GameWorld: Towards Standardized and Verifiable Evaluation of Multimodal Game Agents
Paper: arXiv:2604.07429 Project: gameworld-bench.github.io Code: gameworld-project/gameworld; game assets/snapshots: gameworld-dev/gameworld-games Code reference:
main@e236a397(2026-05-13); game librarymain@4753449e(2026-04-20)
1. Motivation (研究动机)
现有 MLLM / GUI agent 评测大多停留在静态 VQA、网页任务或少量游戏环境,难以同时覆盖视觉感知、实时反应、长程计划、动作约束和可复现实验。游戏特别适合作为中间形态的 embodied benchmark:环境视觉丰富、状态随动作闭环演化、错误不可随意撤销;但已有 game benchmarks 往往存在游戏数少、动作接口异构、评估依赖视觉启发式或 VLM-as-judge、任务初始化和并行实例不标准等问题。

Figure 1 解读:这张 teaser 展示 GameWorld 覆盖的 34 个 browser games。作者选择 browser 环境而不是重型引擎/模拟器,是为了让每个游戏可以被快速 reset、可并行启动,并通过统一的 gameAPI 暴露可验证状态。
本文要解决的核心问题是:如何在同一个可执行 runtime 中,公平评测“直接发键鼠动作”的 Computer-Use Agent(CUA)和“发语义动作”的 generalist multimodal agent,并且让成功/进度指标来自 game state,而不是来自模型回复文本或视觉判断。这个问题值得做,因为如果 benchmark 不能隔离动作接口、推理延迟、状态验证和长程 memory,就很难判断 agent 失败到底来自感知、规划、控制 grounding,还是评测噪声。
2. Idea (核心思想)
核心 insight:GameWorld 把游戏 agent 评测拆成四个可复用部件——模型接口、browser sandbox、游戏/任务 catalog、state-verifiable evaluator。这样 CUA 和 generalist agents 可以共享同一套任务与状态评估,只在 action interface 处不同:CUA 输出低层键鼠事件;generalist agent 输出注册过的语义 control,再由 deterministic Semantic Action Parsing 映射到低层动作。
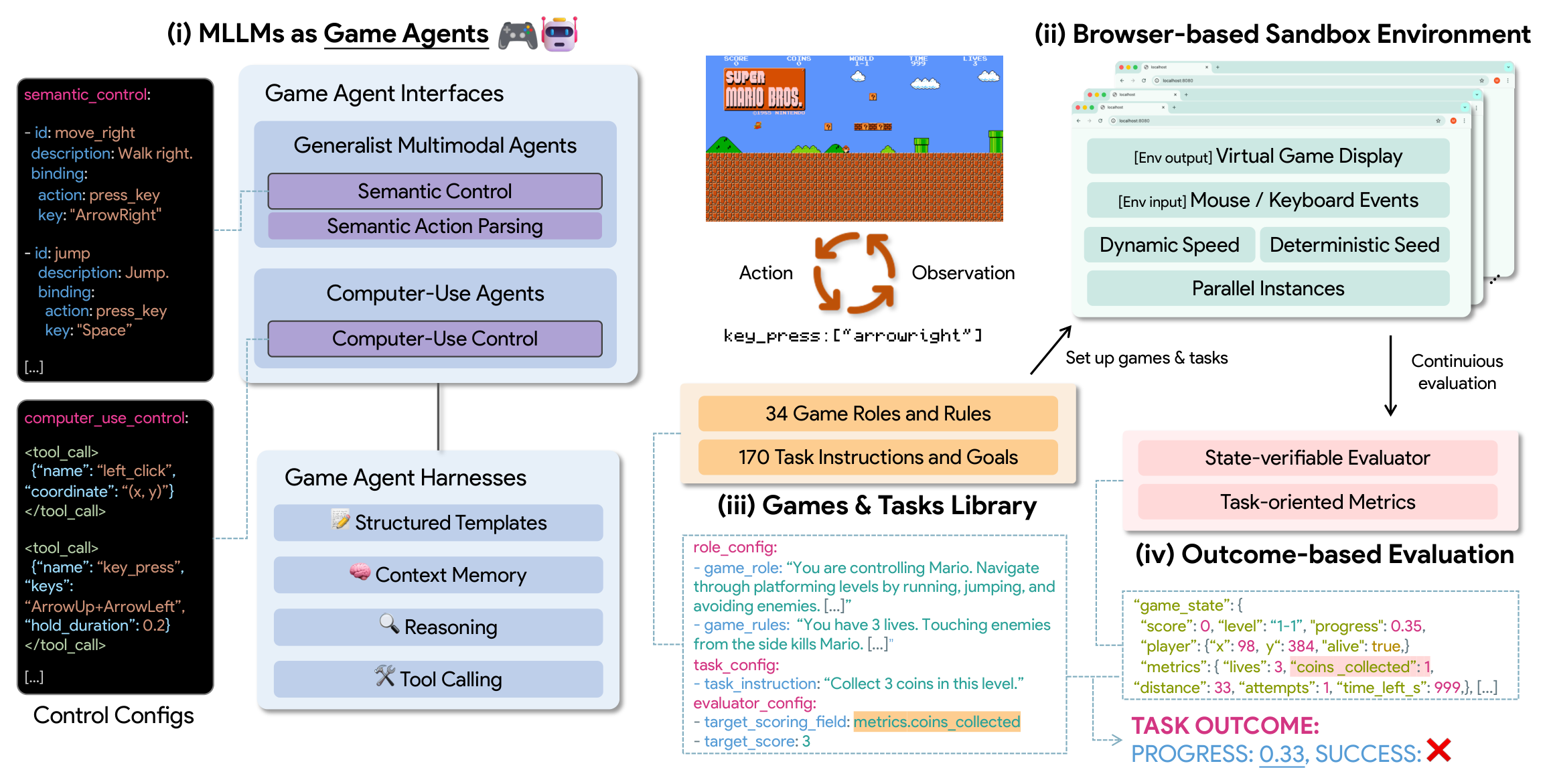
Figure 2 解读:图中闭环是“observation → action → browser execution → state-verifiable evaluation”。与 LMGame-Bench 等更偏文本或少量游戏的 benchmark 相比,GameWorld 的差异不是只增加游戏数量,而是把每一步执行和评估都落在统一 runtime 上:模型看到 screenshot 和结构化 prompt,动作被解析/验证后由浏览器执行,评估器读取 gameAPI.getState() 计算 task outcome。
本质创新有三点:第一,任务被定义为自然语言指令 + 初始化/URL 配置 + target metric + evaluator config;第二,评估不看模型“是否说对”,而看状态字段是否达到目标;第三,提出 paused benchmark 与 GameWorld-RT 两种 protocol,前者隔离 decision quality,后者暴露真实部署时的 latency/control 代价。
