OpenSeeker: Democratizing Frontier Search Agents by Fully Open-Sourcing Training Data
Paper: arXiv:2603.15594 Code: rui-ye/OpenSeeker Code reference:
main@61f682f9(2026-05-12)
1. Motivation(研究动机)
当前 deep search agent 的核心瓶颈不是单个 LLM 是否会调用搜索,而是高质量训练数据被少数工业团队掌握:复杂 QA、长链路工具轨迹、真实网页噪声下的决策过程通常不公开。已有开源 search agent 要么只开模型不开放完整训练数据,要么依赖较低难度/模拟环境样本,导致学术社区很难复现 frontier-level 的网页搜索能力。
OpenSeeker 要解决的具体问题是:如何从开放网页构造足够困难、可验证、可规模化的多跳搜索 QA,并合成能够训练 30B 级 ReAct search agent 的高质量工具轨迹。这个问题值得做,因为一旦数据 recipe 和模型权重同时开放,研究者就能在同一数据/轨迹基础上研究 SFT、RL、工具设计、检索环境和评测,而不是只比较闭源系统的最终分数。
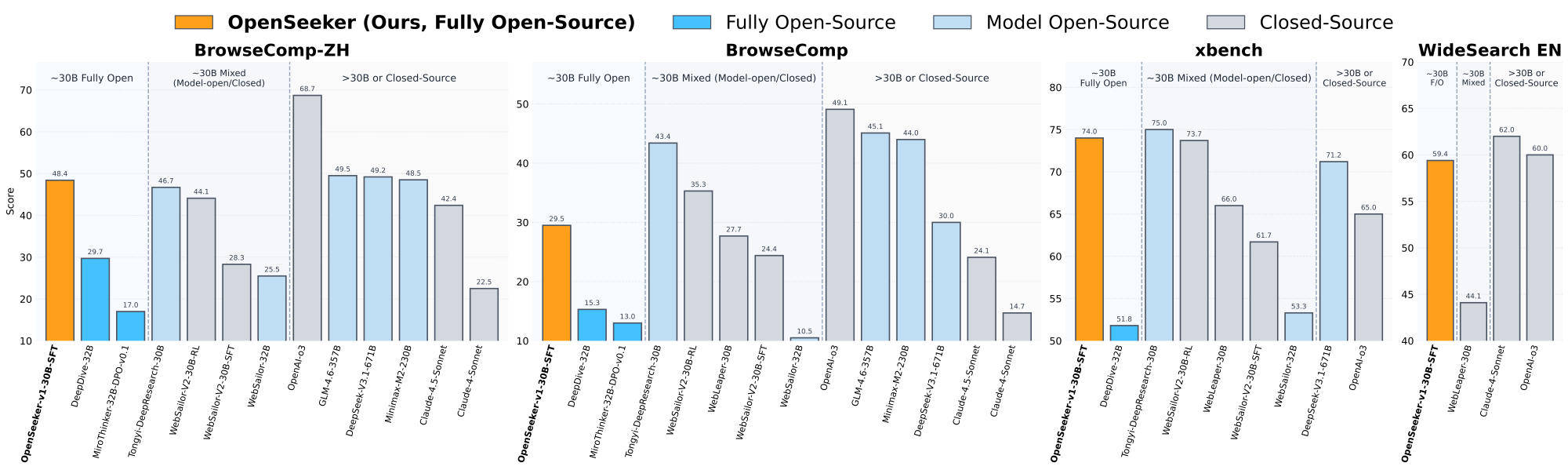
Figure 1 解读:teaser 把 OpenSeeker-v1-30B-SFT 放在四个搜索 benchmark 上和闭源/半开源系统对比。橙色柱显示它在 BrowseComp-ZH、BrowseComp、xbench、WideSearch EN 上都进入 frontier 区间;关键不是绝对超过 GPT-5-High 或 o3,而是用 11.7k 全开源数据和简单 SFT 达到接近工业系统的搜索能力。
2. Idea(核心思想)
核心洞察是:训练 search agent 的数据质量可以通过“先固定真实网页图中的推理路径,再反向生成必须沿该路径搜索的问题”来控制,而不是让 LLM 自由编题。OpenSeeker 把网页视为有向图,用 topological expansion 找到事实相关的局部子图,再通过 entity obfuscation 把显式实体改写成模糊描述,使问题必须经过多步检索和消歧。
第二个洞察是 trajectory synthesis 不能直接把长网页原文塞给 teacher。作者用 retrospective summarization 让 teacher 在生成下一步行动时看到“摘要化长历史 + 上一步原始观测”,从而减少噪声;但最终训练 student 时又恢复为 raw tool response,让模型学会在真实推理时自己完成 denoising。
与 WebSailor/WebLeaper 这类主要依赖公司合成数据的 SFT agent 相比,OpenSeeker 的差异是完整公开 11.7k QA+trajectory 数据;与 Tongyi DeepResearch 这类 CPT+SFT+RL 管线相比,它只用 SFT 单次训练运行,试图证明高难度数据本身可以替代相当一部分复杂训练流程。
3. Method(方法)
