ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration
Paper: arXiv:2605.03042 Code: wanshuiyin/Auto-claude-code-research-in-sleep Code reference:
main@f8cff0a1(2026-05-14)
1. Motivation (研究动机)
现有 autonomous research agent 的关键问题不是“完全跑不起来”,而是论文称为 plausible unsupported success 的隐蔽失败:长链路 agent 可能写出看似合理的实验结论,但证据来源不完整、数字被误报、claim 从 executor 的叙事里被继承下来,后续读者或 reviewer 很难再还原每个结论对应的 raw evidence。
这篇报告要解决的具体问题是:怎样把 ML research 从 idea → experiment → paper → rebuttal 的长流程,拆成可恢复、可审计、可跨模型互相质疑的 research harness。作者认为单一模型长期执行 hard task 时会出现 lazy completion、hallucination 或 deceptive behavior;所以 harness 需要 persistent state、modular execution 和 independent assurance,而不是只靠同一模型的 self-refinement。
这个问题值得研究,因为 research automation 的错误代价高于普通 coding automation:一次幻觉 claim、一次错误 metric normalization、一次 phantom result 都可能进入论文正文。ARIS 的目标不是证明某个模型更强,而是把研究过程的上下文、artifact、claim ledger、review action item 和最终 manuscript 连接成一个有 provenance 的工作流,使自动化研究至少具备被人类追责和复查的结构。
2. Idea (核心思想)
核心洞察:把 autonomous research 看成 harness engineering 问题,而不是单个 super-agent 问题;让 executor 负责推进 artifact,让不同 model family 的 reviewer 负责独立质疑,并把每轮质疑转化为可执行 action items 和 evidence-to-claim audit。 ARIS 因此默认采用 cross-family executor/reviewer pattern:例如 Claude-family executor 搭配 GPT-family reviewer,或反向组合;Gemini、MiniMax、GLM、Kimi、DeepSeek 等通过 MCP / OpenAI-compatible bridge 接入。
关键创新有三层。第一层是 execution layer:65+ 个 Markdown-defined skills、MCP model bridges、persistent research wiki 和 deterministic figure generation。第二层是 orchestration layer:5 个 end-to-end workflows、effort presets 和 reviewer routing。第三层是 assurance layer:实验完整性审计、result-to-claim mapping、paper-claim audit、五遍 scientific editing、proof check 和 rendered PDF visual review。
