Idea2Story: An Automated Pipeline for Transforming Research Concepts into Complete Scientific Narratives
Paper: arXiv:2601.20833 Code: AgentAlphaAGI/Idea2Paper Code reference:
main@64170d4d(2026-03-24)
1. Motivation (研究动机)
现有 autonomous scientific discovery agent 已经能把 literature review、代码生成、实验执行、论文草稿串成端到端流程,但主流范式仍是 runtime-centric execution:每次接到新研究想法后,agent 在运行时重新检索大量论文、在线总结长文档、开放式生成候选方法,再通过试错推进实验。论文指出这种“临场读论文 + 临场推理”的方式有三类瓶颈:一次完整研究流程可能耗时数小时甚至约 15 小时;长上下文中重复塞入异构文献会放大 context-window 限制;反复在线压缩未结构化材料会增加 hallucination、脆弱推理和行为漂移。
Idea2Story 要解决的具体问题不是“让 LLM 多写几个 idea”,而是:如何把已有论文中的方法论结构预先抽象成可复用 research pattern,使运行时的研究构思从开放式生成变成有约束的检索、组合和审稿修正。这个问题值得研究,因为自动科研的成本主要不是单次文本生成,而是长期、重复、难以复用的 literature understanding;如果能把这部分变成稳定的 methodological memory,agent 才可能在大规模研究任务上更便宜、更可靠、更少幻觉。
2. Idea (核心思想)
核心洞察:科研 idea 的生成不应该每次都从 raw papers 重新推理,而应该在离线阶段把已发表工作拆成“method unit / meta-method / research pattern”,再在在线阶段围绕这些已验证的结构进行检索和组合。换句话说,Idea2Story 把文献理解从 online reasoning 前移为 offline knowledge construction。
关键创新是一个两阶段框架:离线阶段持续收集 accepted papers 及 peer-review artifacts,抽取核心方法单元,聚类并构建 methodological knowledge graph;在线阶段把用户模糊意图映射到图中的 idea/domain/paper 多视角检索结果,组合候选 research patterns,再用 LLM reviewer 做 novelty、technical soundness、clarity 的 generate–review–revise loop。
与 The AI Scientist、Agent Laboratory、Kosmos 等 runtime agent 相比,Idea2Story 的根本差异在于它不把每次研究都视为从零开始的长上下文推理任务,而是把“前人方法如何组合、哪些组合在 accepted papers 中共现、哪些 patterns 跨 domain 可复用”显式编码成图结构。这样 runtime agent 检索的是方法论结构,而不只是相似论文或关键词。
3. Method (方法)
3.1 Overall framework
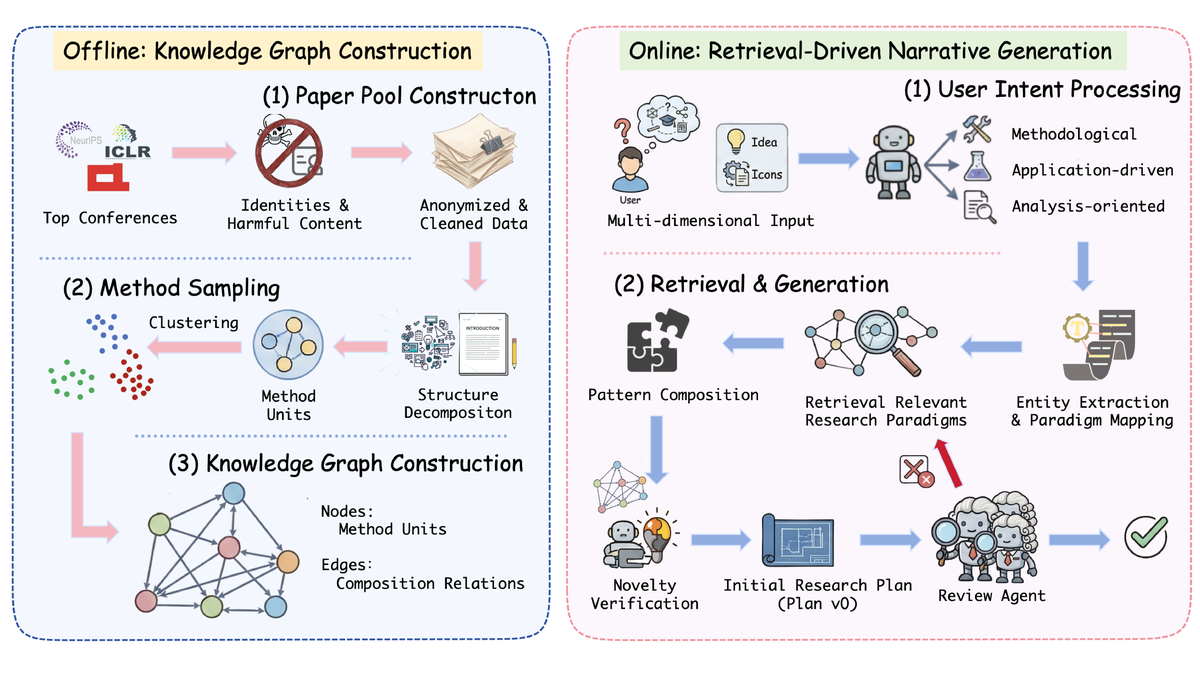