3.1 总体框架
论文目标是合成数据集 : 是复杂问题, 是标准答案, 是最优工具使用轨迹。网页被建模为有向图 ,搜索轨迹写作 ,其中 是搜索/访问动作, 是工具观测。难点有两个:问题必须足够难,迫使模型产生长链路 Reasoning -> Tool Call -> Tool Response;轨迹必须足够干净,不能只是 teacher 随机采样碰巧成功。
OpenSeeker 因此分成两个生成器:Fact-grounded scalable controllable QA synthesis 负责从网页图中生成高难度 QA;Denoised trajectory synthesis 负责让 teacher 在低噪声上下文中生成专家行动,再把 student 训练在真实 raw context 上。
3.2 Fact-grounded scalable controllable QA synthesis

Figure 2 解读:左侧 QA Generation 从 Web Corpus 选择 seed page,扩展到局部网页子图,抽取实体关系,生成必须跨实体推理的初始问题;随后 Entity Obfuscation 和 Question Obfuscation 把直接可搜的实体名变成模糊描述。右侧 QA Verifier 用 difficulty check 和 solvability check 做拒绝采样:既不能被 closed-book base model 直接答对,又必须在 oracle entity subgraph 给定时可以推出答案。
具体流程如下。
- Graph Expansion:采样 ,沿 outgoing edges 收集 个相关页面,得到 。这一步把网页链接结构变成候选推理路径。
- Entity Extraction / Question Generation:围绕 seed 的主题 抽取跨页面关键实体,组成 Entity Subgraph ;生成器 条件化在该子图上产生初始问题 ,并要求答案必须沿多条边推导得到。
- Entity / Question Obfuscation:用 将实体 映射为模糊描述 ,得到 fuzzy entity subgraph ;再把 改写成最终问题 ,答案仍为 。
- Dual-criteria verification:difficulty 条件为 ,防止问题只靠参数记忆;solvability 条件为 ,确保问题在给定事实子图时逻辑可解。
作者强调这个设计的三个收益:factual grounding 降低幻觉,scalability 来自网页图可持续扩展,本工作用约 68GB 英文和 9GB 中文网页数据验证;controllability 来自子图大小 等结构参数,可以控制 reasoning complexity 和 coverage。
def synthesize_grounded_qa(web_graph, seed_sampler, entity_extractor, generator, base_model, k):
"""Paper-level pseudocode for OpenSeeker QA synthesis."""