与 The AI Scientist / AI Scientist-v2 相比,ARIS 的重点不是“从零生成一篇 paper”的单链路自动化,而是 workflow contract + independent assurance;与 Self-Refine / Reflexion 相比,它不让 generator 和 validator 共享同一 model family 的 inductive bias;与 AutoGen / MetaGPT / OpenHands 相比,它把研究任务里的 skill、wiki、claim ledger 和 audit gate 作为 domain-specific first-class objects,而不是通用 agent 框架上的一次 prompt 编排。
3. Method (方法)
3.1 Overall framework:research harness 的三层结构
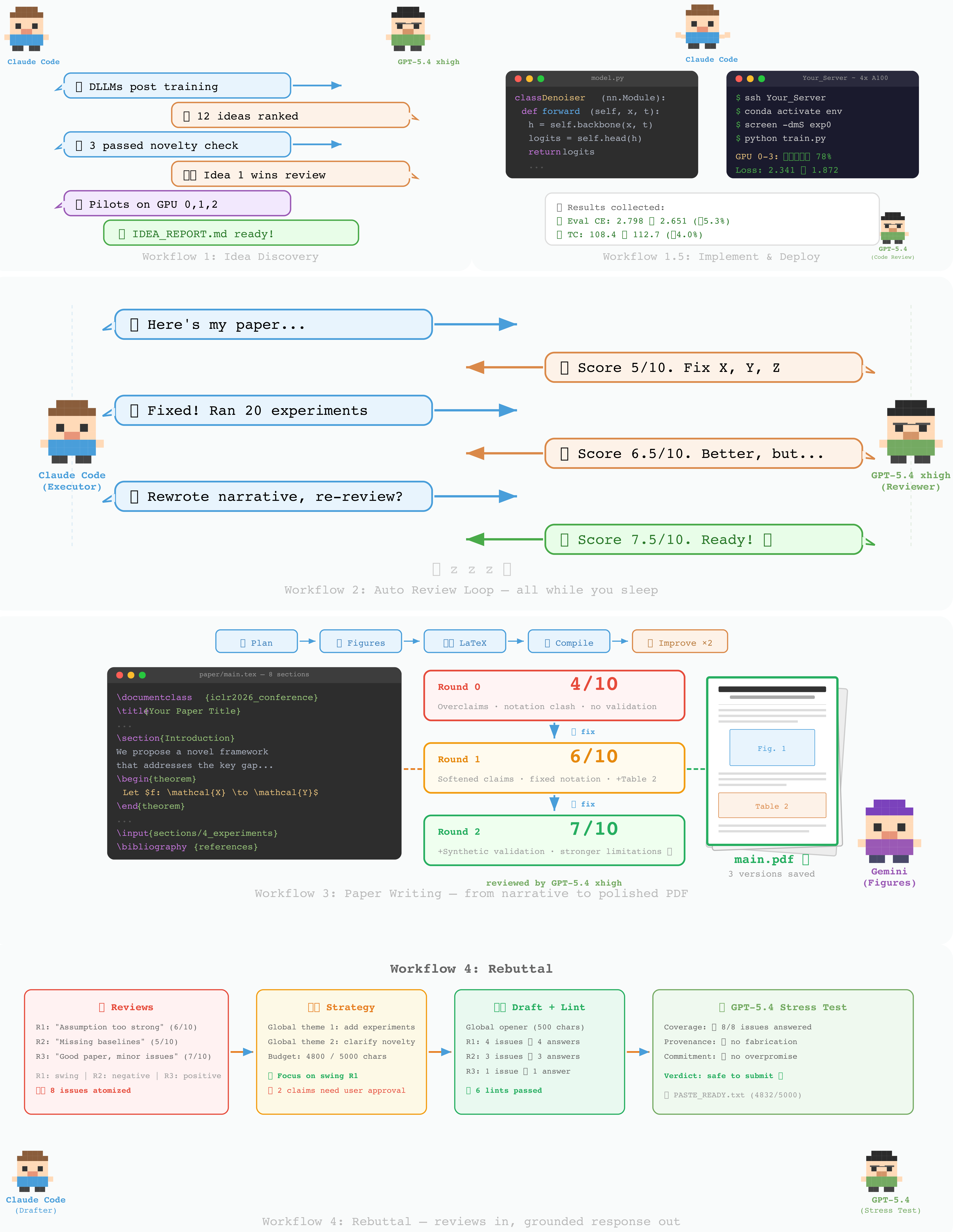
Figure 0 解读:封面图把 ARIS 的交互直觉画成 executor 与 reviewer 的长期协作:executor 生成/修改 artifact,reviewer 从独立视角提出 critique,系统把 critique 压缩成 action item、实验和文稿修改。它不是一个单模型 chain-of-thought 展示,而是在强调“生产”和“审计”应该被拆开。
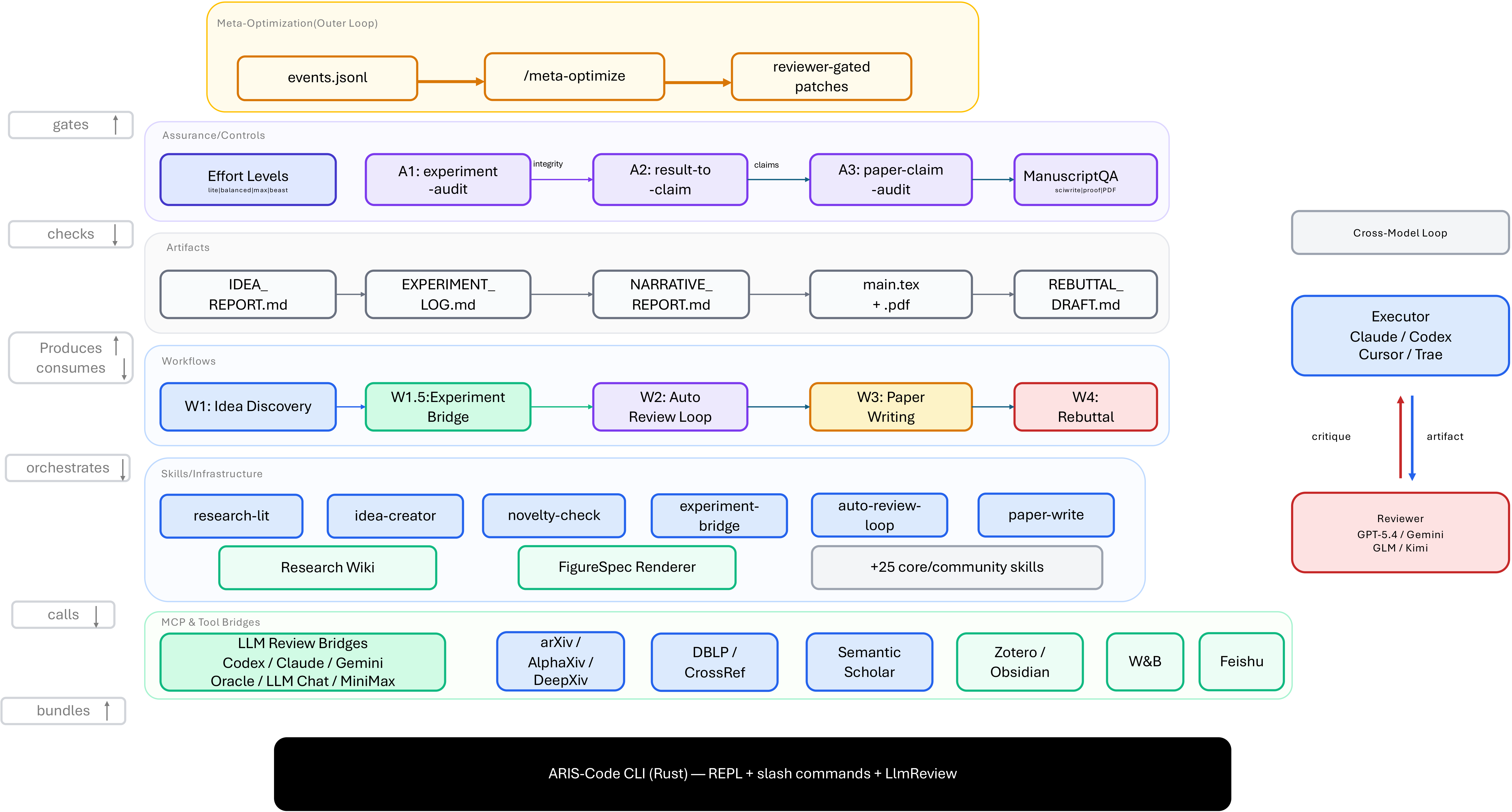
Figure 1 解读:系统拓扑把 ARIS 分成六组组件:Meta-Optimization 外环、Assurance layer、Artifacts、Workflows、Skills、MCP & Tool Bridges。关键关系是:artifact 由 workflows 生产,被 assurance 检查;workflows 编排 skills;skills 调用 MCP/tool bridges;meta-optimization 只在 reviewer gate 后改 harness 本身。右侧 executor/reviewer 来自不同模型家族,是整套设计的默认安全假设。
这三层对应论文开头提出的三个 bottleneck:persistent state 由 per-project research wiki 和 versionable artifact contracts 解决;modular execution 由单文件 SKILL.md 与 workflow chaining 解决;independent assurance 由 cross-family reviewer、audit cascade 和 manuscript checks 解决。
3.2 五个 workflow:把长链路研究拆成可审计 artifact contracts
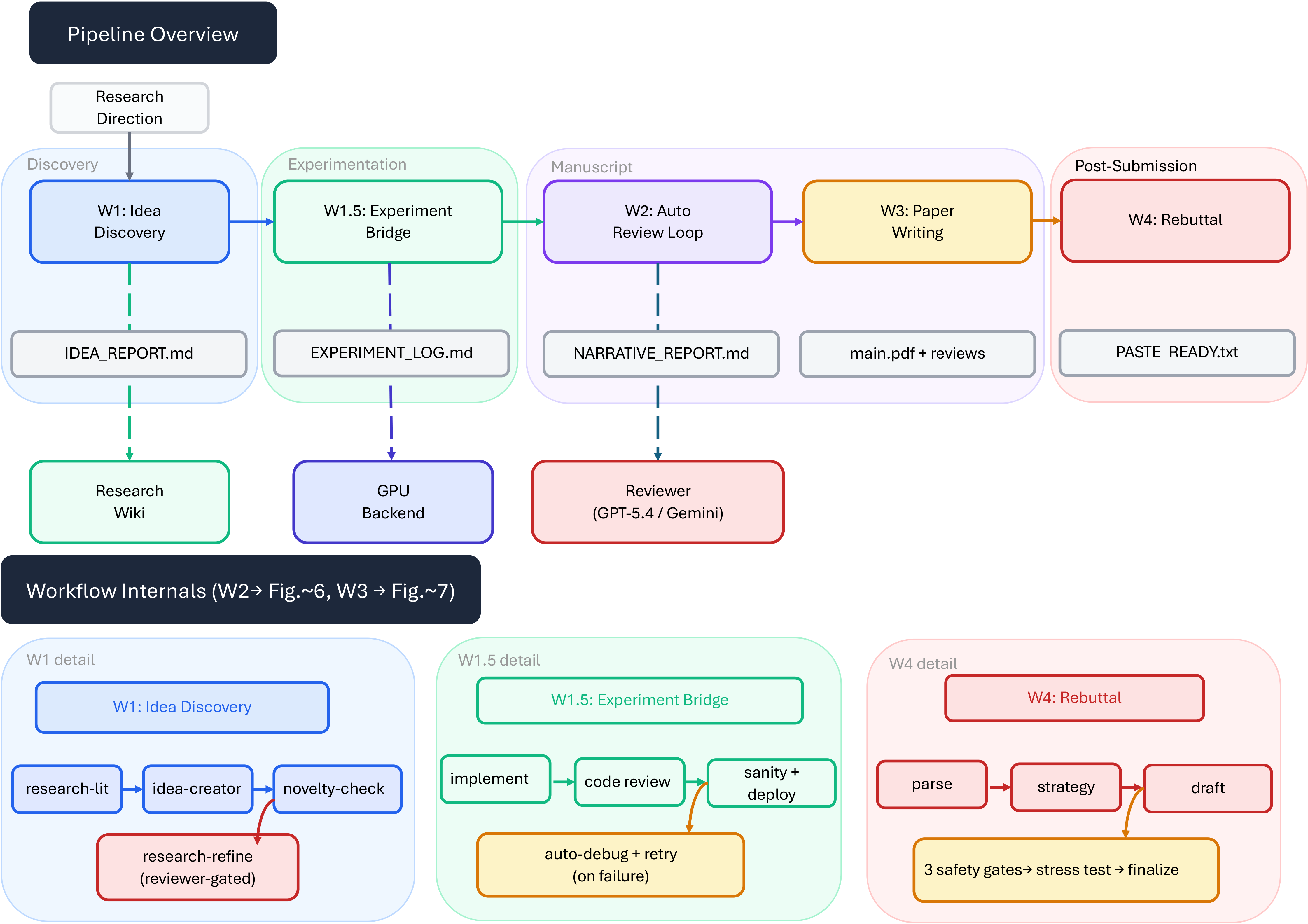
Figure 5 解读:ARIS workflow library 覆盖四个阶段:Discovery、Experimentation、Manuscript、Post-Submission。W1 idea discovery 输出 IDEA_REPORT.md,W1.5 experiment bridge 输出 EXPERIMENT_LOG.md,W2 auto-review 把 draft/results 改成 improved paper,W3 paper writing 从 narrative report 生成 compiled PDF,W4 rebuttal 产出 paste-ready response。虚线表示 reviewer feedback、GPU-triggered evidence collection 和 wiki memory 会跨 workflow 回流。