3. Method (方法)
3.1 Benchmark 结构与任务定义
GameWorld 包含 34 个 browser games、170 个 tasks、5 类游戏:Arcade 7、Platformer 8、Puzzle 7、Runner 8、Simulation 4。每个 task 都有目标分数、最大步数和 evaluator 配置;released code 中 170 个 catalog/tasks/*/*.yaml 全部使用 evaluator_id: game_api_metric、max_steps: 100、pause_during_inference: true、continue_on_fail: true。这说明论文主 benchmark 的默认结果主要衡量“同一 action budget 下的决策质量”,而不是模型的真实响应速度。
3.2 Agent interface:CUA vs. Semantic Action Parsing
CUA 直接输出低层控制,例如 mouse_move(x, y)、left_click(x, y)、press_key(key);为了可比性,每个 model response 只能包含一个可执行 atomic action。Generalist agent 不直接发像素级鼠标/键盘,而是从当前 game role 注册的 semantic controls 中选择一个动作,例如 move_left、wait,runtime 再把它 deterministic 地映射到低层 action dict。这个设计避免要求所有 MLLM 都具备原生 computer-use API,同时又不让 generalist agent 通过多步 macro 绕过动作预算。
论文公式与 released code 实现差异:附录写道 Semantic Action Parsing 的 control identifier 可来自 action、tool_name 或 tool_id;但 agents/harness/semantic_controls.py 的 _extract_control_id() 当前只读取 tool_name。因此以 action / tool_id 作为字段名的 released-code payload 会被 inspect_semantic_controls_output() 判为 missing_tool_name,这比论文描述更严格。
3.3 State-verifiable evaluation 与指标公式
每个游戏需要暴露 window.gameAPI,包含 init(config)、reset(options)、getState()。getState() 的顶层 contract 包含 gameId、timestampMs、gameTimeMs、status、terminal、game_state、metrics、raw;评估器只读取可序列化 state,不依赖 screenshot 上的视觉启发式。
对 run ,令 是 step 从可验证 game state 读出的 task score,, 是起始分数, 是目标阈值。论文定义 normalized progress:
reset-on-fail 开启时,episode-local score 会在 reset 后清空,但 run-level best progress 保留,所以 表示整个 100-step budget 内达到过的最远归一化进度。整体成功率和平均进度为:
动作合法性用 Invalid Action Rate 衡量:
3.4 Released code 对照
Code source for this section:
gameworld-project/gameworldmain@e236a397(2026-05-13);gameworld-dev/gameworld-gamesmain@4753449e(2026-04-20).
