OpenSearch-VL: An Open Recipe for Frontier Multimodal Search Agents
Paper: arXiv:2605.05185 Code: shawn0728/OpenSearch-VL Code reference:
main@23a80e7f(2026-05-13)
1. Motivation(研究动机)
现有多模态“deep search”代理通常有三类复现瓶颈:训练数据和轨迹合成闭源、工具环境只覆盖检索而不覆盖真实图像预处理、长链路 RL 中一次工具错误会污染整条 rollout。对于知识密集型视觉问答,模型不能只靠 VLM 内参或一次 RAG;它需要在图像局部、外部网页、OCR 文本之间多轮验证。
本文要解决的是:如何公开一套可复现的多模态搜索代理训练 recipe,使模型能主动裁剪/增强图像、调用文本/图像搜索、访问网页并在长 horizon 中稳定学习。这个问题值得做,因为它把 VLM 从“一次性回答器”推进到“可验证证据链”的 agentic 系统,尤其适合桥梁、标志、截图、文档等需要视觉定位 + 外部知识的任务。
2. Idea(核心思想)
核心洞察是:强搜索代理不只是更强的基座模型,而是“数据难度、工具覆盖、失败处理”三者同时闭环。OpenSearch-VL 用 Wikipedia 多跳路径和 source-anchor visual grounding 构造必须多步搜索的样本,用统一工具环境暴露视觉修复/检索/解析动作,再用 fatal-aware GRPO 保留工具失败前仍有价值的推理前缀。
与 Search-R1 式文本检索 RL 相比,OpenSearch-VL 的差异在于环境不只是 retriever,而是包含 crop、layout_parsing、super_resolution、perspective_correct、image_search 等多模态工具;与 Vision-DeepResearch 式 hard masking 相比,它不是丢弃整条 fatal rollout,而是在 fatal step 之后 mask token,并对 fatal trajectory 做 one-sided advantage clamp。
3. Method(方法)
3.1 总体框架
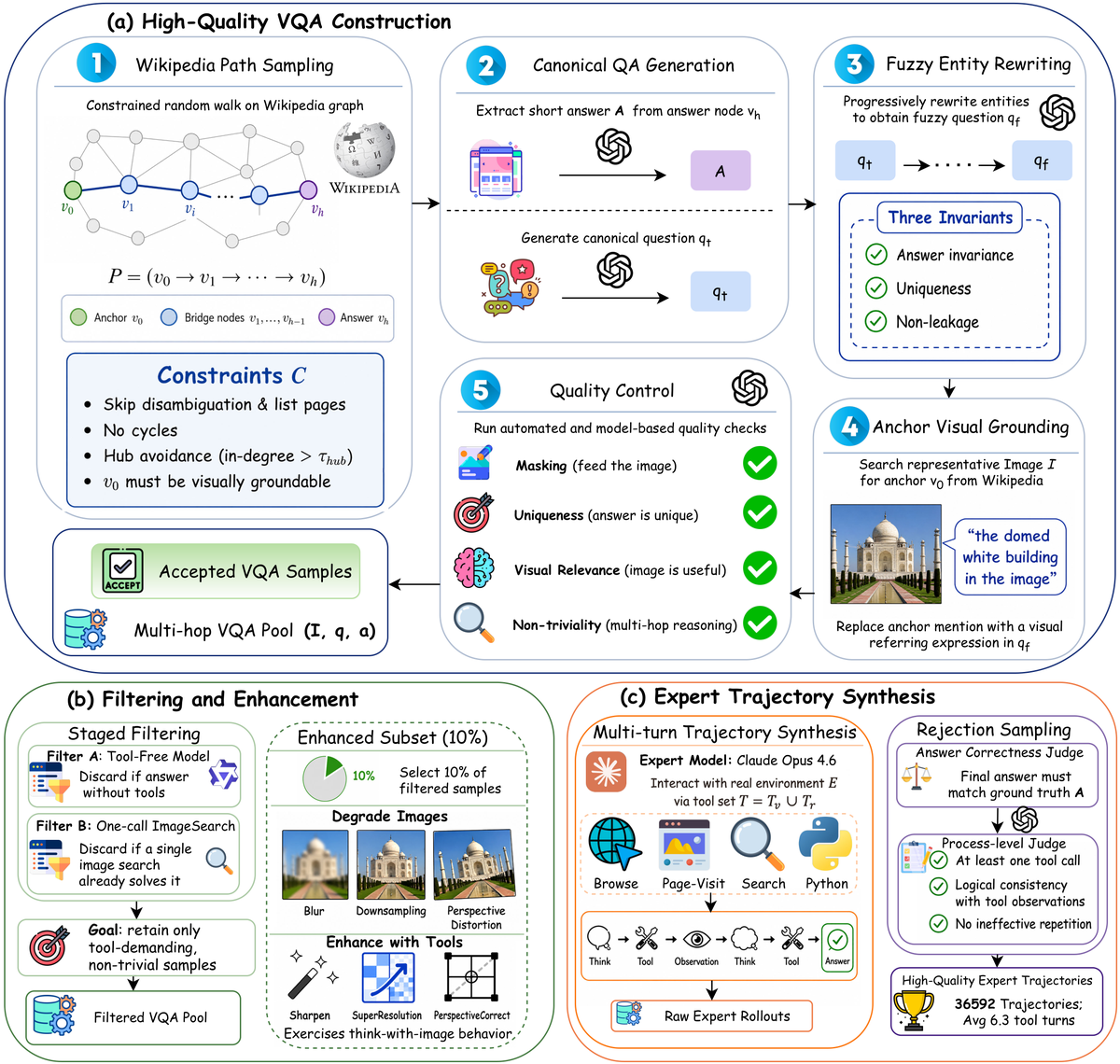
Figure 1 解读:数据管线先从 English Wikipedia hyperlink graph 采样 2/3/4-hop entity path,把起点作为视觉 anchor、末端作为 answer node;再通过 fuzzy entity rewriting 和 source-anchor visual grounding 让问题不能被一次图片搜索解决;随后用 tool-free model 与 one-call ImageSearch 两个过滤器剔除捷径样本,并把 10% 样本做退化后要求工具增强;最后由 Claude Opus 4.6 生成多轮 ReAct 专家轨迹,经答案正确性和 process-level judge 过滤,得到 36,592 条高质量 SFT trajectory,平均 6.3 个工具调用 turn。

Figure 2 解读:训练分两段:先用 SearchVL-SFT-36k 做 agentic SFT,让模型学会按 <think> / <tool_call> / <response> 格式调用工具;再在真实工具环境中对 SearchVL-RL-8k 采样多条 rollout,用格式、答案正确性、query utility 组合成 trajectory reward。fatal-aware GRPO 在 rollout 内检测连续错误,把 fatal step 之后的 token 从梯度中移除,同时保留可用前缀进入组归一化和策略更新。
3.2 关键组件
数据构造:Wikipedia 路径采样把文章视作有向图 ,从 seed 做长度 的 constrained random walk,并跳过 disambiguation/list page、cycle 和高入度 hub。路径中的 是视觉入口, 是被模糊改写的 bridge entity, 提供目标属性答案。这样设计会降低“直接搜索答案实体”的捷径概率。
工具环境:工具集覆盖 retrieval(text_search、image_search、web_search、visit)、image enhancement(sharpen、super_resolution、perspective_correct)、attention/parsing(crop、layout_parsing/OCR)和 computation(python_interpreter)。直觉上,视觉问题的瓶颈经常不是缺知识,而是图像局部太小、模糊、倾斜或文字混排;先把视觉 evidence 变成可检索/可读 evidence,后续搜索才可靠。