论文把 workflow 明确写成 plain-text artifact contract,而不是内存里的 agent state。这样设计的实际好处是:任何阶段都可以从保存的 Markdown/JSON/LaTeX 文件恢复;reviewer 可以读取文件路径而不是 executor summary;某个 skill 失败时可以替换局部组件,而不必重启整个 autonomous pipeline。

Figure 8 解读:Workflow 1 由 research-lit → idea-creator → novelty-check → research-review 组成,目标是从研究方向生成 ranked idea report。它不是只 brainstorm,而是把 literature survey、novelty verification 和 external critique 绑定为一个早期 gate,避免系统一开始就围绕已知或弱 idea 做昂贵实验。
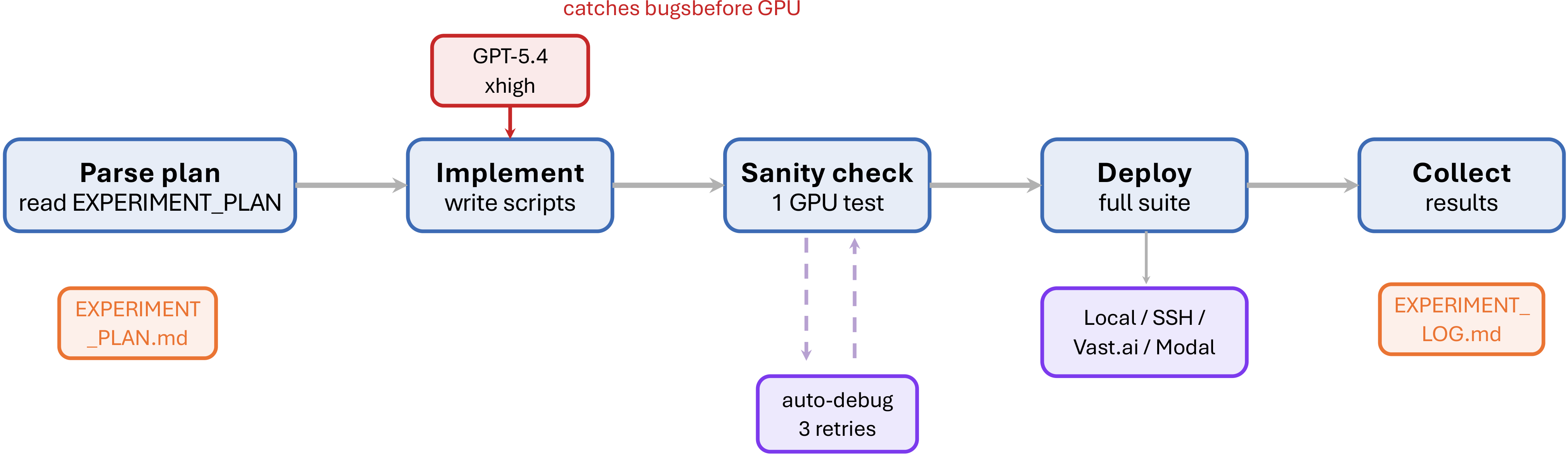
Figure 9 解读:Workflow 1.5 将 experiment plan 变成可运行代码:读取 EXPERIMENT_PLAN.md,实现 script,经 GPT-5.4/code-review 类 reviewer 检查,再做 1-GPU sanity check,最后部署并收集结果。这个桥接层重要,因为它把“想法看起来不错”与“实验确实能跑且有初步证据”分开。
3.3 Cross-model adversarial collaboration:critique-to-action loop
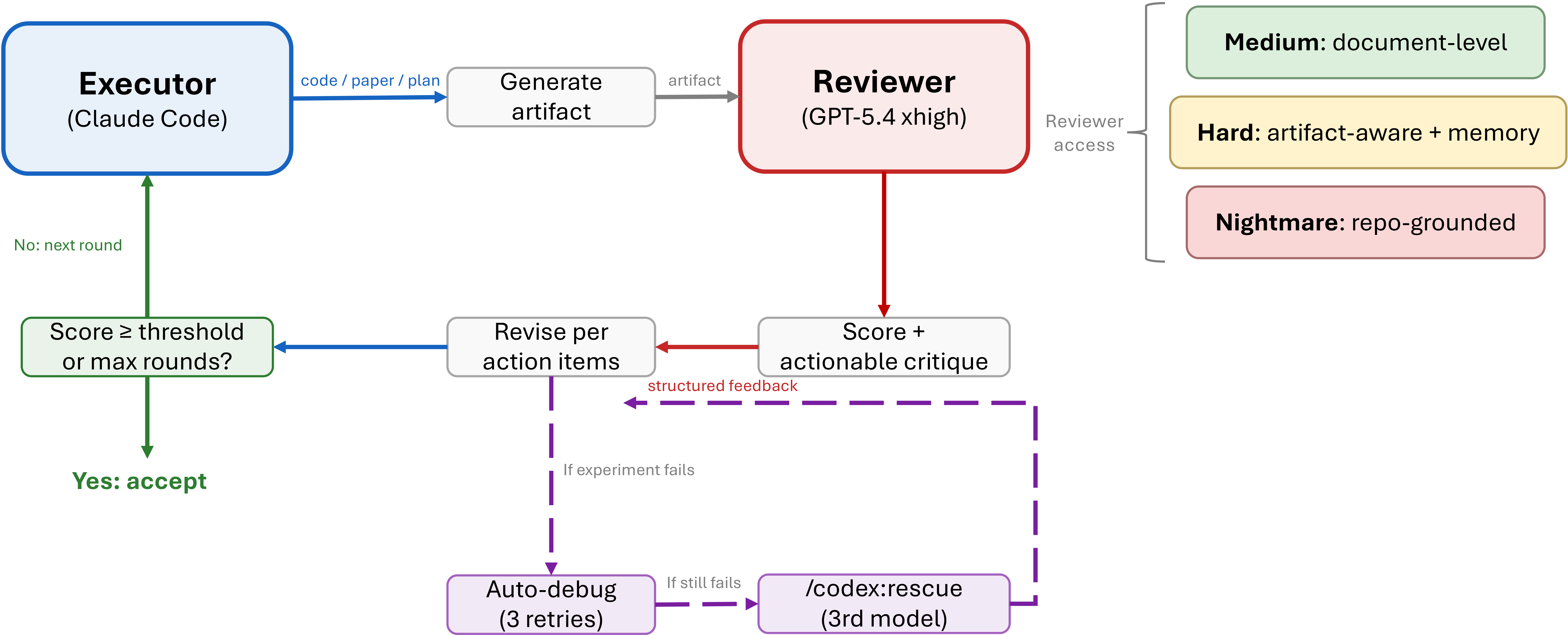
Figure 2 解读:executor 生成 artifact,reviewer 给出 score 和 actionable critique;executor 修复后进入 convergence check。默认停止条件是 reviewer score 超过阈值或达到最大轮数:论文写默认 threshold 为 6/10、max rounds 为 4;当前 released code 的 skills/auto-review-loop/SKILL.md 也保留 MAX_ROUNDS = 4 和 POSITIVE_THRESHOLD: score >= 6/10。
这里的“adversarial”不是多 agent 辩论的炫技,而是一个工程防线:executor 只提供 file paths 和 review objective;reviewer 直接读取 referenced artifacts,尽量不评估 executor 的摘要,以减少 shared framing。reviewer 有两个配置轴:access scope(document-only / artifact-augmented / repository-level)和 context policy(fresh / cross-round)。fresh reviewer 用于防 confirmation bias;cross-round reviewer 用于验证前轮问题是否真的修复。
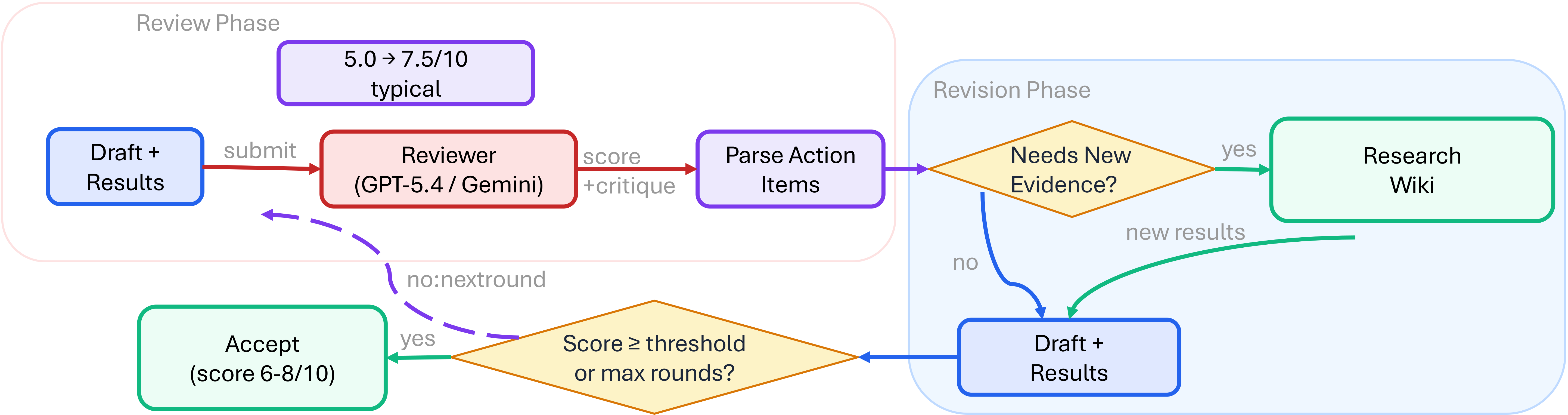
Figure 6 解读:auto-review loop 的执行顺序是 draft/results → reviewer score & weakness → parse action items → revise paper or run new evidence → accept/retry。图中出现 research wiki 和 GPU backend,说明 reviewer 不只是改文字,还可以要求补实验;若失败,系统进入 auto-debug retry 或 independent rescue model。