while True:
seed = seed_sampler(web_graph.nodes)
subgraph = web_graph.expand_outgoing(seed, k=k)
theme = entity_extractor.central_theme(seed)
entity_graph = entity_extractor.build_entity_subgraph(subgraph, theme)
q_init = generator.write_question(entity_graph, answer=theme)
fuzzy_graph = entity_graph.map_entities(lambda e: obfuscate_entity(e))
question = generator.rewrite_with_obfuscated_entities(q_init, fuzzy_graph)
answer = theme
difficult = base_model.answer(question, tools=None) != answer
solvable = base_model.answer(question, context=entity_graph) == answer
if difficult and solvable:
return {"query": question, "answer": answer, "entity_graph": entity_graph}3.3 Denoised trajectory synthesis
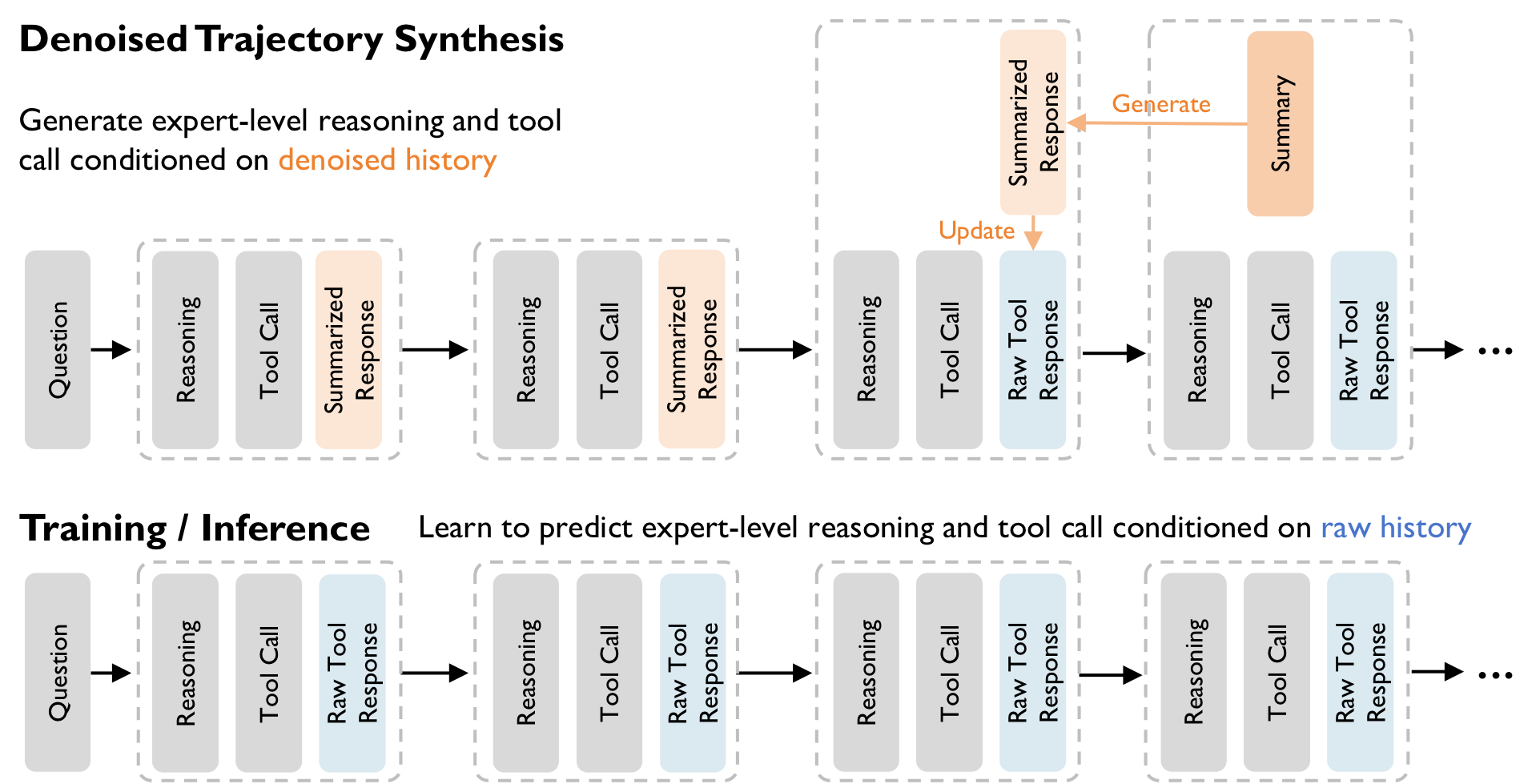
Figure 3 解读:上半部分是 synthesis/teacher 视角:teacher 生成下一步 reasoning/tool call 时看到 denoised history,即历史 raw response 已被 summary 替换,但最近一步 raw response 仍完整保留。下半部分是 training/inference/student 视角:student 只看到 raw history,却被监督去预测 teacher 的高质量 reasoning 和 tool call,因此训练信号逼迫模型在噪声网页中学会筛选信息。
搜索轨迹定义为 。在第 步,teacher 的上下文为:
其中 。完成第 步并获得 后,系统把上一轮 压缩成 ,在下一步进入 long-term history。最终 student 训练上下文恢复为:
直觉上,这相当于“teacher 用干净黑板写出解题轨迹,student 在脏黑板上学习同一个下一步动作”。如果 teacher 也直接读 raw full history,长网页噪声会污染下一步工具选择;如果 student 只学 summary history,部署时又无法处理真实工具返回。
def synthesize_denoised_trajectory(question, answer, teacher, summarizer, tools, max_turns=200):
"""Paper-level pseudocode for dynamic context denoising."""