Figure 1 解读:左侧是 offline knowledge graph construction:从 NeurIPS / ICLR 等顶会论文和评审材料出发,先做身份匿名化与有害内容过滤,再把论文拆成 method units,最后把 method units 组织成 composition-relation graph。右侧是 online retrieval-driven narrative generation:用户只给多维度、欠规格化的研究意图,系统先做 intent processing,再检索相关 research paradigms,组合 pattern,进行 novelty verification、初始 research plan 生成和 review-agent 修正。
直觉上,Idea2Story 把“读论文”变成一次性可增量更新的索引构建,把“想 idea”变成在方法图上做结构化检索和组合。这样 LLM 不需要在每个任务里重新吞入大量 paper context,而是在更小、更稳定的 pattern space 中工作。
3.2 Offline knowledge construction
离线阶段构建论文池、抽取 method units、再组织知识图谱。论文把论文池定义为最近三年 NeurIPS 与 ICLR accepted papers:约 5,000 篇 NeurIPS + 8,000 篇 ICLR,并保留论文文本与 review artifacts。
每篇论文的文本与评审信号分别表示为:
隐私和安全处理通过匿名化函数 与过滤函数 完成:
方法单元抽取被建模为:
其中每个 是自包含的 problem formulation / solution pattern / research story 抽象,排除纯数据选择、超参调节、工程优化等不改变问题定义或学习目标的细节。论文随后用 得到论文级 embedding,并把相似 units 归并成 canonical meta-method。
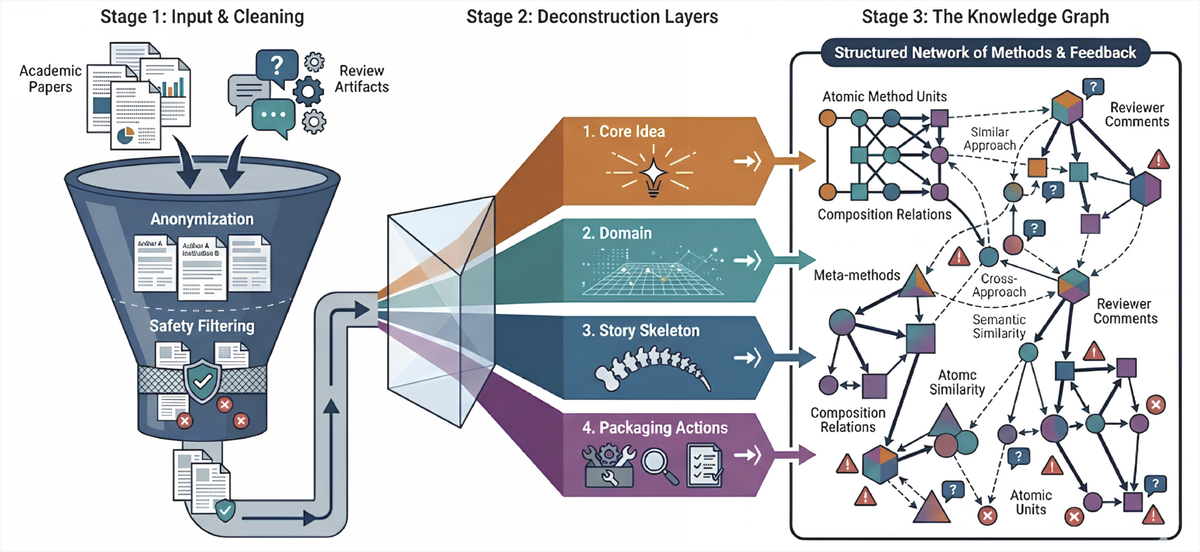
Figure 2 解读:这张图把 offline 阶段拆成三层。Stage 1 对 academic papers 与 review artifacts 做 anonymization / safety filtering;Stage 2 从论文中抽取 core idea、domain、story skeleton、packaging actions 四类互补层;Stage 3 把这些抽象转成 knowledge graph,其中 atomic method units、meta-methods、reviewer comments 通过 composition relation、semantic similarity、cross-approach links 连接起来。
知识图谱定义为有向图:
节点 是 canonicalized method units 或 meta-methods;边 记录在同一篇 accepted paper 中共同实例化的方法组合,例如 。因此边不是人工拍脑袋定义的“可能相关”,而是从已发表论文中观察到的 composition compatibility。
3.3 Online research generation
在线阶段把用户研究意图 映射到 graph 上的 research pattern。给定候选 patterns ,Idea2Story 用 idea、domain、paper 三个视角打分:
三个分数分别覆盖:与历史 research ideas 的语义相似度、与 domain / sub-domain 的相关性和有效性权重、与相似论文及其 review-quality weight 的匹配。得到候选 pattern 后,系统进入显式 LLM reviewer loop: reviewer 评价 novelty、technical soundness、problem–method alignment,并给出 revision suggestions;如果 novelty 不足,就重组兼容 method units 或引入同一 pattern family 的替代实现;如果 feasibility / formulation 有问题,就修改问题定义或方法结构;只有 reviewer score 改善的版本才保留,否则回滚。
