=10)
plan = planner_agent(source_context, communicative_intent, examples)
current_description = style_guided_refinement(plan, style_guide_path)
for round_idx in range(max_rounds):
image = dual_mode_visualization(current_description, task_type, model_config)
if round_idx == max_rounds - 1:
return image
feedback = critic_feedback_loop(image, source_context, communicative_intent, current_description)
if feedback["done"]:
return image
current_description = feedback["revised_description"]
return imageAlgorithm: Retriever Agent — 生成式参考检索
def generative_retrieval(source_context, intent, candidate_pool, top_k=10):
candidates_meta = [(item.source_context, item.intent) for item in candidate_pool]
prompt = build_retrieval_prompt(source_context, intent, candidates_meta)
response = vlm.generate(prompt, system=RETRIEVER_SYSTEM_PROMPT)
selected_ids = parse_json(response)["selected_candidates"]
return [candidate_pool[idx] for idx in selected_ids[:top_k]]Algorithm: Critic Agent — 闭环反馈
def critic_feedback_loop(image, source_context, intent, current_description):
content = [encode_image(image), source_context, intent, current_description]
critique = parse_json(vlm.generate(content, system=CRITIC_SYSTEM_PROMPT))
if not critique["suggestions"]:
return {"done": True, "revised_description": current_description}
return {"done": False, "revised_description": critique["revised_description"]}Algorithm: Visualizer Agent — 双模式视觉渲染
def dual_mode_visualization(description, task_type, model_config):