raw_steps, summary_steps = [], []
for t in range(1, max_turns + 1):
recent_raw = raw_steps[-1:] # keep full previous observation
long_term = summary_steps[:-1] if summary_steps else []
teacher_context = build_context(question, long_term, recent_raw)
reasoning, action = teacher.next_action(teacher_context)
observation = tools.execute(action)
raw_steps.append((reasoning, action, observation))
if len(raw_steps) >= 2:
prev_r, prev_a, prev_o = raw_steps[-2]
prev_summary = summarizer(prev_o, context=teacher_context)
summary_steps.append((prev_r, prev_a, prev_summary))
if teacher.has_final_answer(reasoning, observation, answer):
break
train_examples = []
for t, (reasoning, action, _) in enumerate(raw_steps):
noisy_context = build_context(question, raw_steps[:t])
train_examples.append((noisy_context, reasoning, action))
return train_examples3.4 Released code 映射与适用边界
论文公式与 released code 实现差异:未发现公式级实现与论文描述直接冲突;但 main@61f682f9 发布仓库主要是 v1/v2 模型部署、工具调用推理和评测脚本,没有包含 §3 的 graph-grounded QA synthesis、teacher denoised trajectory synthesis 或 SFT 训练脚本。因此上面的数据/轨迹生成 pseudocode 是基于论文方法;下面的 source-based pseudocode 只锚定 released runtime。
Code reference:
main@61f682f9(2026-05-12) — pseudocode and mapping based on this commit
| Paper concept | Released source anchor | 备注 |
|---|---|---|
| v1 search agent deployment | run_openseeker.sh | SGLang server;默认 MODEL_PATH="path/to/OpenSeeker-v1-30B-SFT"、GPU_IDS="0,1,2,3"、NUM_GPUS=4、CONTEXT_LENGTH=256000、MAX_RUNNING_REQUESTS=2000。这是部署配置,不是训练配置。 |
| Tool-use inference loop | src/llm_tool_openseeker.py::call_llm_with_tool | 读取 OPENSEEKER_BASE_URL/OPENSEEKER_MODEL,渲染 chat template,调用 OpenAI-compatible /v1/completions streaming,循环解析 <tool_call> / <answer>。 |
| Tool parser and recovery | src/llm_tool_openseeker.py::_parse_tool_calls_from_text | 从 <tool_calls> 或全文中抽取 JSON;对 incomplete JSON 做修复;失败时把 parse error 作为 tool message 追加回上下文。 |
| Search/visit tools | src/tools/search.py, src/tools/visit.py | Search 支持 Serper/Tavily 批量 query;Visit 通过 Jina 读取网页,再调用 summary API 抽取与 goal 相关的信息。 |
| Batch answer generation | eval/generate_answer.py | 默认 --max_tokens 32768、--tool_count_max 200、--max_worker 60,异步并发处理样本并保存 full_traj/trace/tool metrics。README quick-start 写作 --max_workers,而源码 parser 是 --max_worker。 |
| LLM-as-judge evaluation | eval/eval.py | 对每条 final_response 调 scorer API,解析 0/1 label,并统计 tool_calls。 |
| Paper training data synthesis | 未在 released repo 中发现训练/合成源码 | repo 文件名搜索未发现 train、sft、synthesis、trajectory、dataset、denois 等模块;论文声称数据和模型开放,代码仓库不等同于完整训练 pipeline。 |
import torch
@torch.inference_mode()
def solve_query_with_tools_source_based(item, args, llm_client, search_tool, visit_tool):
"""Python/PyTorch-style pseudocode reflecting src/llm_tool_openseeker.py."""