3.4 Method-unit example

Figure 3 解读:源码中的 Figure 3 是一个 tcolorbox 示例,没有独立 includegraphics 文件;这里按 LaTeX 源文本重绘。例子展示 method unit 不只是摘要,而是把一篇 accepted paper 拆成 Base Problem、Solution Pattern、Story、Application:例如“理解 finetuning 中训练样本如何影响 LLM prediction”被抽象成“step-wise influence accumulation 框架”,再上升到“用 learning dynamics 解释 hallucination / alignment”的研究故事。
这个抽象粒度很关键:如果只保存 paper title 或 abstract,在线阶段只能做相似论文检索;如果保存 method unit,系统可以把一个领域里的 solution pattern 迁移到另一个领域,并判断哪些 units 曾经在 accepted papers 中共同出现。
3.5 Knowledge graph structure
Figure 4 解读:Figure 4 可视化 high-frequency research domains 诱导出的子图。绿色 domain nodes 是 hub,蓝色 pattern nodes 与红色 paper nodes 围绕它们展开。论文强调 paper-level nodes 通常只连到单一 domain,但 pattern-level nodes 经常跨 domain 连接,说明 method units 捕捉到的是可复用的方法论抽象,而不仅是同一领域内的论文相似度。
3.6 Released-code grounding and paper-code gaps
论文在摘要中给出公开代码链接。代码搜索确认 public repo 为 AgentAlphaAGI/Idea2Paper,本笔记基于 main@64170d4d(2026-03-24)。源码实现的是 Idea2Paper/Idea2Story 官方 demo 与工程化 pipeline,和论文叙述存在几个需要显式记录的差异:
- 论文实验语境是约 13K NeurIPS + ICLR accepted papers;repo README 与
build_entity_v3.py当前强调 ICLR 数据源 / prebuilt ICLR graph,Paper-KG-Pipeline/data/也提供 sample JSONL,因此 public code 不等于论文完整 13K corpus dump。 - 论文实验说 qualitative cases 使用 GLM-4.7,direct LLM baseline 也用同一模型;repo 根目录
i2p_config.json默认llm.provider=openai_compatible_chat、llm.model=gpt-4o-mini、embedding.model=text-embedding-3-large,实际复现需要通过环境变量或配置改成论文模型。 - 论文公式只抽象写 ;源码
RecallConfig明确三路召回权重为 Path1 idea 0.4、Path2 domain 0.2、Path3 paper 0.4,并使用 Jaccard 粗排 + embedding 精排。
下面伪代码按源码结构写成 Python/PyTorch 风格;它是对 released code 的结构化改写,不是论文中直接给出的算法框。
def extract_method_unit_with_reviews(paper_json, review_json, llm):
"""Grounded in scripts/tools/extract_paper_review.py."""