3.4 Assurance stack:从实验完整性到正文 claim 的三段审计
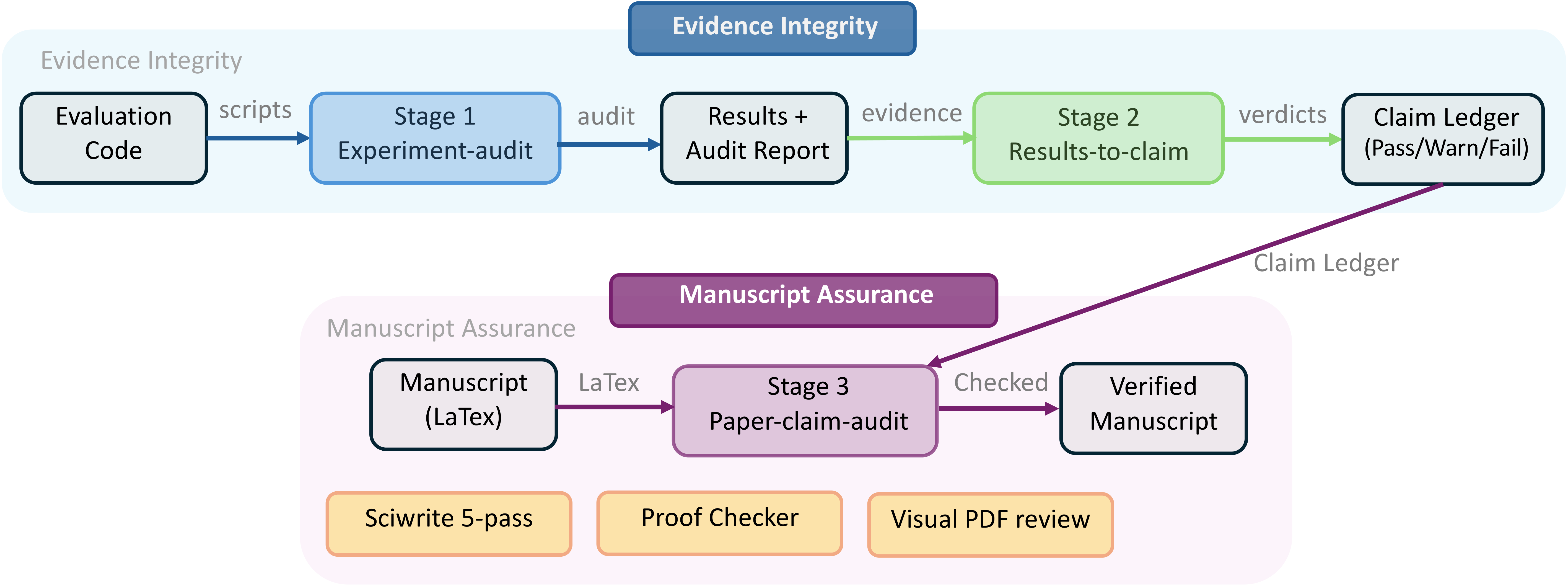
Figure 3 解读:Evidence-to-Claim Audit Cascade 有三段。Stage 1 experiment-audit 检查 evaluation code / result files,重点抓 fake ground truth、self-normalized score、phantom result、dead-code metric、scope inflation。Stage 2 result-to-claim 把 raw results 归一成 supported / partial / invalidated claim verdict。Stage 3 paper-claim-audit 让 zero-context reviewer 对照 manuscript、claim ledger 和 raw files,检查 number mismatch、config mismatch、rounding、best-seed cherry-picking 等问题。下方 Manuscript Assurance 还包括五遍编辑、proof checker、visual PDF review 和 citation audit。
直觉上,ARIS 没有假设 reviewer 一定比 executor 聪明;它假设 不同位置的错误应该由不同证据接口捕获。code-level integrity、evidence interpretation、manuscript reporting fidelity 分别审计,可以避免“实验其实有问题但 claim mapping 仍然乐观”或“结果没问题但论文数字写错”的跨层污染。
论文公式与 released code 实现差异:本文几乎没有提出新的数学 loss 或 differentiable objective;核心是 workflow contract 与 audit status。需要注意的是,论文文本多处以 GPT-5.4 reviewer 为例,而当前 released code main@f8cff0a1 的若干 skill(如 skills/auto-review-loop/SKILL.md、skills/paper-write/SKILL.md)默认 reviewer model 已更新为 gpt-5.5;本笔记的源码映射以当前 commit 为准,论文实验/部署数字仍按 paper 原文记录。
3.5 Research wiki:把失败 idea 和 claim ledger 留在项目记忆里
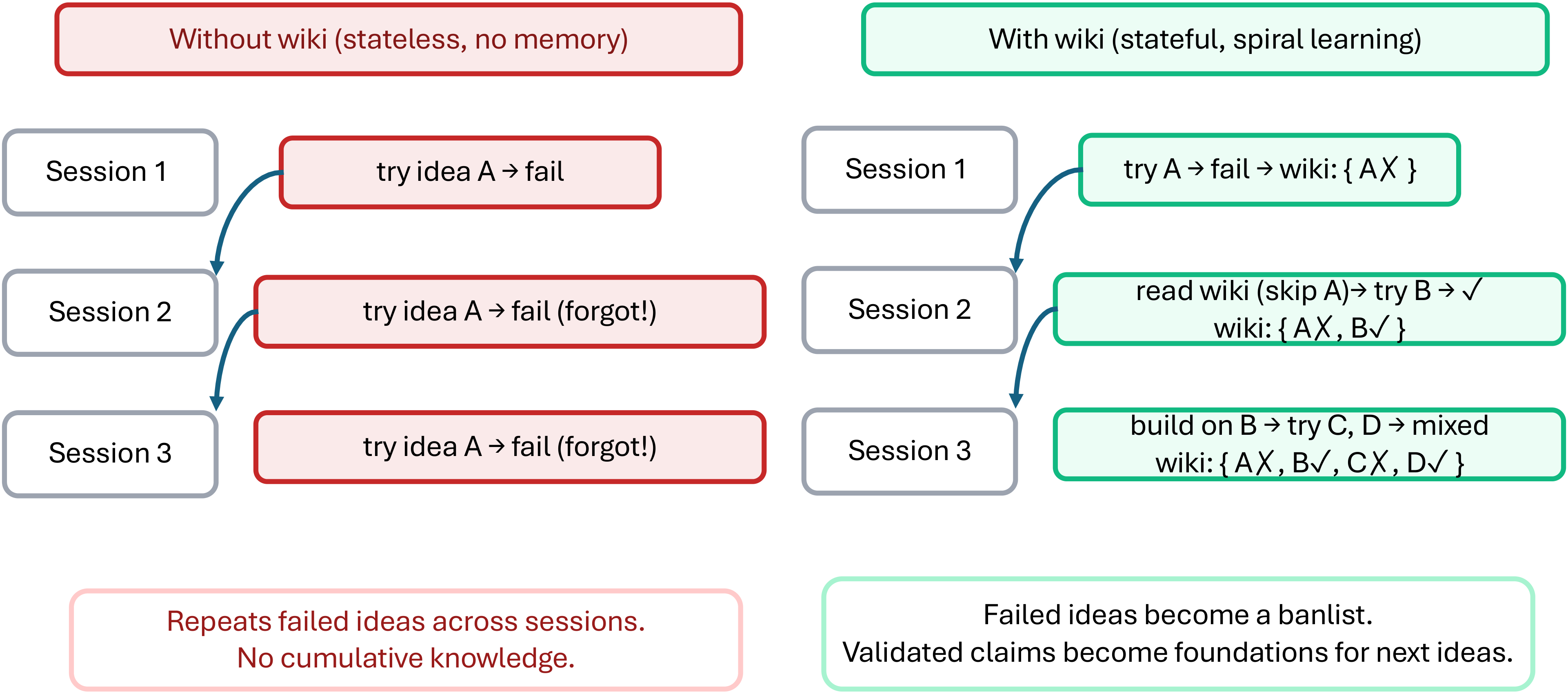
Figure 4 解读:左侧 without wiki 每次 session 都忘记上次失败 idea,因此反复尝试 A;右侧 with wiki 记录 Session 1 的失败,Session 2 跳过 A 尝试 B,Session 3 基于 B 继续探索 C/D。论文把 wiki 设计成四类 entity(papers、ideas、experiments、claims)和八类 typed relationships(extends、contradicts、addresses_gap、inspired_by、tested_by、supports、invalidates、supersedes),本质是给长周期研究加一个轻量知识图谱。