messages = [
{"role": "system", "content": DEVELOPER_PROMPT},
{"role": "user", "content": item["query"]},
]
trace, tool_count = [], 0
max_tools = getattr(args, "tool_count_max", 200)
max_tokens = getattr(args, "max_tokens", 16384)
while tool_count < max_tools:
prompt = render_chat_template(messages, add_generation_prompt=True)
completion = llm_client.stream_completions(
prompt=prompt,
max_tokens=max_tokens,
skip_special_tokens=False,
)
reasoning, content = split_think_and_content(completion)
if contains_answer_tag(content):
return extract_answer(content), trace
clean_text, tool_calls, parse_error = parse_tool_calls_from_text(content)
messages.append({"role": "assistant", "content": completion})
trace.append({"type": "model_message", "reasoning": reasoning, "tool_calls": tool_calls})
if not tool_calls:
messages.append({"role": "tool", "name": "unknown", "content": parse_error})
continue
for call in tool_calls:
name, kwargs = call["function"]["name"], call["function"]["arguments"]
if name == "search":
output = search_tool.call(kwargs)
elif name in ("visit", "visit_summary"):
output = visit_tool.call(kwargs)
else:
output = "Unknown tool or call tool with incorrect format."
messages.append({"role": "tool", "name": name, "content": output})
trace.append({"type": "tool_response", "tool": name, "output": output})
tool_count += 1
if tool_count >= max_tools:
break
return "The max tool count has been reached.", trace4. Experimental Setup(实验设置)
数据与规模:论文用约 68GB 英文网页数据和约 9GB 中文网页数据验证合成流程,最终 OpenSeeker-v1-Data 规模为 11.7k SFT 样本,其中中文数据约 1.4k。每条训练样本包含用户问题 、raw reasoning steps、tool calls 和完整未压缩 tool responses。