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
Registry preset <game_id>+<task_id>+<model_spec> | catalog/builder.py, catalog/games/*.yaml, catalog/tasks/*/*.yaml, catalog/models/*.yaml | build_runtime_config() |
| Observation-action-evaluation loop | main.py, runtime/coordinator.py | Coordinator._get_raw_action(), _run_agent_step(), _handle_eval_controls() |
| Browser sandbox and pausing | runtime/env.py, env/browser_manager.py, env/game_launcher.py | GameEnv.start(), pause_game(), resume_game(), capture_state() |
| Semantic Action Parsing | agents/harness/semantic_controls.py | map_semantic_controls_output(), inspect_semantic_controls_output() |
| Low-level action validation | env/action_executor.py | ActionExecutor.inspect_action(), _parse_press_key(), _parse_click_action() |
| State-verifiable evaluator | env/game_state_tracker.py, env/task_evaluator.py | GameAPIStateTracker.capture(), build_task_evaluator(), _update_progress_metrics(), _resolve_outcome() |
| Full-suite repeated runs | run_suite.py, tools/suite_runner/*, benchmark/suites/*.yaml | run_wave(), write_suite_outputs() |
Implementation-based pseudocode(按 released code 抽象):
def build_runtime_config_from_preset(preset: str) -> RuntimeConfig:
game_id, task_id, model_ids = parse_game_task_models(preset)
game = load_game(game_id) # rules, roles, low-level controls, semantic controls
task = load_task(game_id, task_id) # prompt, evaluator config, target score, max_steps
models = [load_model(mid) for mid in resolve_model_ids(game, model_ids)]