sections = parse_json_paper(paper_json)
reviews = parse_reviews(review_json, paper_id=sections.paper_id)
domain = llm.json(
task="extract_domain",
inputs={"title": sections.title, "keywords": sections.keywords, "abstract": sections.abstract},
)
ideal = llm.json(
task="extract_ideal",
inputs={
"abstract": sections.abstract,
"introduction": sections.introduction[:3000],
"method_intro": sections.method[:1500],
},
)
skeleton = llm.json(
task="extract_skeleton",
inputs={
"introduction": sections.introduction[:3000],
"related_work": sections.related_work[:2000],
"method": sections.method[:3000],
"experiments": sections.experiments[:3000],
},
)
tricks = llm.json(
task="extract_tricks",
inputs={"intro": sections.introduction[:3000], "method": sections.method[:4000]},
)
return {
"paper_id": sections.paper_id,
"domain": domain,
"core_idea": ideal["core_idea"],
"method_unit": {
"base_problem": skeleton["problem_framing"],
"solution_pattern": ideal["tech_stack"],
"story": skeleton["method_story"],
"packaging_actions": tricks,
"reviews": reviews,
},
}def build_methodological_graph(assignments, clusters, pattern_details, reviews):
"""Grounded in scripts/tools/build_entity_v3.py and build_edges.py."""
G = DirectedGraph()
for cluster in clusters:
if cluster["cluster_id"] == -1:
continue
pattern_id = f"pattern_{cluster['cluster_id']}"
G.add_node(pattern_id, type="pattern", name=cluster["cluster_name"], size=cluster["size"])
for paper_id, details in pattern_details.items():
idea_id = hash_to_id(details["idea"])
G.add_node(idea_id, type="idea", description=details["idea"])
G.add_node(paper_id, type="paper", title=details.get("title", ""))
G.add_edge(paper_id, idea_id, relation="implements")
for assignment in assignments:
paper_id = assignment["paper_id"]
pattern_id = f"pattern_{assignment['cluster_id']}"
domain_id = canonical_domain_id(assignment["domain"])
quality = parse_review_quality(reviews.get(paper_id, []))
G.add_edge(paper_id, pattern_id, relation="uses_pattern", quality=quality)
G.add_edge(paper_id, domain_id, relation="in_domain")
G.add_edge(pattern_id, domain_id, relation="works_well_in", weight=domain_effectiveness(pattern_id, domain_id))
return Gimport torch
import torch.nn.functional as F
def recall_research_patterns(query, idea_index, domain_index, paper_index, graph, embedder):
"""Grounded in src/idea2paper/recall/recall_system.py."""
q = torch.tensor(embedder(query), dtype=torch.float32)
# Path 1: similar ideas, Jaccard coarse filter in code, embedding fine rank here.
idea_emb = torch.stack([torch.tensor(x.embedding) for x in idea_index.candidates(query, topn=100)])
idea_scores = F.cosine_similarity(q[None, :], idea_emb, dim=-1)
top_ideas = idea_scores.topk(k=20).indices.tolist()
path1 = score_patterns_from_idea_neighbors(top_ideas, graph)
# Path 2: domain / sub-domain relevance.
domain_emb = torch.stack([torch.tensor(x.embedding) for x in domain_index.all_domains()])
domain_scores = F.cosine_similarity(q[None, :], domain_emb, dim=-1)
top_domains = domain_scores.topk(k=5).indices.tolist()
path2 = score_patterns_from_domain_edges(top_domains, graph, subdomain_boost=1.0)
# Path 3: similar papers weighted by paper quality.
paper_emb = torch.stack([torch.tensor(x.embedding) for x in paper_index.candidates(query, topn=100)])
paper_scores = F.cosine_similarity(q[None, :], paper_emb, dim=-1)
top_papers = paper_scores.topk(k=20).indices.tolist()
path3 = score_patterns_from_papers(top_papers, graph, quality_weight=True)
final = 0.4 * path1 + 0.2 * path2 + 0.4 * path3
return final.topk(k=10)def run_idea2story_pipeline(user_idea, pipeline):
"""Grounded in application/pipeline/manager.py, pattern_selector.py, critic.py, refinement.py."""