fatal-aware RL:为什么它有效:长链路 tool-use 的主要噪声来自错误级联。OpenSearch-VL 把连续 次 tool-execution error 的起点定义为 fatal step;fatal step 后的 token 不再参与梯度,而 fatal 前的 prefix 仍可基于部分 reward 学习。若 fatal trajectory 的组归一化 reward 低于均值,one-sided clamping 把 advantage 截到 0,避免惩罚有效前缀;若高于均值,则保留正梯度。

Figure 3 解读:训练曲线显示 fatal-aware GRPO 维持更长的平均工具调用 turn,同时 batch-level accuracy 高于 vanilla GRPO 和 hard mask。这个结果支持作者的直觉:productive exploration 需要保留失败前的可用步骤,而不是一遇到 fatal episode 就整条丢弃。

Figure 4 解读:clamping case 图展示了两类 rollout group:当 fatal prefix 本身高于 group mean 时,clamp 保留其正梯度;当 fatal rollout 被非 fatal 样本显著支配时,负 advantage 被截断为 0。它相当于在 hard mask 和 full training 之间做保守折中。
3.3 公式
轨迹由模型动作和环境观测交替组成,工具观测不计入生成概率:
SFT 阶段对每步动作 做自回归模仿:
RL 阶段的 composite reward 为:
fatal-aware token mask:
其中 是第一个 fatal step;无 fatal 时 。one-sided advantage clamping:
3.4 伪代码(基于公开代码)
# RL/rllm/vision_deepresearch_async_workflow/deepresearch_workflow.py
_CONSECUTIVE_ERROR_THRESHOLD = 3
def find_fatal_step_index(steps, termination):
if len(steps) == 0:
return 0, "no_steps"
consecutive_errors = 0
for idx, step in enumerate(steps):
if is_step_error(step):
consecutive_errors += 1
else:
consecutive_errors = 0
if consecutive_errors >= _CONSECUTIVE_ERROR_THRESHOLD:
fatal_start = idx - _CONSECUTIVE_ERROR_THRESHOLD + 1
return fatal_start, "consecutive_errors"
if termination == "answer":
return None, ""
return len(steps), termination or "no_final_answer"# RL/rllm/vision_deepresearch_async_workflow/deepresearch_workflow.py
async def score_deepresearch_rollout(steps, prediction, answer, termination):
fatal_step, reason = find_fatal_step_index(steps, termination)
is_fatal = fatal_step is not None
valid_prefix = steps[:fatal_step] if is_fatal and fatal_step < len(steps) else steps
r_format = mean([format_reward_for_step(s) for s in valid_prefix]) if valid_prefix else 0.0
r_accuracy = judge_final_answer(prediction, answer) # 0/1
r_query = await judge_query_utility(valid_prefix, prediction, answer)
total_reward = r_format * (0.8 * r_accuracy + 0.2 * r_query)