role_controls, semantic_maps, semantic_specs = [], [], []
prompts, enable_memory = [], []
for role, model in zip(game.game_roles, models):
role_controls.append(role.controls.copy())
semantic_map = build_semantic_controls_map(role.semantic_controls)
semantic_maps.append(semantic_map)
semantic_specs.append([a.to_runtime_spec() for a in role.semantic_controls])
template = load_prompt_template(model.require_prompt_template_id())
prompts.append(render_system_prompt(
template_name=template.template_name,
game_rules=game.game_rules,
task_prompt=task.task_prompt,
role_section=role.prompt.role_section,
computer_use_controls_section=role.prompt.computer_use_controls_section,
semantic_action_space=render_semantic_action_space(role.semantic_controls),
output_format=model.output_format,
))
enable_memory.append(model.enable_memory)
return RuntimeConfig(
game_id=game_id, task_id=task_id, max_steps=task.max_steps,
evaluator_id=task.evaluator_id, evaluator_config=task.evaluator_config,
pause_during_inference=task.pause_during_inference,
continue_on_fail=task.continue_on_fail,
role_controls_maps=role_controls,
semantic_controls_maps=semantic_maps,
system_prompts=prompts,
)async def run_one_agent_step(agent, env, evaluator):
screenshot = await env.capture_screenshot(agent.agent_id)
if env.pause_during_inference:
await env.pause_game()
try:
raw_action = await to_thread(agent.client.get_action, screenshot)
finally:
if env.pause_during_inference:
await env.resume_game()
if agent.agent_type == "generalist":