ranked_patterns = pipeline.pattern_selector.select() # stability / novelty / domain_distance
pattern = first_available(ranked_patterns, preference=["stability", "novelty", "domain_distance"])
story = pipeline.story_generator.generate(pattern_id=pattern.id, pattern_info=pattern.info)
best_story, best_score = story, 0.0
for iteration in range(pipeline.config.MAX_REFINE_ITERATIONS): # code default: 3
critic_context = pipeline.build_critic_context(pattern)
review = pipeline.critic.review(story, context=critic_context)
if review["avg_score"] > best_score:
best_story, best_score = story, review["avg_score"]
if review["pass"]:
break
fused_idea = pipeline.refinement_engine.refine_with_idea_fusion(
main_issue=review["main_issue"],
suggestions=review["suggestions"],
previous_story=story,
)
candidate = pipeline.story_generator.generate(
pattern_id=pattern.id,
pattern_info=pattern.info,
previous_story=story,
review_feedback=review,
fused_idea=fused_idea,
)
reflected = pipeline.story_reflector.reflect_on_fusion(story, pattern.info, fused_idea, review, user_idea)
story = candidate if reflected["ready_for_generation"] else best_story
return best_storyCode reference:
main@64170d4d(2026-03-24) — pseudocode and mapping based on this commit
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Paper/review parsing and method-unit extraction | Paper-KG-Pipeline/scripts/tools/extract_paper_review.py | extract_paper_with_reviews, extract_ideal, extract_skeleton, extract_tricks |
| Pattern extraction from JSONL papers | Paper-KG-Pipeline/scripts/extract_patterns_ICLR_en_local.py | build_paper_info, render_prompt, main |
| Knowledge graph node construction | Paper-KG-Pipeline/scripts/tools/build_entity_v3.py | KnowledgeGraphBuilderV3.build, _build_pattern_nodes, _build_idea_nodes, _build_domain_nodes |
| Knowledge graph edge construction | Paper-KG-Pipeline/scripts/tools/build_edges.py | EdgeBuilder.build_all_edges, _build_paper_edges, _build_pattern_works_well_in_domain_edges |
| Three-path pattern recall | Paper-KG-Pipeline/src/idea2paper/recall/recall_system.py | RecallSystem.recall, _recall_path1_similar_ideas, _recall_path2_domain_patterns, _recall_path3_similar_papers |
| Pattern selection and multidimensional ranking | Paper-KG-Pipeline/src/idea2paper/application/pipeline/pattern_selector.py | PatternSelector.select, _score_patterns_multidimensional, _rank_patterns_by_dimensions |
| Story generation / revision | Paper-KG-Pipeline/src/idea2paper/application/pipeline/story_generator.py | StoryGenerator.generate, _build_generation_prompt, _parse_story_response |
| Review-guided refinement | Paper-KG-Pipeline/src/idea2paper/application/review/critic.py; application/pipeline/refinement.py | MultiAgentCritic.review, RefinementEngine.refine_with_idea_fusion |
| End-to-end runner and config preflight | Paper-KG-Pipeline/scripts/idea2story_pipeline.py; application/pipeline/manager.py | main, ensure_required_indexes, Idea2StoryPipeline.run |
| Runtime constants and config defaults | Paper-KG-Pipeline/src/idea2paper/config.py; i2p_config.json | PipelineConfig.MAX_REFINE_ITERATIONS, SELECT_PATTERN_COUNT, llm.model, embedding.model |
4. Experimental Setup (实验设置)