if task_type == "plot":
code_prompt = build_plot_prompt(description)
code_response = vlm.generate(code_prompt)
python_code = extract_code_block(code_response)
with ProcessPoolExecutor(max_workers=4) as executor:
image = executor.submit(_execute_plot_code_worker, python_code).result()
else:
if "openai" in model_config.name:
image = openai_client.images.generate(prompt=description)
elif "gemini" in model_config.name:
image = gemini_model.generate_content(description)
else:
image = openrouter_client.generate(prompt=description)
return encode_as_base64_jpeg(image)Algorithm: Stylist Agent — 自动风格合成
def style_guided_refinement(initial_description, style_guide_path):
style_guide = load_markdown(style_guide_path)
prompt = build_style_prompt(initial_description, style_guide)
return vlm.generate(prompt, system=STYLIST_SYSTEM_PROMPT)3.5 代码-论文映射表
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| 整体 Pipeline 编排 | utils/paperviz_processor.py | PaperVizProcessor |
| Agent 基类 | agents/base_agent.py | BaseAgent (abstract process()) |
| Retriever Agent | agents/retriever_agent.py | RetrieverAgent — 支持 none/manual/random/auto 四种检索策略 |
| Planner Agent | agents/planner_agent.py | PlannerAgent — 多模态 prompt + base64 参考图像 |
| Stylist Agent | agents/stylist_agent.py | StylistAgent — 加载 Markdown 风格指南 |
| Visualizer Agent | agents/visualizer_agent.py | VisualizerAgent — 支持 OpenAI/OpenRouter/Gemini 多后端 |