从源码看,tools/research_wiki.py 是该机制的 canonical helper:它提供 init_wiki、add_edge、rebuild_query_pack、fetch_arxiv_metadata、ingest_paper、sync_papers、rebuild_index 等函数;skills/research-wiki/SKILL.md 定义四类 entity、目录结构和 ingest/query/update/lint/stats 子命令。query_pack.md 默认压缩到 8,000 characters,说明 wiki 不是把所有历史塞回 prompt,而是显式做 context budgeting。
3.6 Paper writing 和 rebuttal:把审计接入最终 manuscript
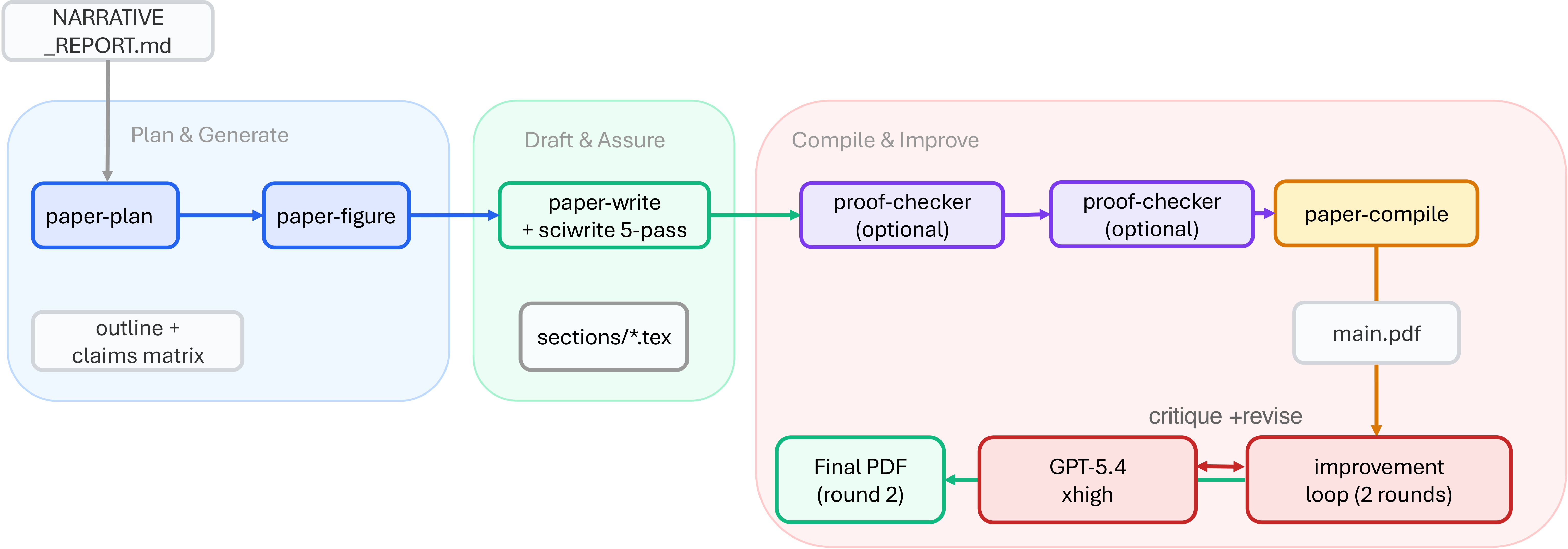
Figure 7 解读:Workflow 3 从 NARRATIVE_REPORT.md 开始,经 paper-plan、paper-figure、paper-write、可选 proof-checker、paper-claim-audit、paper-compile,再进入 GPT-5.4/xhigh visual review 和 auto-paper-improvement-loop。它的关键不是自动写 LaTeX,而是 claims-evidence matrix、citation lookup、claim audit 和 compiled-PDF visual review 会在写作过程中持续约束正文。

Figure 10 解读:Workflow 4 把 rebuttal 拆为 parse reviews、atomic concerns、strategy plan、draft rebuttal、safety checks、stress test、finalize response,并带有 missing-evidence triage 和多轮 stress test。对 agentic research 来说,rebuttal 是另一个容易 overclaim 的阶段,所以 ARIS 继续使用安全 gate,而不是只把 reviewer comments 交给一个写作模型。
3.7 源码映射与 PyTorch-style pseudocode
Code reference:
main@f8cff0a1(2026-05-14) — pseudocode and mapping based on this commit
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Full lifecycle orchestration | skills/research-pipeline/SKILL.md | Stage 1–6 pipeline; AUTO_PROCEED, AUTO_WRITE, REVIEWER_DIFFICULTY |
| Workflow 1 idea discovery | skills/idea-discovery/SKILL.md | research-lit → idea-creator → novelty-check → research-review |
| Workflow 1.5 experiment bridge | skills/experiment-bridge/SKILL.md | plan parsing, code implementation, code review, sanity check, deploy |