Datasets / corpus. 论文的离线知识构建使用最近三年的 accepted ML papers 与 reviews:约 5,000 篇 NeurIPS、约 8,000 篇 ICLR,总计约 13K papers,并保留 comments、ratings、confidence scores、meta-reviews 等评审信号。另有三条由 external collaborator 提供的 user research ideas 用于 qualitative experiments。
Baselines. 主要 baseline 是 direct LLM generation:同样使用 GLM-4.7,但不给显式 pattern modeling / retrieval,让模型直接从同一 underspecified input 生成完整 research story。论文还在 related work 中把 The AI Scientist、AI Scientist-v2、Kosmos、Agent Laboratory、AgentReview 等作为背景对比,但实验表格的直接对照是 direct GLM-4.7 baseline。
Evaluation metrics / criteria. 论文没有提供传统数值 benchmark 分数;它使用三类定性证据:method-unit extraction case study、knowledge graph structural analysis、generated research pattern qualitative comparison。生成结果再由独立 Gemini 3 Pro 评估 novelty、methodological substance、overall research quality,且 evaluator 不知道输出来自 Idea2Story 还是 direct baseline。
Implementation / runtime config. 论文实验报告的 backbone 是 GLM-4.7;硬件、GPU 数、LR、batch size、训练步数未报告,因为本文不是训练新模型,而是构建 retrieval / graph / review pipeline。released code 的默认配置来自根目录 i2p_config.json:llm.model=gpt-4o-mini、embedding.model=text-embedding-3-large、story generation temperature 0.7、pattern selector temperature 0.3、critic temperature 0.0;recall_system.py 中三路召回权重为 0.4 / 0.2 / 0.4,最终 top-k 为 10。
5. Experimental Results (实验结果)
Method-unit extraction case. Figure 3 的 accepted-paper case 显示,Idea2Story 能把论文拆成 Base Problem、Solution Pattern、Story、Application,而不是简单摘要。这个结果支持作者的核心主张:method unit 是比 paper-level similarity 更适合复用的中间表示,因为它保留了“问题如何被重构、方法如何被包装、应用如何被泛化”的结构。
Knowledge graph analysis. Figure 4 显示 high-frequency domains 形成 hub-and-spoke 结构;paper nodes 通常依附于单个 domain,而 pattern nodes 更常跨 domain 连接。论文据此认为 graph 同时编码了 instance-level research artifacts 与 reusable methodological abstractions,能支持跨领域 pattern retrieval 与 composition。
Qualitative comparison. Table 1 使用同一个输入 “I want to build an e-commerce agent that can better understand user intent.” 对比 Idea2Story 与 direct LLM:
| Aspect | Idea2Story: IntentDiff | Direct LLM: EcoIntent |
|---|---|---|
| Problem framing | 把 intent classification 重构为 structural evolution / dynamic reasoning | 仍是 query + session context 到 predefined intent label 的 conventional classification |
| Method skeleton | Diffusion-based denoising classifier + context-aware discrete tokenizer + product graph structural priors | BERT text encoder + behavior-graph GNN + hierarchical contrastive learning + LoRA |
| Innovation claim | 强调 dynamic refinement、long-tail domain vocabulary、product graph priors 的统一 | 强调 context modeling、taxonomy hierarchy、parameter-efficient design |
| 作者解读 | 更高层地重构问题并生成有结构先验的 research pattern | 更像把常见模块叠加成 stronger system,方法论 grounding 较弱 |
External evaluation. 论文称在所有 evaluated cases 中,独立 Gemini 3 Pro consistently favors Idea2Story outputs:direct LLM 生成的 stories 更抽象、方法 grounding 更弱、常依赖标准技术;Idea2Story 生成的 patterns 有更清晰的问题 framing、更具体的方法结构和更强 novelty signals。这里没有给出分数或显著性检验,因此结论应理解为 preliminary qualitative evidence,而不是严格 benchmark 胜率。
Limitations / future work. 论文明确把未来方向放在 closed-loop research generation:把 Idea2Story 与 experiment-driven agents 结合,让 generated research patterns 能被自动实验设计、数据集选择、初步执行和 empirical feedback 验证,再把 validated patterns 转成完整 paper drafts。当前工作的限制也由此可见:它主要证明 offline methodological graph 对 ideation 有帮助,但尚未闭环证明这些 ideas 在真实实验中可执行、可复现、可发表;评估规模也以 qualitative cases 为主,缺少大规模人类专家盲评和定量 ablation。