| Critic Agent | agents/critic_agent.py | CriticAgent — 多模态批评 + JSON 结构化反馈 |
| Critic 迭代循环 | utils/paperviz_processor.py | _run_critic_iterations() — 最多 T 轮,维护 best_image 回退 |
| Plot 代码执行 | agents/visualizer_agent.py | _execute_plot_code_worker() — ProcessPoolExecutor 隔离执行 |
| 风格指南 | style_guides/neurips2025_diagram_style_guide.md | 覆盖 Color、Shape、Line、Typography、Layout 五大维度 |
| 主入口 | main.py | 异步批处理,最大并发 10,每 10 条自动 checkpoint |
4. Experimental Setup (实验设置)
数据集
- PaperBananaBench(方法论示意图): 从 NeurIPS 2025 的 5,275 篇论文中随机抽样 2,000 篇,经 MinerU 解析、过滤(宽高比 1.5-2.5)、人工审核后得到 584 个有效样本,随机分为测试集()和参考集()
- 四个类别: Agent & Reasoning (31.5%), Vision & Perception (25.0%), Generative & Learning (25.0%), Science & Application (18.5%)
- 平均源上下文长度 3,020.1 词,图片说明 70.4 词
- 统计图表测试集: 从 ChartMimic 数据集中筛选,240 个测试样本 + 240 个参考样本,覆盖 7 种图表类型(bar、line、tree & pie、scatter、heatmap、radar、miscellaneous)和两个复杂度级别
Baseline 方法
- Vanilla: 直接用图像生成模型从上下文和说明生成图表
- Few-shot: 在 Vanilla 基础上增加 10 个 few-shot 示例
- Paper2Any (Liu et al., 2025): 一种 agentic 框架,生成论文高层概念图
评估指标
采用 VLM-as-a-Judge 的参考比较方法,四个评估维度:
- Faithfulness (忠实性): 与源方法论描述和图片说明的一致性
- Conciseness (简洁性): 聚焦核心信息,避免视觉杂乱
- Readability (可读性): 布局清晰、文本易读、无过多交叉线
- Aesthetics (美观性): 符合学术出版的风格规范
评分采用分层聚合策略: Faithfulness 和 Readability 为主要维度,Conciseness 和 Aesthetics 为次要维度,主要维度优先决定整体得分。每个维度评分: Model wins = 100, Human wins = 0, Tie = 50。
训练配置
- VLM Backbone: Gemini-3-Pro(默认)
- Image Generation Model: Nano-Banana-Pro / GPT-Image-1.5
- VLM Judge: Gemini-3-Pro
- Critic 迭代轮数:
- 检索参考数量: Top-10
- 批处理并发数: 最大 10
5. Experimental Results (实验结果)
主要结果 (Table 1 — PaperBananaBench)
| Method | Faithfulness ↑ | Conciseness ↑ | Readability ↑ | Aesthetic ↑ | Overall ↑ |
|---|---|---|---|---|---|
| GPT-Image-1.5 (Vanilla) | 4.5 | 37.5 | 30.0 | 37.0 | 11.5 |
| Nano-Banana-Pro (Vanilla) | 43.0 | 43.5 | 38.5 | 65.5 | 43.2 |
| Few-shot Nano-Banana-Pro | 41.6 | 49.6 | 37.6 | 60.5 | 41.8 |
| Paper2Any (w/ Nano-Banana-Pro) | 6.5 | 44.0 | 20.5 | 40.0 | 8.5 |
| PaperBanana (w/ GPT-Image-1.5) | 16.0 | 65.0 | 33.0 | 56.0 | 19.0 |
| PaperBanana (w/ Nano-Banana-Pro) | 45.8 | 80.7 | 51.4 | 72.1 | 60.2 |
| Human | 50.0 | 50.0 | 50.0 | 50.0 | 50.0 |
关键发现:
- PaperBanana (Nano-Banana-Pro) 在所有维度显著超越 Vanilla baseline: Faithfulness +2.8%, Conciseness +37.2%, Readability +12.9%, Aesthetics +6.6%, Overall +17.0%
- 盲评人工评估: PaperBanana 获得 72.7% 胜率 / 20.7% 平局 / 6.6% 败率
- 分类别表现: Agent & Reasoning 最高 (69.9%), Scientific & Application (58.8%), Generative & Learning (57.0%), Vision & Perception 最低 (52.1%)
Ablation Study (Table 2)
| # | Retriever | Planner | Stylist | Visualizer | Critic | Faithfulness | Conciseness | Readability | Aesthetic | Overall |
|---|---|---|---|---|---|---|---|---|---|---|
| ① (Full) | ✓ | ✓ | ✓ | ✓ | 3 iters | 45.8 | 80.7 | 51.4 | 72.1 | 60.2 |
| ② | ✓ | ✓ | ✓ | ✓ | 1 iter | 38.3 | 75.2 | 50.6 | 68.9 | 51.8 |
| ③ (no Critic) | ✓ | ✓ | ✓ | ✓ | - | 30.7 | 79.2 | 47.0 | 72.1 | 45.6 |
| ④ (no Stylist) | ✓ | ✓ | - | ✓ | - | 39.2 | 61.7 | 47.9 | 67.4 | 49.2 |