| Workflow 2 auto review | skills/auto-review-loop/SKILL.md | MAX_ROUNDS=4, POSITIVE_THRESHOLD >= 6/10, Phase A–E loop |
| Workflow 3 paper writing | skills/paper-writing/SKILL.md | paper-plan → paper-figure → paper-write → paper-compile → auto-paper-improvement-loop |
| Evidence integrity audit | skills/experiment-audit/SKILL.md | artifact collection; reviewer integrity verdict; EXPERIMENT_AUDIT.md |
| Result-to-claim gate | skills/result-to-claim/SKILL.md | supported / partial / invalidated verdict; wiki update hook |
| Paper claim audit | skills/paper-claim-audit/SKILL.md | zero-context fresh reviewer; number/config/scope checks |
| Research wiki helper | tools/research_wiki.py | ingest_paper, add_edge, rebuild_query_pack, rebuild_index |
| Audit verifier | tools/verify_paper_audits.sh | external exit-code gate for audit freshness / verdicts |
| Figure renderer | tools/figure_renderer.py | JSON FigureSpec → deterministic SVG |
| Model/tool bridges | mcp-servers/*/server.py, tools/*_fetch.py | Codex/Gemini/Claude/MiniMax/llm-chat, arXiv/OpenAlex/Semantic Scholar |
from dataclasses import dataclass
from typing import Literal
Verdict = Literal["supported", "partial", "invalidated"]
AuditStatus = Literal["pass", "warn", "fail"]
@dataclass
class Artifact:
path: str
kind: str
claims: list[str]
@dataclass
class Review:
score: float
action_items: list[str]
critical_unresolved: bool
def cross_model_review_loop(executor, reviewer, artifact: Artifact,
max_rounds: int = 4,
positive_threshold: float = 6.0) -> Artifact:
"""Source-aligned sketch of skills/auto-review-loop/SKILL.md."""
review_log = []
for round_idx in range(max_rounds):
# Reviewer reads artifact paths directly; executor does not summarize evidence.
review: Review = reviewer.review(