action = map_semantic_controls_output(raw_action, agent.semantic_controls_map)
else:
action = raw_action
validity = inspect_semantic_or_low_level_action(agent, raw_action, action)
await env.execute_action(agent, action)
state = await env.capture_state() # window.gameAPI.getState()
result = await evaluator.evaluate(agent, state)
if result.should_reset:
await env.reset_game()
agent.eval_metrics = evaluator.reset_metrics(agent.eval_metrics)
if result.should_stop:
stop_run()def map_semantic_controls_output(raw: dict, semantic_controls_map: dict) -> dict:
control_id = raw.get("tool_name") # released code only accepts this key
mapped = dict(semantic_controls_map[control_id])
arguments = raw.get("arguments")
if isinstance(arguments, str):
arguments = json.loads(arguments)
for k, v in arguments.items():
if k not in ('tool_name', 'arguments') and k not in mapped and v is not None:
mapped[k] = v
if "cell_bindings" in mapped and "cell" in arguments:
mapped["x"], mapped["y"] = lookup_cell_xy(mapped["cell_bindings"], arguments["cell"])
del mapped["cell_bindings"]
mapped.setdefault("semantic_controls", control_id)
return mappeddef update_state_verifiable_metrics(metrics, state, target_score):
should_reset = False
score_current = resolve_score_from_state(state, config.score_field)
metrics["score_best"] = max(metrics.get("score_best", start_score), score_current)
progress = (metrics["score_best"] - start_score) / (target_score - start_score)
metrics["progress"] = min(1.0, max(0.0, progress))