| ⑤ (Random Ret.) | ○ | ✓ | - | ✓ | - | 37.3 | 62.7 | 51.1 | 65.6 | 48.3 |
| ⑥ (no Retriever) | - | ✓ | - | ✓ | - | 41.9 | 58.6 | 43.1 | 62.9 | 44.2 |
Ablation 关键发现:
- Stylist 的双面效应: 对比 ③ vs ④,Stylist 大幅提升 Conciseness (+17.5%) 和 Aesthetics (+4.7%),但降低 Faithfulness (-8.5%),因为风格优化有时会省略技术细节
- Critic 恢复忠实性: 对比 ① vs ③,Critic Agent 显著恢复了 Stylist 导致的 Faithfulness 下降(+15.1%),同时保持其他维度
- 检索的重要性: 无 Retriever (⑥) 在 Conciseness 和 Aesthetics 上显著下降,因为 Planner 缺乏学术图表美学参考而生成冗长描述
- Random vs Semantic 检索: 随机检索 (⑤) 与语义检索 (④) 性能相当,说明提供一般性结构/风格模式比精确内容匹配更重要
统计图表生成
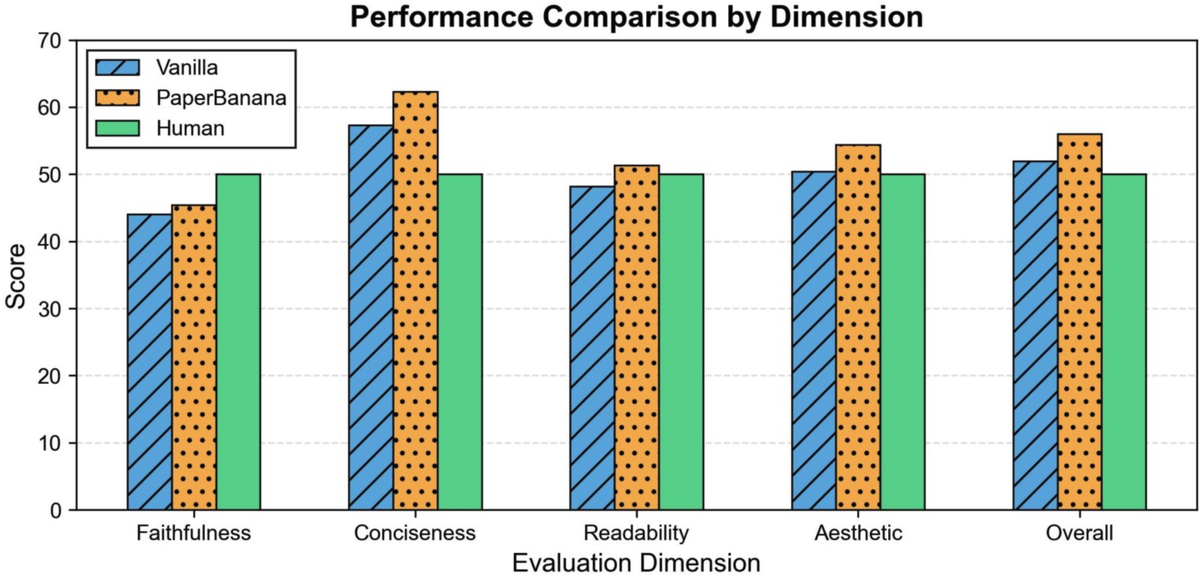
Figure 4 解读: 左图对比了 Vanilla Gemini-3-Pro 与 PaperBanana 在统计图表生成上的表现。PaperBanana 在所有四个维度均超越 baseline,整体提升 +4.1%。值得注意的是,PaperBanana 在 Conciseness、Readability 和 Aesthetics 上略超人类水平。
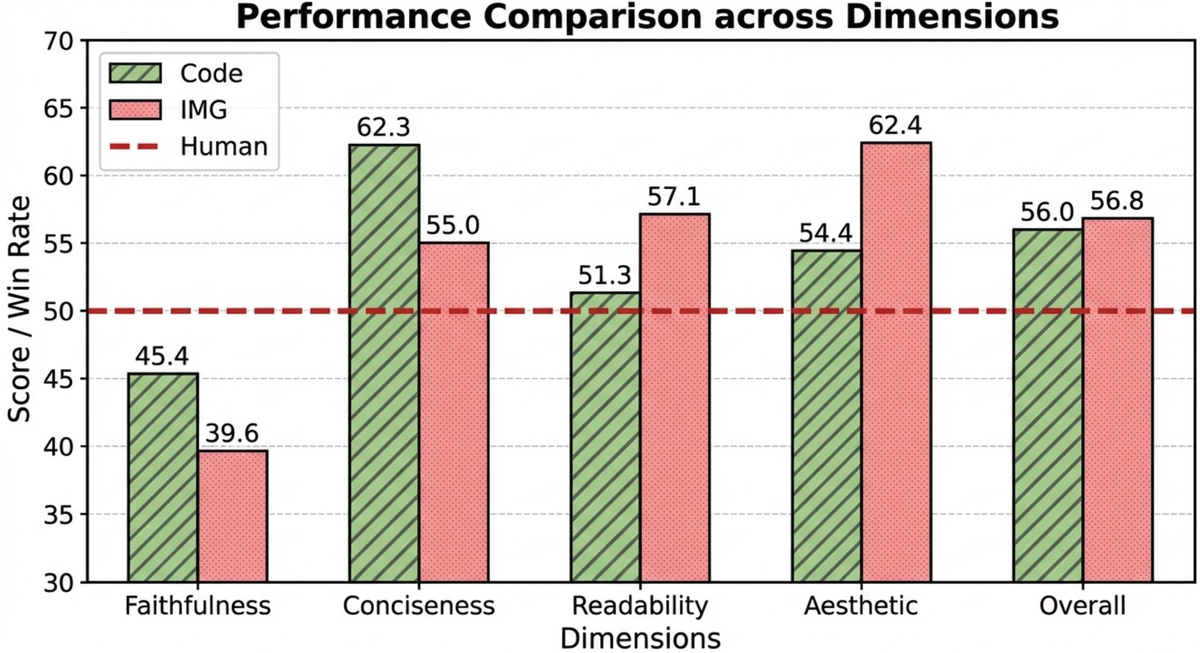
Figure 5 解读: 右图比较了代码生成(Matplotlib)与图像直接生成两种方式。代码方式在 Faithfulness (55.0 vs 39.6) 和 Conciseness (62.3 vs 45.4) 上显著优于图像生成,但图像生成在 Readability (57.1 vs 51.3) 和 Aesthetics (56.0 vs 54.4) 上略有优势。这揭示了数据忠实度与视觉吸引力之间的权衡。
增强人类手绘图表
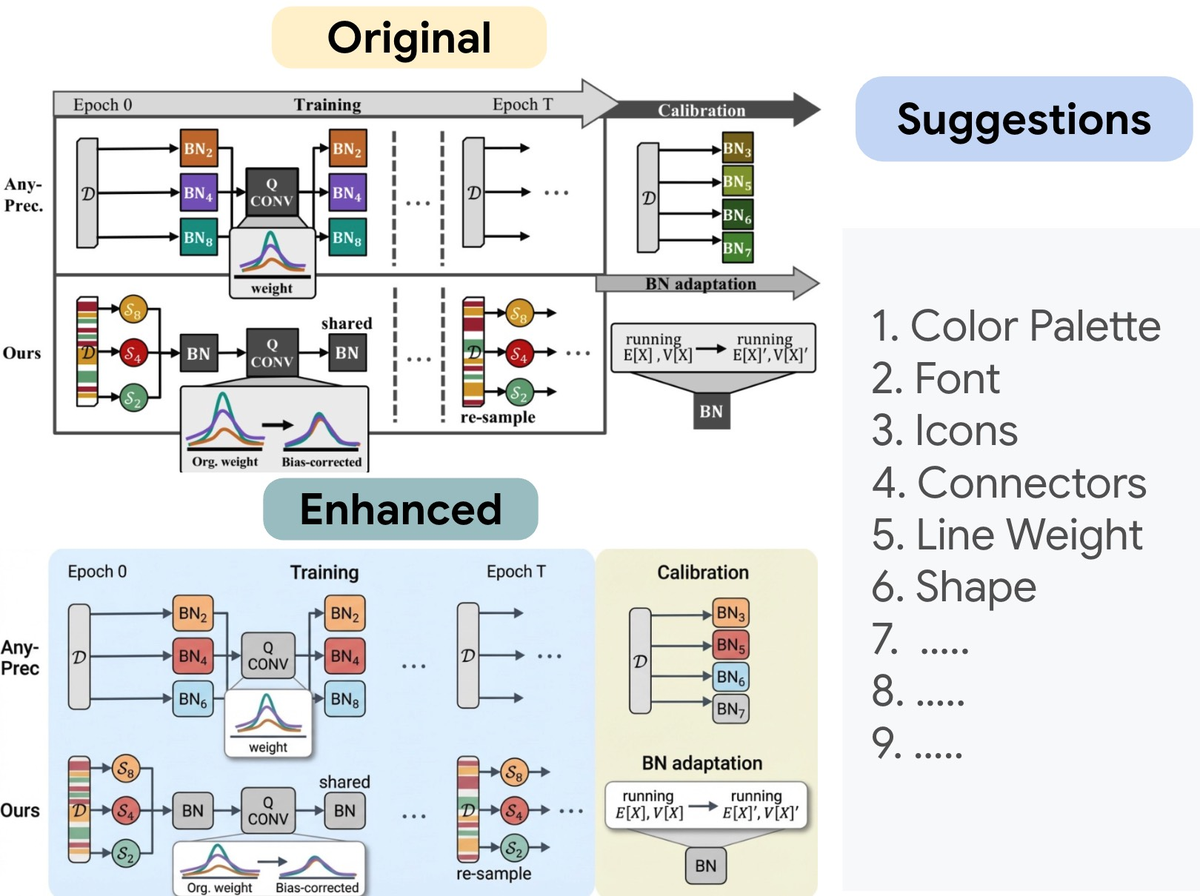
Figure 6 解读: 展示了利用 PaperBanana 的 Aesthetic Guidelines 增强人类手绘图表的能力。原始图表(上方)经过 Gemini-3-Pro 提出 10 个美学建议(右侧:Color Palette、Font、Icons、Connectors 等),再由 Nano-Banana-Pro 执行优化,生成增强版(下方)。在 292 个测试样本上,增强图表在美学维度获得 56.2% 胜率 / 6.8% 平局 / 37.0% 败率。
局限性
- 可编辑性不足: 输出为光栅图像,不如矢量图形易于编辑和缩放
- 风格标准化 vs 多样性权衡: 统一风格指南不可避免地降低了输出的风格多样性
- 细粒度忠实性差距: 当前 VLM 难以检测连接线对齐错误、节点连接错误等细微问题,导致 Critic 自我修正能力受限