paths=[artifact.path],
objective="score, weaknesses, actionable fixes",
fresh_context=(round_idx == 0),
)
review_log.append(review)
if review.score >= positive_threshold and not review.critical_unresolved:
break
fixes, experiments = executor.parse_action_items(review.action_items)
if experiments:
results = executor.run_gpu_experiments(experiments)
artifact = executor.attach_evidence(artifact, results)
artifact = executor.revise_only_affected_sections(artifact, fixes)
executor.write_review_stage_log(review_log)
return artifactdef evidence_to_claim_audit(evaluation_code, result_files, manuscript, reviewer):
"""Source-aligned sketch of experiment-audit → result-to-claim → paper-claim-audit."""
integrity = reviewer.audit_experiment_integrity(
code=evaluation_code,
files=result_files,
checks=[
"ground_truth_provenance",
"score_normalization",
"result_file_existence",
"dead_code_or_unused_metric",
"scope_assessment",
],
)
claim_ledger = []
for claim in extract_candidate_claims(result_files):
verdict: Verdict = reviewer.judge_claim_support(
claim=claim,
evidence=result_files,
integrity_status=integrity.status,
)
claim_ledger.append({"claim": claim, "verdict": verdict})
paper_audit = reviewer.fresh_thread().verify_manuscript_claims(
manuscript=manuscript,
claim_ledger=claim_ledger,
raw_files=result_files,
checks=["number_mismatch", "config_mismatch", "missing_evidence", "scope_overclaim"],
)
return integrity, claim_ledger, paper_auditdef research_wiki_ingest_and_query(wiki, paper, idea, experiment, claims):
"""Source-aligned sketch of skills/research-wiki/SKILL.md and tools/research_wiki.py."""