return total_reward, {"is_fatal": is_fatal, "fatal_step_index": fatal_step, "fatal_reason": reason}# RL/rllm/rllm/engine/agent_workflow_engine.py
import torch
def apply_fatal_step_mask(response_mask: torch.Tensor, fatal_step_index: int) -> torch.Tensor:
mask = response_mask.clone()
step = 0
prev_val = 0
for t in range(mask.numel()):
val = int(mask[t].item())
if val == 1 and prev_val == 0: # assistant-token block begins
if step >= fatal_step_index:
mask[t:] = 0 # remove post-fatal generated tokens
return mask
if val == 0 and prev_val == 1:
step += 1
prev_val = val
return mask# RL/rllm/rllm/trainer/verl/agent_workflow_trainer.py
def one_sided_clamp_for_fatal(batch):
if "is_fatal" not in batch.non_tensor_batch:
return batch
fatal_mask = batch.non_tensor_batch["is_fatal"].astype(bool)
for i in fatal_mask.nonzero()[0]:
batch.batch["advantages"][i].clamp_(min=0.0)
batch.batch["returns"][i].clamp_(min=0.0)
return batch# opensearch_vl/opensearch_infer/pipeline.py + tools.py
def agentic_inference_loop(runner, question, images, max_turns):
state = bootstrap_images(images)
messages = build_system_prompt_with_tools(question, state)
for _ in range(max_turns):
output = runner.generate(messages)
call = extract_tool_call(output)
if call is None or has_response_tag(output):
return extract_final_response(output)
observation = execute_tool(call.name, call.arguments, image_state=state)
messages.append(format_observation(observation))
return force_final_response(messages)3.5 Code mapping
Code reference:
main@23a80e7f(2026-05-13)
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| 公开 repo 总览与 artifact 状态 | README.md | Overview / TODO;说明 SFT、RL、inference 路径;data curation pipeline standalone toolkit 当前仍在 TODO |
| Agentic SFT 配置 | SFT/examples/agentic_full/qwen3_vl_full_sft_8b_ray.yaml, qwen3_vl_full_sft_30_3b_ray.yaml, qwen3_vl_full_sft_32b_ray.yaml | Qwen3-VL base model、7 个 agentic dataset、32k cutoff、256 workers、LR 2e-5、8 epochs |
| SFT 数据登记 | SFT/data/dataset_info.json | new_fvqa_agent_sft, palace_agent_sft, webqa_agent_sft, livevqa_agent_sft, wikiart_agent_sft, wiki_zh_agent_sft, wiki_en_agent_sft |