target_reached = metrics["score_best"] >= target_score
terminal_hit = state.get("terminal", {}).get("isTerminal")
max_steps_hit = step_index >= max_steps
end_match = get_nested(state, config.end_field) == config.end_value
if target_reached:
status, stop_reason, should_stop = "success", "target_reached", True
elif continue_on_fail and terminal_hit and terminal_outcome_is_fail(state):
status, stop_reason, should_stop = "fail", "terminal_fail_reset", False
should_reset = True
elif max_steps_hit:
status, stop_reason, should_stop = "fail", "max_steps_exhausted", True
else:
status, stop_reason, should_stop = "unknown", None, False
return TaskEvaluationResult(status, metrics, should_stop=should_stop, should_reset=should_reset)3.5 关键可视化与 case studies
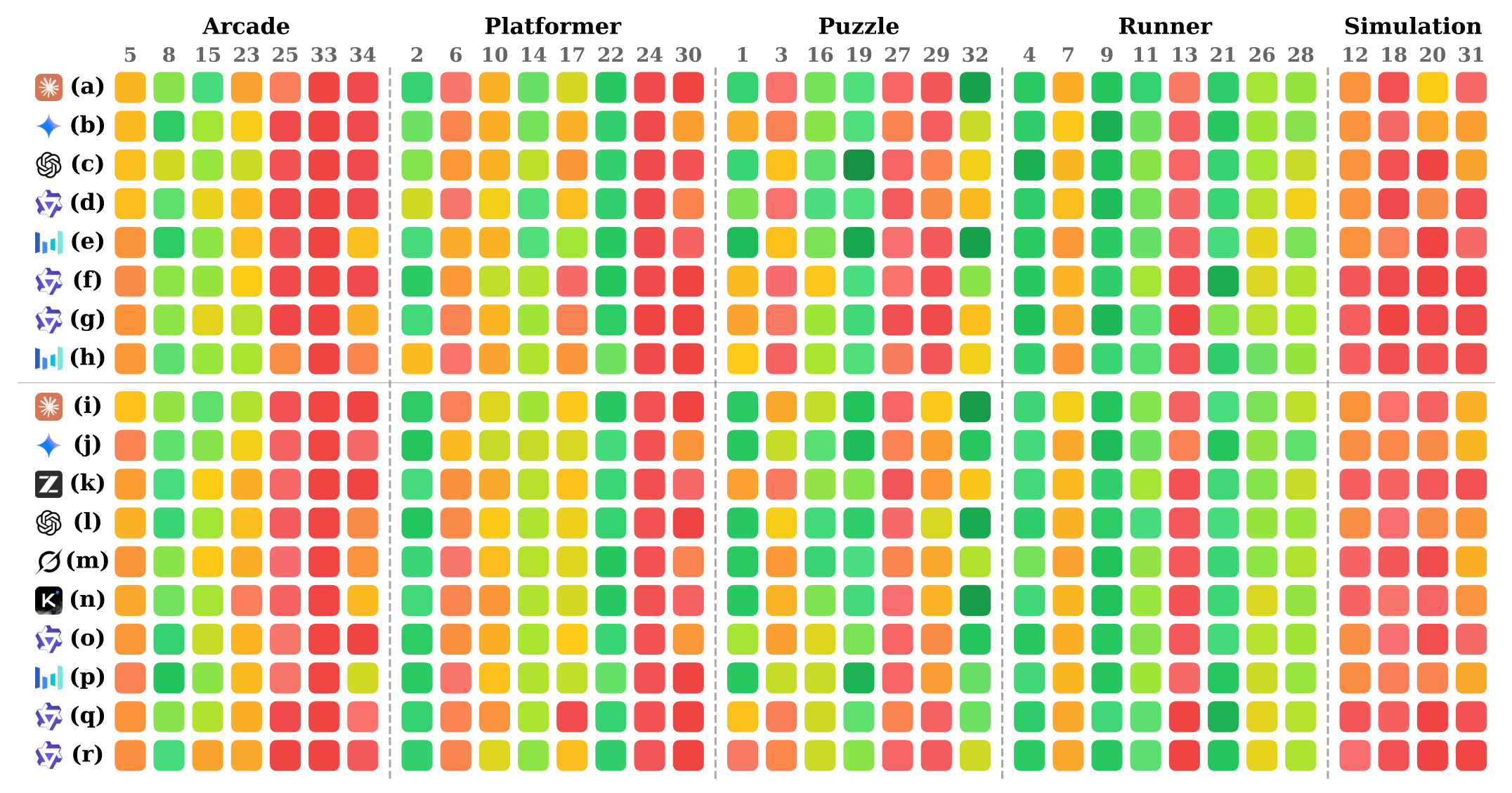
Figure 3 解读:每行是一个 model-interface pair,每列是游戏 task 的 progress heatmap。Runner 普遍更容易取得进度,而 Simulation 经常接近低进度;这支持作者的判断:当前 agent 能做局部 reactive/control,但在开放式资源管理和多目标协调中弱。
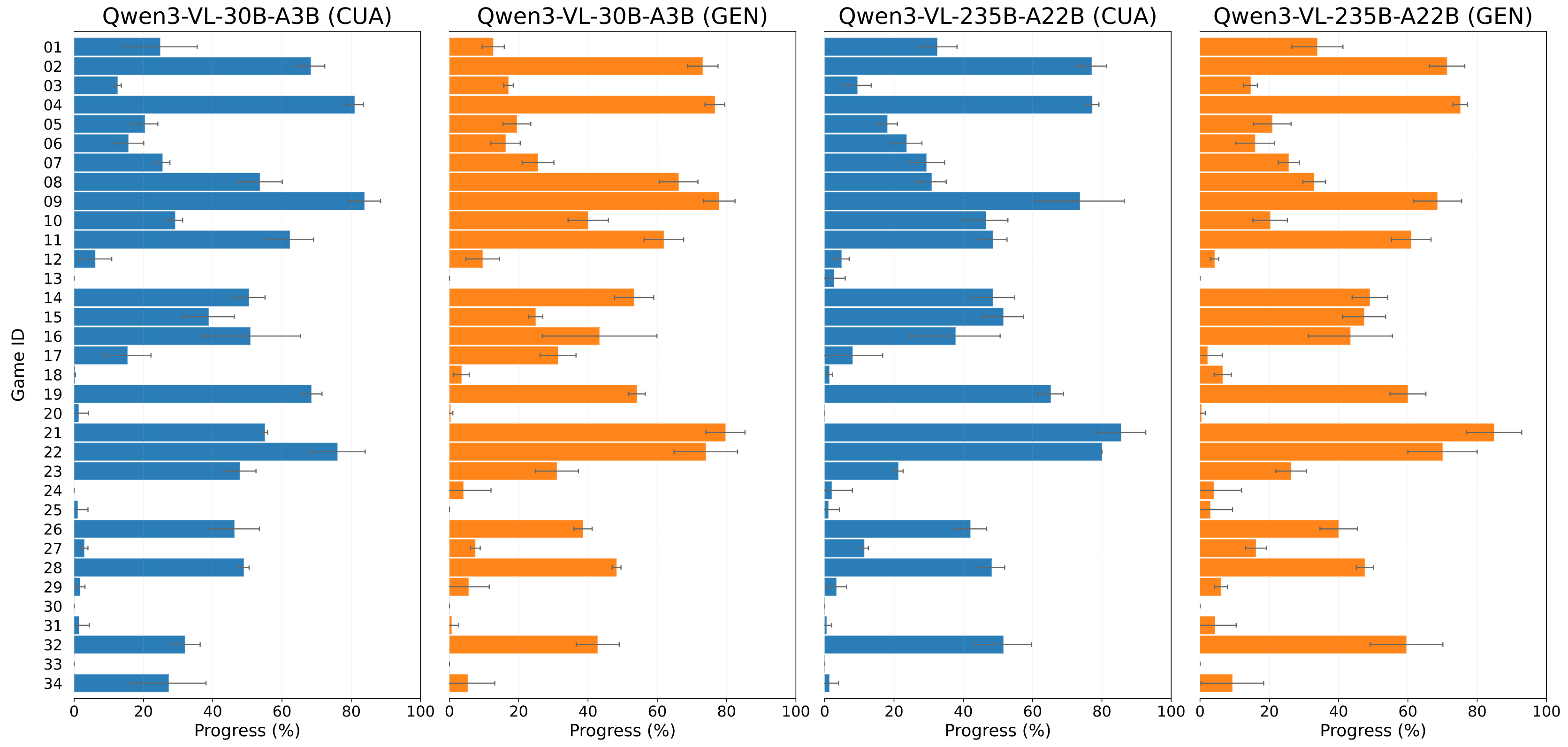
Figure 4 解读:四个 Qwen 设置在 10 次 repeated full-benchmark run 上的 per-game progress 分布。大多数游戏的误差带较窄,说明 benchmark 聚合指标较稳定;较大的方差集中在控制敏感或高随机性的游戏。
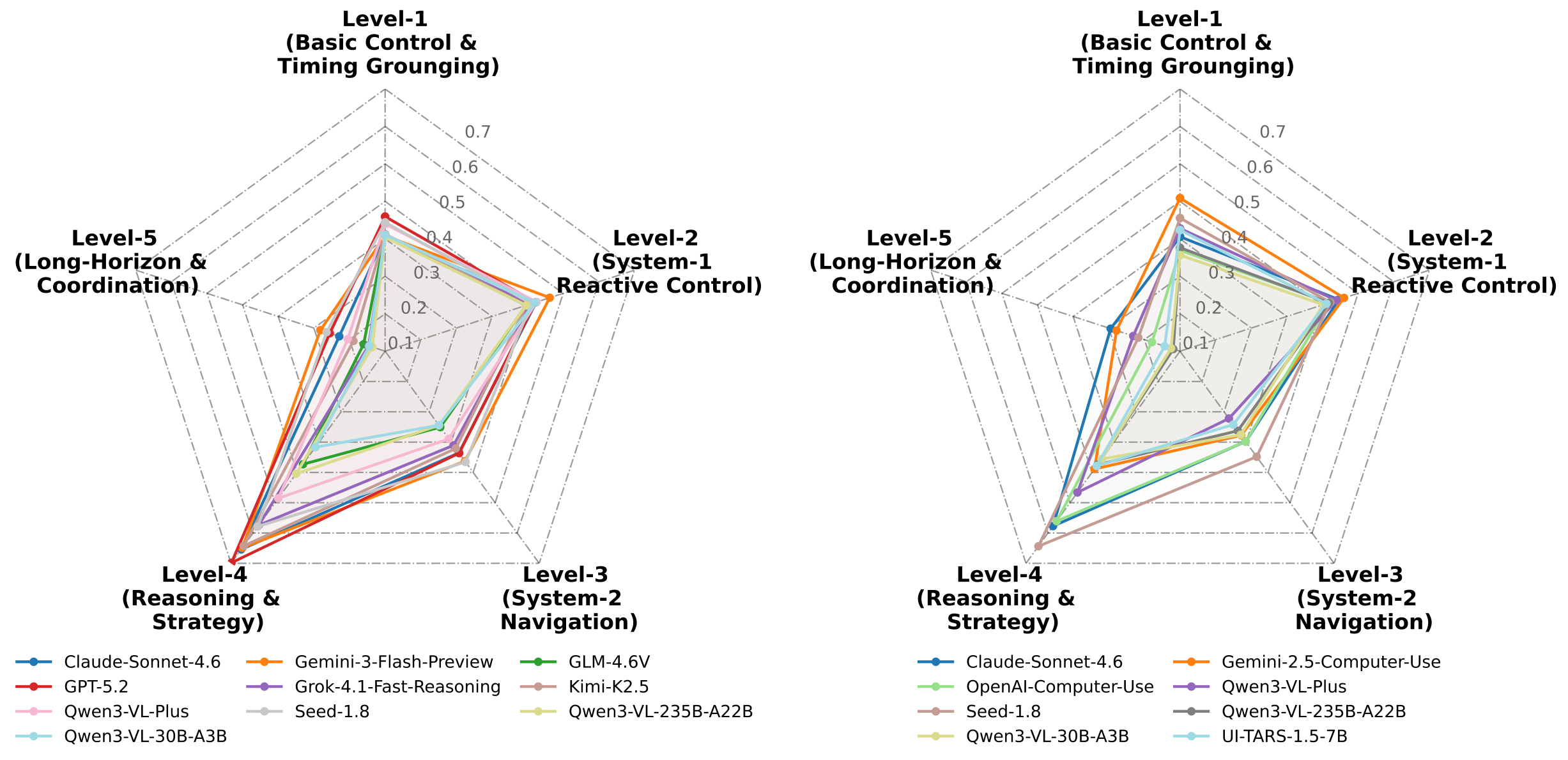
Figure 5 解读:作者把任务按能力划分为 Level-1 basic control/timing、Level-2 reactive control、Level-3 spatial navigation、Level-4 symbolic reasoning/strategy、Level-5 open-world coordination。雷达图显示两种 interface 都在 Level-4 相对更强,在 Level-5 明显退化,表明当前 MLLM agent 的长程协调和开放世界管理仍是短板。

Figure 6 解读:Mario case 把 CUA 轨迹和 Generalist 轨迹并排。两者面对相同任务时,差异主要来自 action grounding:CUA 直接操作键鼠但需要精确 timing;Generalist 的语义动作更稳定,但会损失细粒度控制。