paper_node = wiki.ingest_paper(paper.title, arxiv_id=paper.arxiv_id, tags=paper.tags)
idea_node = wiki.write_idea(idea, status="active")
exp_node = wiki.write_experiment(experiment, status=experiment.status)
wiki.add_edge(idea_node, paper_node, edge_type="inspired_by")
wiki.add_edge(idea_node, exp_node, edge_type="tested_by")
for claim in claims:
claim_node = wiki.write_claim(claim.text, status=claim.status)
wiki.add_edge(exp_node, claim_node, edge_type="supports" if claim.supported else "invalidates")
query_pack = wiki.rebuild_query_pack(max_chars=8000)
return query_packdef full_research_pipeline(direction, auto_write: bool = False):
"""Source-aligned sketch of skills/research-pipeline/SKILL.md."""
idea_report = idea_discovery(direction) # W1
experiment_plan = refine_method_and_plan(idea_report)
results = experiment_bridge(experiment_plan) # W1.5
improved = cross_model_review_loop(
executor=ClaudeLikeExecutor(),
reviewer=GPTFamilyReviewer(),
artifact=Artifact(path="paper/main.tex", kind="manuscript", claims=[]),
) # W2
narrative = write_narrative_report(improved, results)
if auto_write:
pdf = paper_writing_pipeline(narrative) # W3
return rebuttal_pipeline(pdf) # W4, only after reviews arrive
return narrative4. Experimental Setup (实验设置)
这篇报告没有传统 ML benchmark 的训练集/验证集;它是系统报告和 deployment evidence。论文明确说 observational outcomes 不能因果归因于 ARIS。可复查的“实验/评估对象”主要有三类:当前实现 footprint、一次 overnight auto-review trajectory、以及与 autonomous research / agent framework 的 feature comparison。
Datasets / evidence sources:论文未详细说明 controlled benchmark dataset;使用的是 repo/skill library 的实现状态、April 2026 deployment footprint、一个约 8 小时的真实 workflow run,以及 cited systems 的公开文档/论文特性对照。
Baselines:主对比对象包括 The AI Scientist、AI Scientist-v2、Agent Laboratory、data-to-paper、AutoGen、MetaGPT、OpenHands。比较维度是 cross-family policy、adversarial review、composable skills、end-to-end research workflows、assurance stack、cross-platform portability。
Evaluation metrics:不是 accuracy/F1,而是系统性指标:feature presence、workflow coverage、review score progression、GPU experiment count、unsupported claim pruning、deployment footprint。论文对 ARIS 的 feature comparison 结论是:cross-family policy 为 default;adversarial review、composable skills、E2E research workflow、assurance stack、cross-platform portability 均为 yes。
Config / implementation numbers:来自论文表格与当前源码。论文表 1 写 v0.4 / April 2026 有 65+ Markdown skill files、5 个 end-to-end workflows、6 个 MCP bridges、3 个 tested executors + 3 个 adapted、4 个 effort presets(lite / balanced / max / beast)。当前 repo main@f8cff0a1 的 skills/auto-review-loop/SKILL.md 写 MAX_ROUNDS=4、POSITIVE_THRESHOLD: score >= 6/10;skills/research-pipeline/SKILL.md 暴露 AUTO_PROCEED、AUTO_WRITE、REVIEWER_DIFFICULTY 等 workflow-level defaults;skills/paper-writing/SKILL.md 在 max/beast 或 submission assurance 下会调用 tools/verify_paper_audits.sh 作为最终 audit verifier。
5. Experimental Results (实验结果)
Implementation footprint:论文报告当前 implementation footprint 为:65+ Markdown-defined skills;5 个 end-to-end workflows 加 full pipeline command;6 个 MCP bridges(Codex、Oracle、Claude、Gemini、MiniMax、llm-chat);3 个 tested executors(Claude Code、Codex CLI、Cursor)和 3 个 adapted executors;3-stage audit cascade + manuscript quality;per-project research wiki 有 4 类 entity;effort presets 为 lite / balanced / max / beast;skills 本身无依赖,CLI 为 single binary。
Deployment footprint:截至 April 2026,论文报告 executor platforms 为 3 tested + 3 adapted(6 total);reviewer models 为 6+(GPT、Gemini、GLM、MiniMax、Kimi、DeepSeek);GPU backends 为 4(local、SSH、Vast.ai、Modal);venue templates 为 9 families;free-tier API access 使用 ModelScope;community contributions 为 30+ skills,覆盖 robotics、hardware、communications、math。
Overnight trajectory:一个约 8 小时的实际运行完成 4 轮 review–revise,将 internal reviewer score 从 5.0 提升到 7.5/10,启动 20+ GPU experiments,并删除了 available evidence 不支持的 claims。这个结果只证明 harness 能把 claim pruning 和 review-driven revision 操作化;论文明确说它不能证明 cross-family review 因果上优于 same-family review,也不能证明两个 reviewer 是最优 committee size。
Feature comparison:ARIS 相比 The AI Scientist / AI Scientist-v2 / Agent Laboratory / data-to-paper / AutoGen / MetaGPT / OpenHands 的最强点是完整性而非单项能力:baseline 普遍没有 cross-family policy,adversarial review 和 assurance stack 多为 partial 或 none;ARIS 在 composable skills、E2E research workflow、assurance stack 和 cross-platform portability 上都标为 yes。不过这张表是基于截至 April 2026 的文档/论文公开特性,不是性能 benchmark。
Limitations:作者列出五类限制:不能保证 correctness / novelty / scientific soundness;audit cascade 不是 formal verification;review loop 可能放大 reviewer bias 并 overfit reviewer preference;humans 仍需提供方向、验证证据并决定是否投稿;repository-level review 可能把敏感代码发送给外部 LLM API,local-only reviewer routing 仍是 planned but not yet implemented。额外重要限制是缺少 controlled evaluation,未来需要 compute-matched comparisons、local reviewer models 和 researcher productivity user studies。