| 工具 schema 与调用解析 | opensearch_vl/opensearch_infer/tools.py | get_tools_definition, extract_tool_call, execute_tool |
| 搜索与 OCR/图像搜索 | opensearch_vl/opensearch_infer/search.py | text_search, image_search, layout_parsing |
| 推理 rollout | opensearch_vl/opensearch_infer/pipeline.py, runners.py | process_single_case, Qwen3VLRunner, ClaudeRunner |
| RL workflow 与 reward | RL/rllm/vision_deepresearch_async_workflow/deepresearch_workflow.py | _find_fatal_step_index, _judge_query_utility, DeepResearchWorkflow.run |
| post-fatal token mask | RL/rllm/rllm/engine/agent_workflow_engine.py | _apply_fatal_step_mask, execute_tasks_verl |
| one-sided advantage clamp | RL/rllm/rllm/trainer/verl/agent_workflow_trainer.py | fatal advantages / returns clamp_(min=0.0) |
| RL launch config | RL/rllm/vision_deepresearch_async_workflow/run/qwen3-vl-8b-multi-node.sh, qwen3-vl-30b-3b-multi-node.sh, qwen3-vl-32b-multi-node.sh | 8 nodes × 8 GPUs, 4k prompt, 70k response, RLOO/GRPO objective, actor LR 1e-6 |
4. Experimental Setup(实验设置)
训练数据:SearchVL-SFT-36k 是 36,592 条 expert trajectory,平均 6.3 个工具调用 turn;SearchVL-RL-8k 用于 agentic RL。SFT YAML 中实际登记了 7 个 tool-use 数据集:FVQA、Palace、WebQA、LiveVQA、WikiArt、中文 Wiki、英文 Wiki。论文的 data curation 独立 toolkit 在当前 repo TODO 中尚未发布,因此数据构造代码无法逐行映射。
模型与训练配置:基座为 Qwen3-VL-8B-Instruct、Qwen3-VL-30B-A3B-Instruct、Qwen3-VL-32B-Instruct。SFT:256 H20(32 nodes × 8 GPUs),full finetune,vision tower 和 projector 均不冻结,ZeRO-3,bf16,cutoff length 32,000 tokens,per-device batch 1,gradient accumulation 1,effective batch 256,LR ,cosine scheduler,warmup ratio 0.1,8 epochs,logging steps 5,save steps 400。RL:64 H20(8 nodes × 8 GPUs),约 200 optimization steps/10 days;train batch 256 prompts,max prompt 4,096 tokens,max response 70,000 tokens,SGLang async rollout,rollout TP 4,actor LR ,KL loss off,low-variance KL,fatal-aware masking on,256 parallel tasks,2,048 parallel tool calls。
评测:七个 knowledge-intensive multimodal QA / web-search benchmark:SimpleVQA、VDR、MMSearch、LiveVQA、BrowseComp-VL、FVQA、InfoSeek。指标是 Pass@1,最终答案由 GPT-4o judge 与 reference answer 比较。