Figure 7 解读:Minecraft Clone case 中 agent 可以执行局部合理动作、把 progress 推到 90%,但仍未完成目标。这里的失败不是单步动作非法,而是长程资源收集和目标维护不够稳。
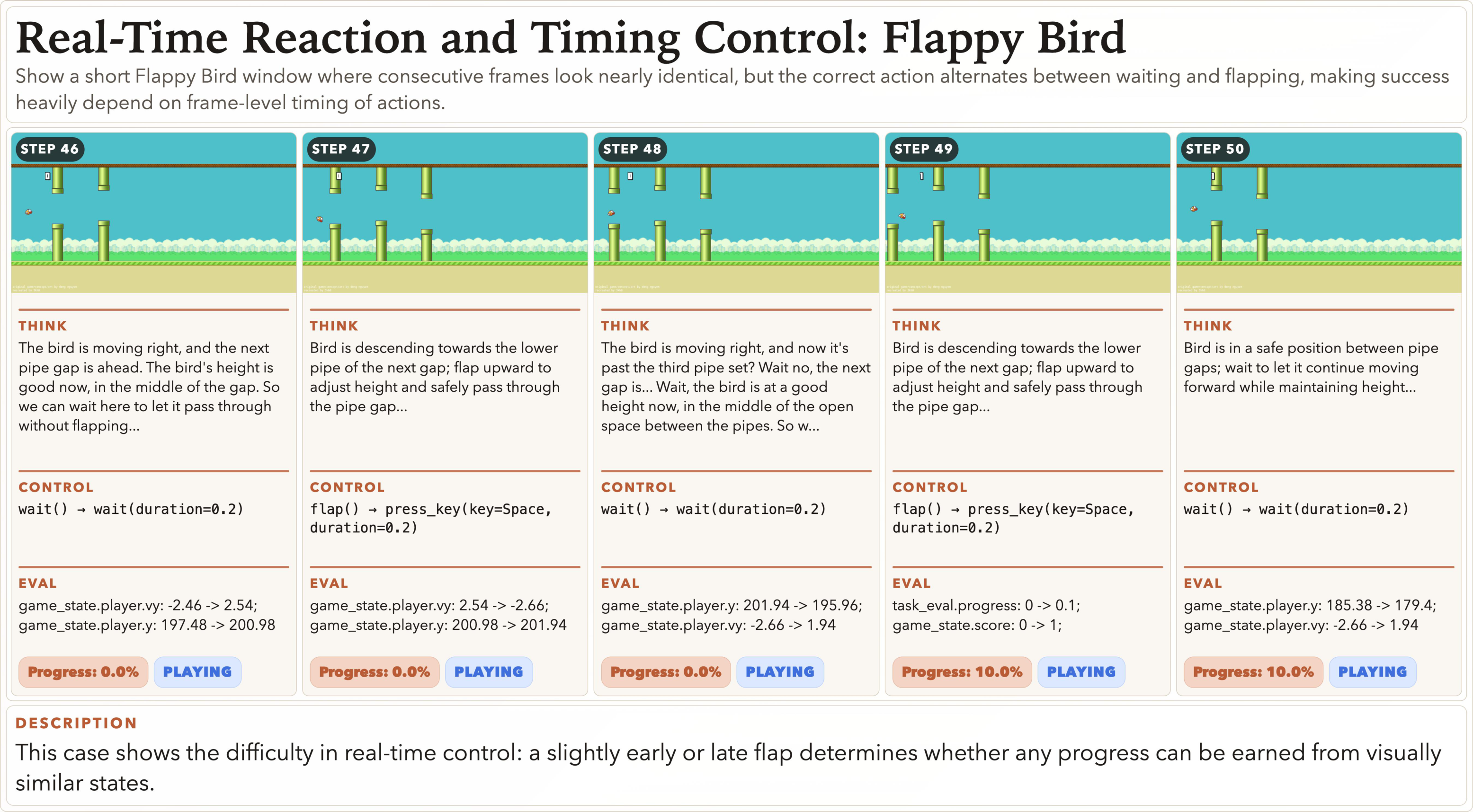
Figure 8 解读:Flappy Bird case 展示 real-time control 的脆弱性:连续 frame 几乎相同,但早一点/晚一点 flap 就会决定 progress 是否增长。它解释了为什么 GameWorld-RT 需要单独报告,而不能只用 paused protocol 代替。
4. Experimental Setup (实验设置)
数据/环境规模:GameWorld 由 34 个 browser games 和 170 个 natural-language tasks 组成,游戏快照在 gameworld-dev/gameworld-games,benchmark catalog 在 gameworld-project/gameworld/catalog。每个任务绑定 target score、start score、evaluator_config、max_steps=100、pause_during_inference=true 和 continue_on_fail=true;released code 的 catalog/tasks 中 170/170 个任务都使用这些设置。
模型与接口:论文评测 13 个 base models,构成 18 个 model-interface pairs(8 个 CUA + 10 个 Generalist)。Proprietary/hosted 包括 Claude-Sonnet-4.6、Gemini-2.5-Computer-Use、Gemini-3-Flash-Preview、GLM-4.6V、GPT-5.2、Grok-4.1-Fast-Reasoning、Kimi-K2.5、OpenAI-Computer-Use、Qwen3-VL-Plus、Seed-1.8;open-source/open-weight 包括 Qwen3-VL-235B-A22B、Qwen3-VL-30B-A3B、UI-TARS-1.5-7B。
评测 protocol:默认 benchmark 在模型推理期间暂停游戏,确保 / 主要反映 decision quality;GameWorld-RT 则不暂停环境,用 sec/step、SR、PG 同时衡量延迟与实时交互能力。Human baseline 由两名 CS postgraduate students 完成:一个 novice,一个 expert。
成本与复现实验:附录估算对列出的 API models 完成 170 tasks 全量评测总成本为 815.19 USD,输入 token 统计包含 provider 支持的 cached input tokens;open-weight models 的推理成本未计入。released code 的 run_suite.py 默认 --max-parallel=5,suite runner 会把 YAML cases 展开成 repeat waves 并写出结果。
5. Experimental Results (实验结果)