模型与训练/推理配置:OpenSeeker 初始化自 Qwen3-30B-A3B-Thinking-2507,总参数 30B、推理激活约 3B。论文设置最大 tool call limit 为 200,context window 为 256k;由于资源限制,只做单次训练运行,没有 heuristic data filtering 或 training hyperparameter tuning。公开代码未提供训练 launch script、LR、batch size、training steps 或 GPU 训练配置;released 部署脚本默认 4 GPU SGLang 推理,CONTEXT_LENGTH=256000。
评测 benchmark:BrowseComp / BrowseComp-ZH 测多步网页导航与难信息定位,论文因资源限制在 BrowseComp subset 200 samples 上评测;xbench-DeepSearch 测复杂 deep research/planning/synthesis;WideSearch 报 English subset item F1,用于衡量跨大量来源的 broad information seeking 可靠性。
对比方法:闭源/工业系统包括 Claude 系列、OpenAI-o3、OpenAI Deep Research、GPT-5-High、Tongyi DeepResearch 等;大规模开源模型包括 Kimi-K2、DeepSeek-V3.1/V3.2、GLM-4.6/4.7、Minimax-M2、LongCat-Flash;30B 级直接可比 agent 包括 MiroThinker、DeepDive-32B、WebDancer、WebSailor/WebSailor-V2、WebLeaper。
5. Experimental Results(实验结果)
5.1 主结果
OpenSeeker-v1-30B-SFT 用 11.7k 全开源样本和 SFT 在四个 benchmark 上得到:BrowseComp 29.5、BrowseComp-ZH 48.4、xbench 74.0、WideSearch-EN 59.4。最重要的比较有两组:它在 BrowseComp-ZH 上超过 Tongyi DeepResearch 的 46.7,后者使用 CPT+SFT+RL;在同为 SFT 的 30B 级 agent 中,它在四项指标上均为最高。
| Model/Data | Samples | Training | BrowseComp | BC-ZH | xbench | WideSearch-EN |
|---|---|---|---|---|---|---|
| WebSailor-V2-30B | ? | SFT | 24.4 | 28.3 | 61.7 | - |
| WebLeaper-30B | 15k | SFT | 27.7 | - | 66.0 | 44.1 |
| Tongyi DeepResearch | ? | CPT+SFT+RL | 43.4 | 46.7 | 75.0 | - |
| OpenSeeker-v1-30B-SFT | 11.7k | SFT | 29.5 | 48.4 | 74.0 | 59.4 |