Baselines:Direct Reasoning(GPT-4o、GPT-5、Gemini-2.5、Claude、Qwen3-VL 等)、RAG Workflow(GPT-4o/GPT-5/Claude/Qwen3-VL 等)、Agentic Workflow(DeepMMSearch-R1-7B、Visual-ARFT-7B、MMSearch-R1-7B、DeepEyes-v2-7B、WebWatcher、SenseNova-MARS-8B、Qwen3-VL agentic baselines 等)。
5. Experimental Results(实验结果)
5.1 主结果
| Model | SimpleVQA | VDR | MMSearch | LiveVQA | BrowseComp-VL | FVQA | InfoSeek | Avg. |
|---|---|---|---|---|---|---|---|---|
| OpenSearch-VL-8B | 71.6 | 20.8 | 64.5 | 59.6 | 37.6 | 71.5 | 70.2 | 56.6 |
| OpenSearch-VL-30B-A3B | 74.9 | 33.5 | 68.7 | 67.4 | 41.1 | 73.2 | 72.4 | 61.6 |
| OpenSearch-VL-32B | 76.2 | 33.8 | 72.3 | 70.5 | 43.8 | 74.7 | 74.8 | 63.7 |
OpenSearch-VL-8B 的平均分 56.6,超过此前最强 open 8B agent SenseNova-MARS-8B 的 52.7(+3.9)。30B-A3B 和 32B 分别达到 61.6、63.7;相对 Qwen3-VL-30B-A3B agentic baseline 的 47.8 和 Qwen3-VL-32B baseline 的 48.0,提升分别为 +13.8 和 +15.7。论文总结为七个 benchmark 平均提升超过 10 分,并且 32B 在若干任务上接近或超过强闭源 direct-reasoning 系统。
5.2 消融
| Setting / Method | SimpleVQA | InfoSeek | FVQA | Avg. |
|---|---|---|---|---|
| Full SFT pipeline | 66.1 | 62.4 | 65.3 | 64.6 |
| w/o source-anchor grounding | 53.6 | 54.5 | 51.2 | 53.1 |
| w/o fuzzy entity rewriting | 51.7 | 56.4 | 54.7 | 54.3 |
| w/o staged filtering | 57.6 | 55.2 | 56.3 | 56.4 |
| w/o enhancement subset | 64.9 | 61.7 | 63.2 | 63.3 |
| Qwen3-VL-8B base | 52.0 | 50.3 | 58.7 | 53.7 |
| + SFT only | 66.1 | 62.4 | 65.3 | 64.6 |
| + Vanilla GRPO | 68.8 | 66.5 | 67.4 | 67.6 |
| + GRPO w/ Hard Masking | 68.3 | 67.9 | 66.9 | 67.7 |
| + GRPO w/ Fatal Masking only | 69.7 | 68.3 | 69.2 | 69.1 |
| + Fatal Masking + One-sided Clamp | 71.6 | 72.4 | 71.5 | 71.8 |
最大数据消融来自去掉 source-anchor grounding(Avg. 64.6→53.1,-11.5)和 fuzzy entity rewriting(64.6→54.3,-10.3),说明防止单步检索捷径是关键。RL 消融中,vanilla GRPO 从 SFT 的 64.6 提到 67.6;hard masking 几乎无增益(67.7),fatal masking only 到 69.1,而完整 one-sided clamp 到 71.8,比 vanilla GRPO 高 +4.2。
5.3 局限
作者明确指出三类限制:外部工具环境会有 search ranking drift、fetch failure、TextSearch/ImageSearch summarization hallucination,导致 reward variance 增大;composite reward 依赖 proprietary GPT-4o judge,成本高且版本相关,目前主要评价 textual queries,尚未覆盖 Crop 等中间视觉操作;由于 Serper、PaddleX OCR 等外部 API 和大规模评测成本,精确数值复现与multi-seed error bars 都很难。