主结果:最佳 Generalist agent 是 Gemini-3-Flash-Preview,整体 、;GPT-5.2 为 20.6 / 40.6,Claude-Sonnet-4.6 为 20.6 / 39.3,Seed-1.8 为 20.0 / 39.0。最佳 CUA 是 Seed-1.8,整体 20.0 / 39.8;Claude-Sonnet-4.6 CUA 为 19.4 / 38.3,Gemini-2.5-Computer-Use 为 16.5 / 36.1,OpenAI-Computer-Use 为 16.5 / 35.8。
人类差距:novice player 达到 55.3 / 64.1 ,expert player 达到 77.1 / 82.6。也就是说,最强 agent 的平均进度 41.9 明显低于 novice 的 64.1,成功率 21.2 也远低于 55.3;论文“当前 agent 能做 meaningful partial progress,但还不能可靠完成任务”的结论由这个 gap 支撑。
Benchmark robustness:Qwen repeated full-benchmark rerun 的整体 标准差都在低个位数以内:Qwen3-VL-30B-A3B CUA 为 30.9±1.1,Generalist 为 30.7±1.1;Qwen3-VL-235B-A22B CUA 为 30.4±0.7,Generalist 为 30.1±0.5。对应 分别为 12.7±1.2、12.5±1.3、13.8±0.7、13.6±1.4。
GameWorld-RT 与 memory ablation:real-time 设置下,Qwen3-VL-235B-A22B CUA 是 6.2 sec/step、17.1 SR、33.2 PG,30B CUA 是 2.4 sec/step、15.6 SR、33.0 PG;Generalist 235B 是 6.4 sec/step、16.8 SR、34.0 PG,30B 是 3.4 sec/step、15.6 SR、32.9 PG。memory rounds 从 0→1→2 时,235B Generalist 的 input tokens / sec/step / PG 为 1278 / 5.5 / 30.0,2171 / 6.8 / 30.1,3052 / 8.6 / 30.6;CUA 则为 1891 / 7.2 / 30.3,3771 / 10.1 / 29.0,5627 / 12.8 / 28.7。结论是:semantic trajectory 对 Generalist 有轻微帮助,但 CUA 长上下文更容易增加延迟和噪声。
Action validity 与 failure modes:整体 mean IAR 为 0.8%;多数强模型接近 0,但 GLM-4.6V Generalist 的 IAR=8.3%(7.6 NTC + 0.7 OOS),Qwen3-VL-30B-A3B Generalist 为 2.7%,UI-TARS-1.5-7B CUA 为 0.4%。论文把失败归为 instruction-following、perception、fine-grained action、long-horizon memory 四类;从 case studies 看,当前 agent 的主要瓶颈不是单一“看不懂画面”,而是感知、动作 grounding、延迟和历史目标维护的组合误差。