在可比数据量实验中,OpenSeeker-v1-Data-11.7k 对比 WebSailor/WebLeaper 10k–15k 数据组合:BrowseComp 29.50 高于最好 baseline 27.67;xbench 74.00 高于 66.00;WideSearch-EN 59.40 高于 44.07。这支持作者结论:在 search agent SFT 中,数据构造质量比单纯样本数更关键。
| Data | Samples | Developer | BrowseComp | xbench | WideSearch-EN |
|---|---|---|---|---|---|
| WebSailor-V2-10k | 10k | Tongyi | 24.50 | 62.67 | 38.91 |
| WebSailor-V2-5k + WebLeaper-Union-5k | 10k | Tongyi | 27.50 | 62.33 | 41.70 |
| WebSailor-V2-5k + WebLeaper-Reverse-Union-10k | 15k | Tongyi | 27.67 | 66.00 | 44.07 |
| OpenSeeker-v1-Data-11.7k | 11.7k | Academic | 29.50 | 74.00 | 59.40 |
5.2 数据难度分析
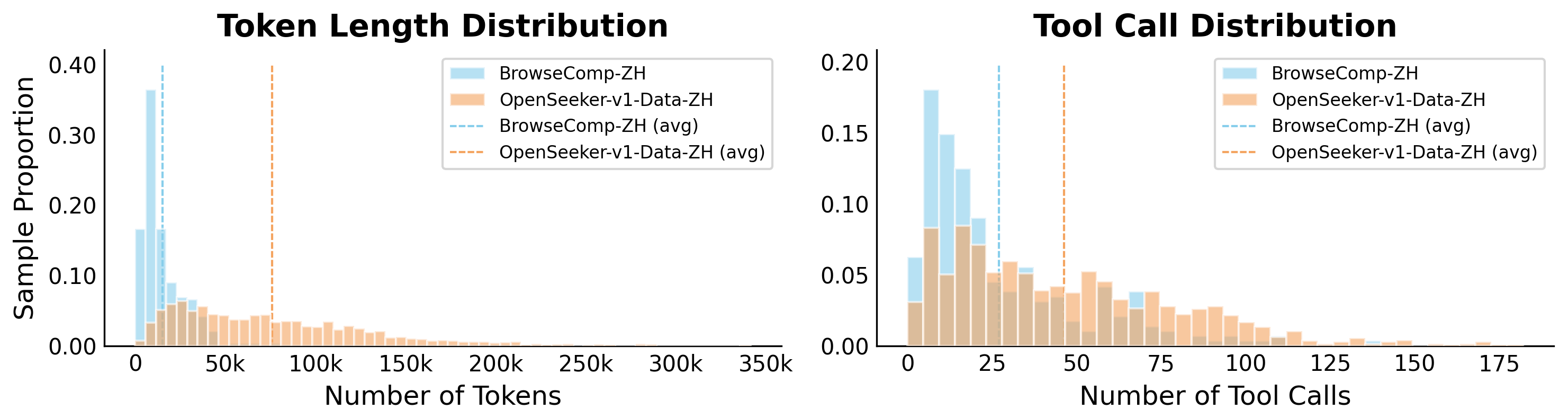
Figure 4 解读:在同一模型推理下,OpenSeeker-v1-Data-ZH 的平均工具调用数为 46.35、平均 token length 为 76.1k;BrowseComp-ZH 分别为 26.98 和 15.1k。也就是说,虽然中文数据只有约 1.4k,轨迹长度和工具使用强度明显更高,解释了为什么它能在 BrowseComp-ZH 上给 SFT 带来强增益。
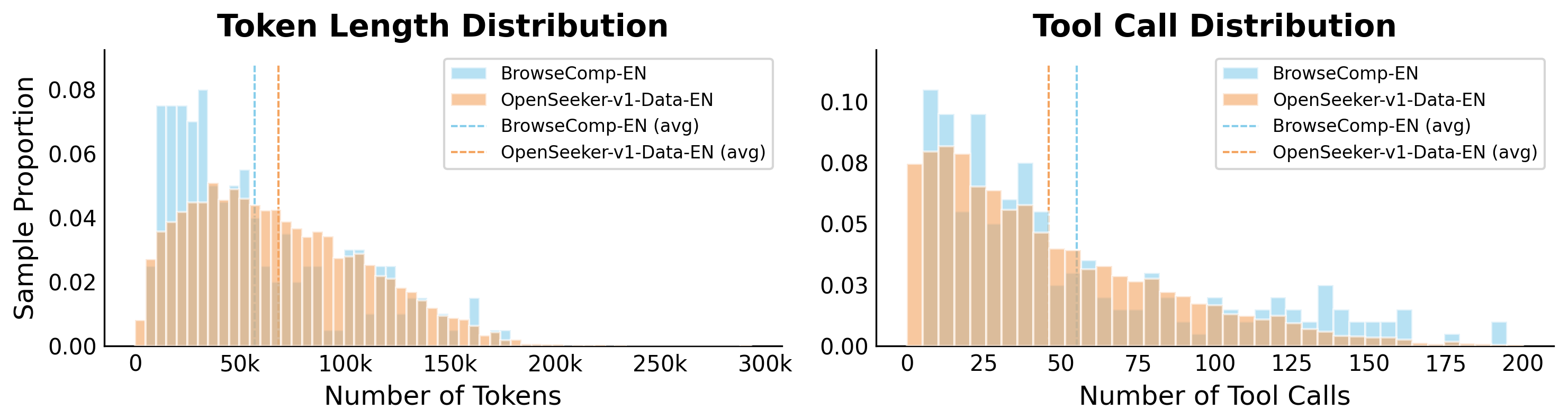
Figure 5 解读:英文数据与 BrowseComp-EN 的难度更接近,作者也承认 English data 尚未更新到最新 QA 标准,因此它不像中文数据那样显著超越 benchmark 难度。这是结果中的一个重要边界:OpenSeeker 的 pipeline 有效,但不同语言/数据版本的难度一致性仍需继续优化。
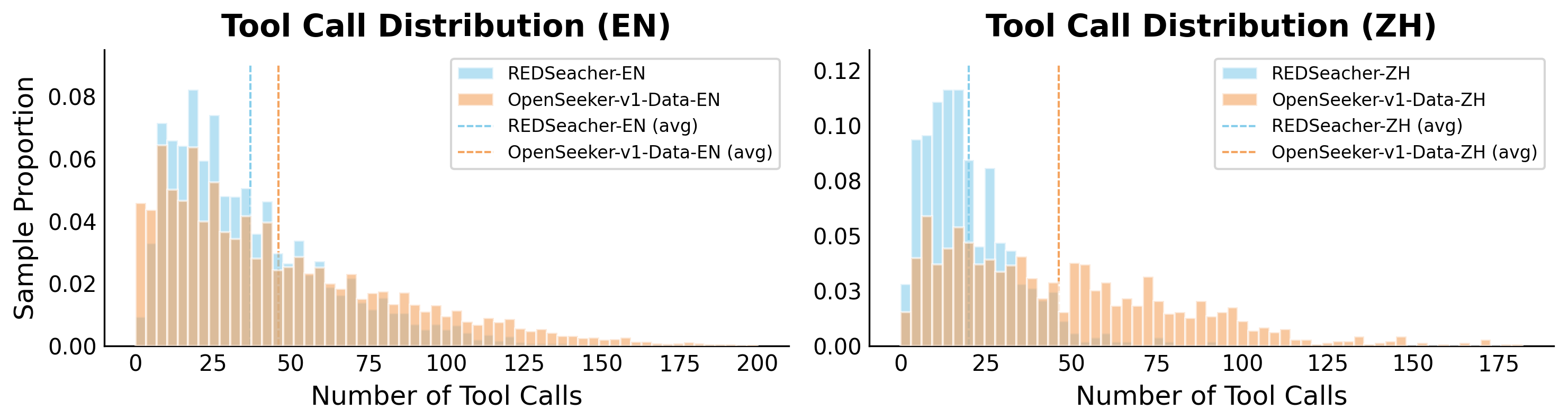
Figure 6 解读:与 REDSearcher 数据相比,OpenSeeker-v1-Data-EN 平均 45.92 次工具调用,高于 REDSearcher-EN 的 36.91;OpenSeeker-v1-Data-ZH 平均 46.35,高于 REDSearcher-ZH 的 20.02。结合并发工作表,OpenSeeker 在 BC-ZH 48.4 vs REDSearcher 26.8、xbench 74.0 也更强,说明它不是只增加轨迹长度,而是把更难的多跳搜索任务转化成可学习监督。
5.3 局限与结论
作者明确的局限主要来自资源约束:只训练一次,没有系统调参、数据过滤或更大规模验证;英文数据未更新到最新 QA 标准;未来还需要优化数据分布、增加质量过滤,并把 agent 从纯 web search 扩展到更丰富工具和数据源。我的判断是,这篇论文最有价值的部分不是“29.5/48.4/74.0/59.4”这些单点分数,而是把 search agent 的数据 moat 具体拆成了可复现的 QA synthesis 与 trajectory synthesis 两个模块,并公开了数据/模型,使后续工作可以在数据质量、RL 和工具环境上做可控 ablation。